Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Azure HDInsight is a managed cloud-based service for big data analytics that helps organizations process large amounts data. This tutorial shows how to connect to OneLake with a Jupyter notebook from an Azure HDInsight cluster.
Using Azure HDInsight
To connect to OneLake with a Jupyter notebook from an HDInsight cluster:
Create an HDInsight (HDI) Apache Spark cluster. Follow these instructions: Set up clusters in HDInsight.
While providing cluster information, remember your Cluster login Username and Password, as you need them to access the cluster later.
Create a user assigned managed identity (UAMI): Create for Azure HDInsight - UAMI and choose it as the identity in the Storage screen.
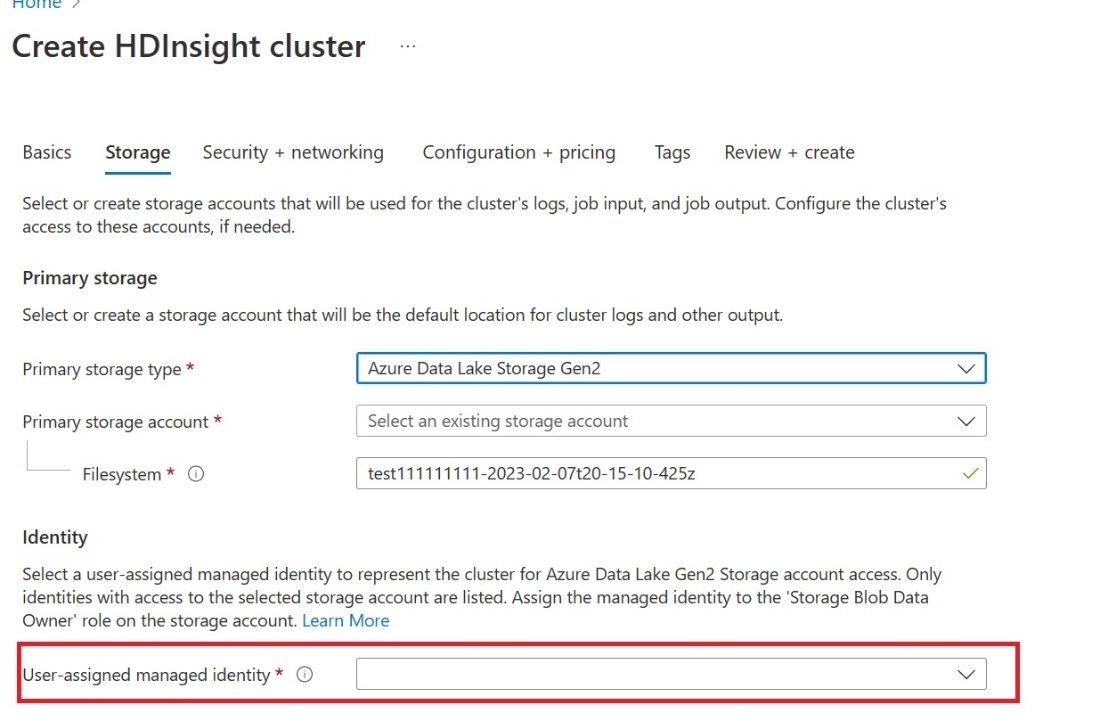
Give this UAMI access to the Fabric workspace that contains your items. For help deciding what role is best, see Workspace roles.
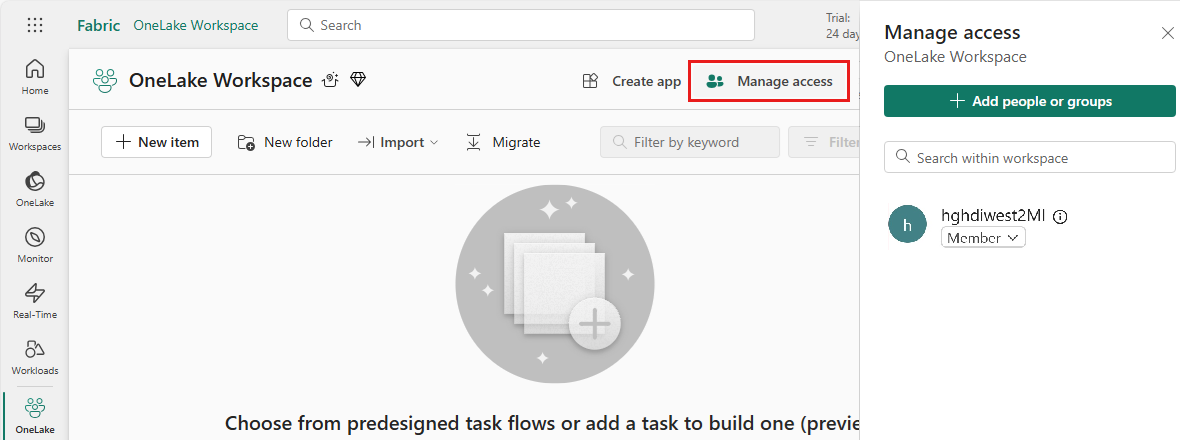
Navigate to your lakehouse and find the name for your workspace and lakehouse. You can find them in the URL of your lakehouse or the Properties pane for a file.
