Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This article introduces medallion lake architecture and describes how you can implement the design pattern in Microsoft Fabric. It's targeted at multiple audiences:
- Data engineers: Technical staff who design, build, and maintain infrastructures and systems that enable their organization to collect, store, process, and analyze large volumes of data.
- Center of Excellence, IT, and BI teams: The teams that are responsible for overseeing analytics throughout the organization.
- Fabric administrators: The administrators who are responsible for overseeing Fabric in the organization.
The medallion lakehouse architecture, commonly known as medallion architecture, is a design pattern that's used by organizations to logically organize data in a lakehouse. It's the recommended design approach for Fabric. Since OneLake is the data lake for Fabric, medallion architecture is implemented by creating lakehouses in OneLake.
Medallion architecture comprises three distinct layers, also called zones. The three medallion layers are: bronze (raw data), silver (validated data), and gold (enriched data). Each layer indicates the quality of data stored in the lakehouse, with higher levels representing higher quality. This multi-layered approach helps you to build a single source of truth for enterprise data products.
Importantly, medallion architecture guarantees atomicity, consistency, isolation, and durability (ACID) as data progresses through the layers. Your data starts in its raw form, then a series of validations and transformations prepares the data to optimize it for efficient analytics while also maintaining the original copies as a source of truth.
For more information, see What is the medallion lakehouse architecture?.
Medallion architecture in Fabric
The goal of medallion architecture is to incrementally and progressively improve the structure and quality of data as it progresses through each stage.
Medallion architecture consists of three distinct layers (or zones).
- Bronze: Also called the raw zone, this first layer stores source data in its original format, including unstructured, semi-structured, or structured data types. The data in this layer is typically append-only and immutable. By preserving the raw data in the bronze layer, you maintain a source of truth and enable reprocessing and auditing in the future.
- Silver: Also called the enriched zone, this layer stores data sourced from the bronze layer. The data is cleansed and standardized, and now it's structured as tables (rows and columns). It might also be integrated with other data to provide an enterprise view of all business entities, like customers, products, and more.
- Gold: Also called the curated zone, this final layer stores data sourced from the silver layer. The data is refined to meet specific downstream business and analytics requirements. Tables typically conform to star schema design, which supports the development of data models that are optimized for performance and usability.
Each zone should be separated into its own lakehouse or data warehouse in OneLake, with data moving between the zones as it's transformed and refined.
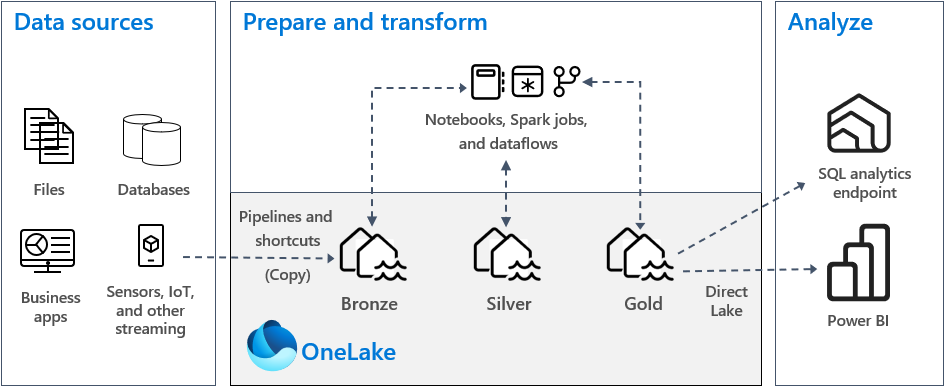
In a typical medallion architecture implementation in Fabric, the bronze zone stores the data in the same format as the data source. When the data source is a relational database, Delta tables are a good choice. The silver and gold zones should contain Delta tables.
Tip
To learn how to create a lakehouse, work through the Lakehouse end-to-end scenario tutorial.
