Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Important
APIs under the /beta version in Microsoft Graph are subject to change. Use of these APIs in production applications is not supported. To determine whether an API is available in v1.0, use the Version selector.
The industry data API is an Education industry focused ETL (Extract-Transform-Load) platform that combines data from multiple sources into a single Azure Data Lake data store, normalizes the data, and exports it in outbound flows. The API provides resources that you can use to get statistics after the data is processed, and assist with monitoring and troubleshooting.
The industry data API is defined in the OData subnamespace microsoft.graph.industryData.
Industry data API and education
The industry data API powers the Microsoft School Data Sync (SDS) platform to help automate the process of importing data and synchronizing organizations, users and users associations, and groups with Microsoft Entra ID and Microsoft 365 from student information systems (SIS) and student management systems (SMS). After normalizing the data the API utilizes the data through multiple outbound provisioning flows to manage users, class groups, administrative units, and security groups.
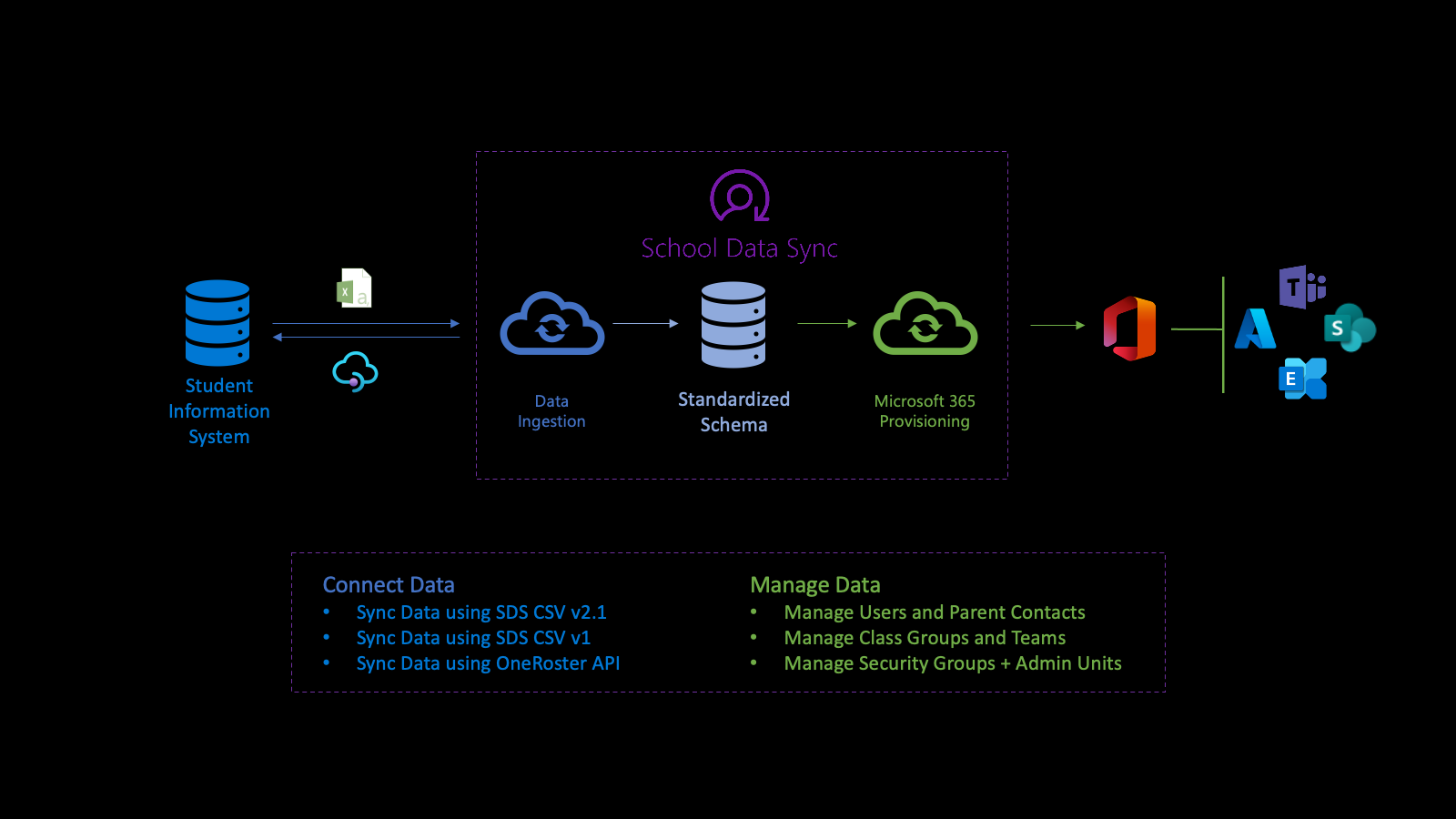
First, you connect to your institution's data. To define an inbound flow, create a sourceSystemDefinition, dataConnector, and yearTimePeriodDefinition. By default, the inbound flow activates twice (2x) daily (called a run).
