Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
You can create a logical copy of KQL database data in an eventhouse by turning on OneLake availability. Turning on OneLake availability means that you can query the data in your KQL database in Delta Lake format via other Fabric engines such as Direct Lake mode in Power BI, Warehouse, Lakehouse, Notebooks, and more.
Delta Lake is a unified data lake table format that achieves seamless data access across all compute engines in Microsoft Fabric. For more information on Delta Lake, see What is Delta Lake?.
In this article, you learn how to turn on availability of KQL database data in OneLake.
How it works
You can turn on OneLake availability at the database or table level. When enabled at the database level, all new tables and their data are made available in OneLake. When turning on the feature, you can also choose to apply this option to existing tables by selecting the Apply to existing tables option, to include historic backfill. Turning on at the table level makes only that table and its data available in OneLake. The Data retention policy of your KQL database is also applied to the data in OneLake. Data removed from your KQL database at the end of the retention period is also removed from OneLake. If you turn off OneLake availability, data is soft deleted from OneLake.
While OneLake availability is turned on, you can't do the following tasks:
- Rename tables
- Alter table schemas
- Apply Row Level Security to tables
- Data can't be deleted, truncated, or purged
If you need to do any of these tasks, use the following steps:
Important
Turning off OneLake availability soft deletes your data from OneLake. When you turn availability back on, all data is made available in OneLake, including historic backfill.
Turn off OneLake availability.
Perform the desired task.
Turn on OneLake availability.
Important
For more information about the time it takes for data to appear in OneLake, see Adaptive behavior.
There's no extra storage cost to turn on OneLake availability. For more information, see resource consumption.
Prerequisites
- A workspace with a Microsoft Fabric-enabled capacity
- A KQL database with editing permissions and data
Turn on OneLake availability
You can turn on OneLake availability either on a KQL database or table.
To turn on OneLake availability, select a database or table.
In the OneLake section of the details pane, set Availability to Enabled.

In the Enable Onelake Availability window, select Enable.
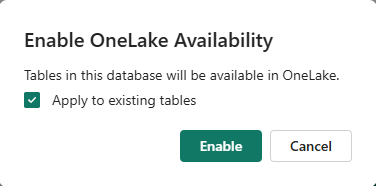
The database or table details refresh automatically.

With the OneLake availability in your KQL database or table turned on, you can now access all the data at the given OneLake path in Delta Lake format. You can also create a OneLake shortcut from a Lakehouse, Data Warehouse, or query the data directly via Power BI Direct Lake mode.
Adaptive behavior
Eventhouse offers a robust mechanism that intelligently batches incoming data streams into one or more Parquet files, structured for analysis. Batching data streams is important when dealing with trickling data. Writing many small Parquet files into the lake can be inefficient resulting in higher costs and poor performance.
Eventhouse's adaptive mechanism can delay write operations if there isn't enough data to create optimal Parquet files. This behavior ensures Parquet files are optimal in size and adhere to Delta Lake best practices. The Eventhouse adaptive mechanism ensures that the Parquet files are primed for analysis and balances the need for prompt data availability with cost and performance considerations.
Note
- By default, the write operation can take up to 3 hours or until files of sufficient size (typically 200-256 MB) are created.
- You can adjust the delay to a value between 5 minutes and 3 hours.
For example, use the following command to set the delay to 5 minutes:
.alter-merge table <TableName> policy mirroring dataformat=parquet with (IsEnabled=true, TargetLatencyInMinutes=5);
Caution
Adjusting the delay to a shorter period might result in a suboptimal delta table with a large number of small files, which can lead to inefficient query performance. The resultant table in OneLake is read-only and can't be optimized after creation.
You can monitor how long ago new data was added in the lake by checking your data latency using the .show table mirroring operations command command.
Results are measured from the last time data was added. When Latency results in 00:00:00, all the data in the KQL database is available in OneLake.
View files
When you turn on OneLake availability on a table, a delta log folder is created along with any corresponding JSON and Parquet files. You can view the files that were made available in OneLake and their properties while remaining within Real-Time Intelligence.
To view the files, hover over a table in the Explorer pane and then select the More menu [...] > View files.
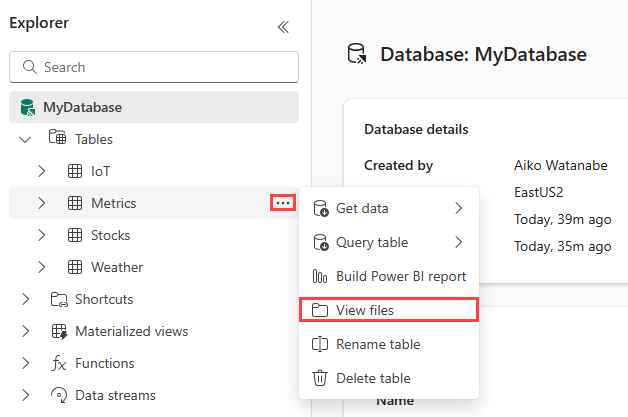
To view the properties of the delta log folder or the individual files, hover over the folder or file and then select the More menu [...] > Properties.
To view the files in the delta log folder:
- Select the _delta_log folder.
- Select a file to view the table metadata and schema. The editor that opens is in read-only format.
Access mirroring policy
By default, when OneLake availability is turned on, a mirroring policy is enabled. You can use the policy to monitor data latency or alter it to partition delta tables.
Note
If you turn off OneLake availability, the mirroring policy's IsEnabled property is set to false (IsEnabled=false).
Partition delta tables
You can partition your delta tables to improve query speed. For information about when to partition your OneLake files, see When to partition tables. Each partition is represented as a separate column using the PartitionName listed in the Partitions list. This means your OneLake copy has more columns than your source table.
To partition your delta tables, use the .alter-merge table policy mirroring command.
Query delta tables
You can use Fabric Notebook to read the OneLake data using the following code snippet.
In the code snippet, replace
<workspaceGuid>,<workspaceGuid>, and<tableName>with your own values.
delta_table_path = 'abfss://`<workspaceGuid>`@onelake.dfs.fabric.microsoft.com/`<eventhouseGuid>`/Tables/`<tableName>`'
df = spark.read.format("delta").load(delta_table_path)
df.show()
Note
For an Azure Data Explorer database, use this code:
delta_table_path = 'abfss://`<workspaceName>`@onelake.dfs.fabric.microsoft.com/`<itemName>`.KustoDatabase/Tables/`<tableName>`'
Related content
- To expose the data in OneLake, see Create a shortcut in OneLake
- To create a OneLake shortcut in Lakehouse, see What are shortcuts in lakehouse?
- To query referenced data from OneLake in your KQL database or table, see Create a OneLake shortcut in KQL database