OneLake and lakehouse in Fabric
The basis of a modern data warehouse is a data lake. Microsoft OneLake is a single, unified, logical data lake for your entire organization. It comes automatically provisioned with every Fabric tenant, and it's the single location for all your analytics data.
You can use OneLake to:
- Remove silos and reduce management effort. All organizational data is stored, managed, and secured within one data lake resource.
- Reduce data movement and duplication. The objective of OneLake is to store only one copy of data. Fewer copies of data results in fewer data movement processes, and that leads to efficiency gains and reduction in complexity. Use shortcuts to reference data stored in other locations, rather than copying it to OneLake.
- Use with multiple analytical engines. The data in OneLake is stored in an open format. That way, the data can be queried by various analytical engines, including Analysis Services (used by Power BI), T-SQL, and Apache Spark. Other non-Fabric applications can use APIs and SDKs to access OneLake as well.
To store data in OneLake, you create a lakehouse in Fabric. A lakehouse is a data architecture platform for storing, managing, and analyzing structured and unstructured data in a single location. It can scale to large data volumes of all file types and sizes, and because the data is stored in a single location, it can be shared and reused across the organization.
Each lakehouse has a built-in SQL analytics endpoint that unlocks data warehouse capabilities without the need to move data. That means you can query your data in the lakehouse by using SQL queries and without any special setup.
For more information, see What is a lakehouse in Microsoft Fabric?.
Tables and files
When you create a lakehouse in OneLake, two physical storage locations are provisioned automatically:
- Tables is a managed area for storing tables of all formats in Apache Spark (CSV, Parquet, or Delta). All tables, whether automatically or explicitly created, are recognized as tables in the lakehouse. Any Delta tables, which are Parquet data files with a file-based transaction log, are recognized as tables as well.
- Files is an unmanaged area for storing data in any file format. Any Delta files stored in this area aren't automatically recognized as tables. If you want to create a table over a Delta Lake folder in the unmanaged area, create a shortcut or an external table with a location that points to the unmanaged folder that contains the Delta Lake files in Apache Spark.
The main distinction between the managed area (tables) and the unmanaged area (files) is the automatic table discovery and registration process. This process runs over any folder created in the managed area only, but not in the unmanaged area.
In the bronze zone, you store data in its original format, which might be either tables or files. If the source data is from OneLake, Azure Data Lake Store Gen2 (ADLS Gen2), Amazon S3, or Google, create a shortcut in the bronze zone instead of copying the data across.
In the silver and gold zones, you typically store data in Delta tables. However, you can also store data in Parquet or CSV files. If you do that, you must explicitly create a shortcut or an external table with a location that points to the unmanaged folder that contains the Delta Lake files in Apache Spark.
In Microsoft Fabric, the Lakehouse explorer provides a unified graphical representation of the whole Lakehouse for users to navigate, access, and update their data.
For more information about automatic table discovery, see Automatic table discovery and registration.
Delta Lake storage
Delta Lake is an optimized storage layer that provides the foundation for storing data and tables. It supports ACID transactions for big data workloads, and for this reason it's the default storage format in a Fabric lakehouse.
Delta Lake delivers reliability, security, and performance in the lakehouse for both streaming and batch operations. Internally, it stores data in Parquet file format, however, it also maintains transaction logs and statistics that provide features and performance improvement over the standard Parquet format.
Delta Lake format delivers the following benefits compared to generic file formats:
- Support for ACID properties, especially durability to prevent data corruption.
- Faster read queries.
- Increased data freshness.
- Support for both batch and streaming workloads.
- Support for data rollback by using Delta Lake time travel.
- Enhanced regulatory compliance and audit by using Delta Lake table history.
Fabric standardizes storage file format with Delta Lake. By default, every workload engine in Fabric creates Delta tables when you write data to a new table. For more information, see Lakehouse and Delta Lake tables.
Deployment model
To implement medallion architecture in Fabric, you can either use lakehouses (one for each zone), a data warehouse, or combination of both. Your decision should be based on your preference and the expertise of your team. With Fabric, you can use different analytic engines that work on the one copy of your data in OneLake.