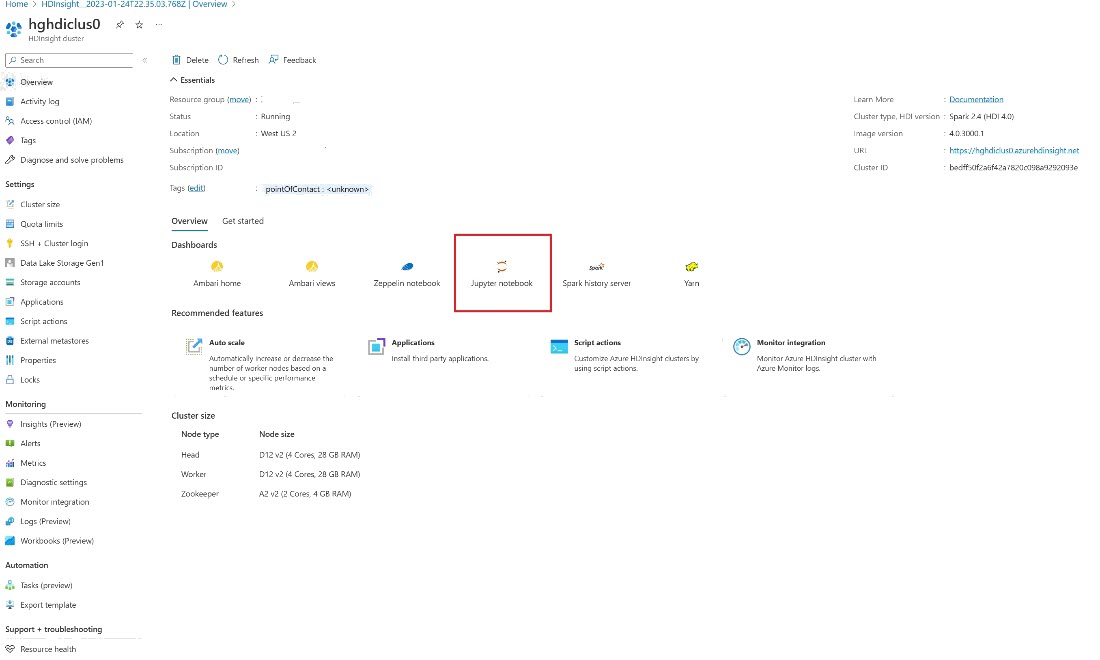
In the Azure portal, look for your cluster and select the notebook.
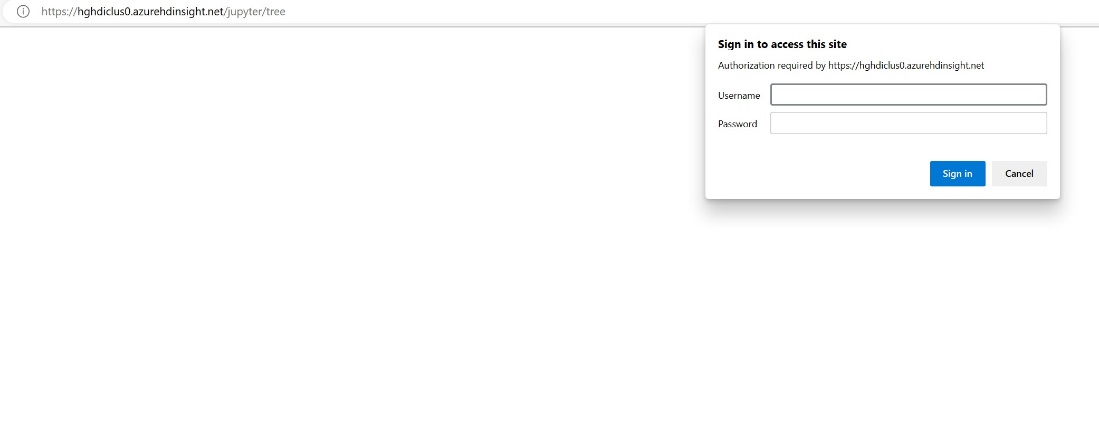
Enter the credential information you provided while creating the cluster.
Create a new Apache Spark notebook.
Copy the workspace and lakehouse names into your notebook and build the OneLake URL for your lakehouse. Now you can read any file from this file path.
fp = 'abfss://' + 'Workspace Name' + '@onelake.dfs.fabric.microsoft.com/' + 'Lakehouse Name' + '/Files/' df = spark.read.format("csv").option("header", "true").load(fp + "test1.csv") df.show()Try writing some data into the lakehouse.
writecsvdf = df.write.format("csv").save(fp + "out.csv")Test that your data was successfully written by checking your lakehouse or by reading your newly loaded file.




You can now read and write data in OneLake using your Jupyter notebook in an HDI Spark cluster.