Here are two patterns to consider:
- Pattern 1: Create each zone as a lakehouse. In this case, business users access data by using the SQL analytics endpoint.
- Pattern 2: Create the bronze and silver zones as lakehouses, and the gold zone as a data warehouse. In this case, business users access data by using the data warehouse endpoint.
While you can create all lakehouses in a single Fabric workspace, we recommend that you create each lakehouse in its own, separate workspace. This approach provides you with more control and better governance at the zone level.
For the bronze zone, we recommend that you store the data in its original format, or use Parquet or Delta Lake. Whenever possible, keep the data in its original format. If the source data is from OneLake, Azure Data Lake Store Gen2 (ADLS Gen2), Amazon S3, or Google, create a shortcut in the bronze zone instead of copying the data across.
For the silver and gold zones, we recommend that you use Delta tables because of the extra capabilities and performance enhancements they provide. Fabric standardizes on Delta Lake format, and by default every engine in Fabric writes data in this format. Further, these engines use V-Order write-time optimization to the Parquet file format. That optimization enables fast reads by Fabric compute engines, such as Power BI, SQL, Apache Spark, and others. For more information, see Delta Lake table optimization and V-Order.
Lastly, today many organizations face massive growth in data volumes, together with an increasing need to organize and manage that data in a logical way while facilitating more targeted and efficient use and governance. That can lead you to establish and manage a decentralized or federated data organization with governance. To meet this objective, consider implementing a data mesh architecture. Data mesh is an architectural pattern that focuses on creating data domains that offer data as a product.
You can create a data mesh architecture for your data estate in Fabric by creating data domains. You might create domains that map to your business domains, for example, marketing, sales, inventory, human resources, and others. You can then implement medallion architecture by setting up data zones within each of your domains. For more information about domains, see Domains.
Understand Delta table data storage
This section describes other guidance related to implementing a medallion lakehouse architecture in Fabric.
File size
Generally, a big data platform performs better when it has a few large files rather than many small files. Performance degradation occurs when the compute engine has many metadata and file operations to manage. For better query performance, we recommend that you aim for data files that are approximately 1 GB in size.
Delta Lake has a feature called predictive optimization. Predictive optimization automates maintenance operations for Delta tables. When this feature is enabled, Delta Lake identifies tables that would benefit from maintenance operations and then optimizes their storage. While this feature should form part of your operational excellence and your data preparation work, Fabric can optimize data files during data write, too. For more information, see Predictive optimization for Delta Lake.
Historical retention
By default, Delta Lake maintains a history of all changes made, so the size of historical metadata grows over time. Based on your business requirements, keep historical data only for a certain period of time to reduce your storage costs. Consider retaining historical data for only the last month, or other appropriate period of time.
You can remove older historical data from a Delta table by using the VACUUM command. However, by default you can't delete historical data within the last seven days. That restriction maintains the consistency in data. Configure the default number of days with the table property delta.deletedFileRetentionDuration = "interval <interval>". That property determines the period of time that a file must be deleted before it can be considered a candidate for a vacuum operation.
Table partitions
When you store data in each zone, we recommended that you use a partitioned folder structure wherever applicable. This technique improves data manageability and query performance. Generally, partitioned data in a folder structure results in faster search for specific data entries because of partition pruning/elimination.
Typically, you append data to your target table as new data arrives. However, in some cases you might merge data because you need to update existing data at the same time. In that case, you can perform an upsert operation by using the MERGE command. When your target table is partitioned, be sure to use a partition filter to speed up the operation. That way, the engine can eliminate partitions that don't require updating.
Data access
You should plan and control who needs access to specific data in the lakehouse. You should also understand the various transaction patterns they're going to use while accessing this data. You can then define the right table partitioning scheme, and data collocation with Delta Lake Z-order indexes.
Related content
For more information about implementing a Fabric lakehouse, see the following resources.