When the run starts, it connects to the sourceSystemDefinition and dataConnector of the inbound flow, and performs basic validation. Basic validation ensures that the connection is correct, when the OneRoster API is the source, or the filenames and headers are correct, when a CSV is the source.
Next, the system transforms the data for import in preparation for advanced validation. As part of the data transformation, the data is associated based on the configured yearTimePeriodDefinition.
The system stores the latest copy of the Microsoft Entra ID of the tenant into the Azure Data Lake. The copy of the Microsoft Entra assists with user matching between the sourceSystemDefinition and the Microsoft Entra user object. At this stage, the match link is written only to the Azure Data Lake.
Next, the inbound flow performs advanced validation to determine data health. The validation focuses on identifying errors and warnings to ensure that good data comes in and bad data stays out. Errors indicate that a record didn't pass validation and was removed from further processing. Warnings indicate that the value on an optional field of a record didn't pass. The value is removed from the record, but the record is included for further processing.
Errors and warnings help you better understand data health.
For the data that passed validation, the process uses the configured yearTimePeriodDefinition to determine its association for longitudinal storage, as follows:
- As the data is stored the internal representation in the Azure Data Lake of the tenant, it identifies when it was first seen by industry data.
- For data linked with a user organization, role association, and group association, it also identifies data as active in session based on the yearTimePeriodDefinition.
- In future runs, for the same inbound flow, sourceSystemDefinition, and yearTimePeriodDefinition, industry data identifies if the record is still seen.
- Based on the presence or absence of record, the record is kept active or marked as no longer active in session for the configured yearTimePeriodDefinition. This process determines the historical and longitudinal nature of the data between days, months, and years.
At the end of each run, industryDataRunStatistics are available to determine data health.
Errors and warnings related to industryDataRunStatistics are produced to help provide an initial understanding of data health. When you investigate data health, industry data provides the ability to download a log file that contains information based on the errors and warnings found to begin the data investigation process to correct the data in the source system.
After investigating and addressing any data errors or warnings, when you're comfortable with the current state of the data health, you can enable the scenarios with the data. When you enable a scenario to use this data, the scenario creates an outbound provisioning flow.
Managing data through outbound provisioning flows simplifies the management of users and classes. Only active and matched users are included in the data that is used to write the link to the Microsoft Entra user object. This link facilitates the integration between the SIS/SMS and their sections for groups and Microsoft Teams classrooms.
For more information, see the sections School Data Sync, SDS prerequisites, and SDS core concepts of the School Data Sync overview.
Registration, permissions, and authorization
You can integrate industry data APIs with third-party apps. For details about how to do this, see the following articles:
- Authentication and authorization basics.
- Register an application with the Microsoft identity platform.
- Get access on behalf of a user.
- Microsoft Graph permissions reference.
- Resolve Microsoft Graph authorization errors.
Common use cases
| Use case | REST resource | See also |
|---|---|---|
| Create an activity to import a delimited data set | inboundFileFlow | inboundFileFlow methods |
| Define a source of inbound data | sourceSystemDefinition | sourceSystemDefinition methods |
| Create a connector to post data to an Azure Data Lake (if CSV) | azureDataLakeConnector | azureDataLakeConnector methods |
Data domain
The dataDomain property defines the type of data that is imported and determines the common data model format for it to be stored in. Currently, the only supported dataDomain is educationRostering.
Reference definitions
A referenceDefinition represents an enumerated value. Each supported industry domain receives a distinct collection of definitions. referenceDefinition resources are used extensively throughout the system, both for configuration and transformation, where the potential values are specific to a given industry. Each referenceDefinition uses a composite identifier of {referenceType}-{code} to provide a consistent experience across customer tenants.
Reference values
Types based on referenceValue provide a simplified developer experience for binding referenceDefinition resources. Each referenceValue type is bound to a single reference type, allowing developers to provide only the code portion of the referencing definition as a simple string and eliminating potential confusion as to which type of referenceDefinition a given property is expected.
Example
The userMatchingSettings.sourceIdentifier property takes a identifierTypeReferenceValue type that binds to the RefIdentifierType referenceType.
"sourceIdentifier": {
"code": "username"
},
A referenceDefinition might also be bound directly using the value property.
"sourceIdentifier": {
"value@odata.bind": "external/industryData/referenceDefinitions/RefIdentifierType-username"
},
Role groups
Transformation of the data is often shaped by each individual user's role within an organization. These roles are defined as reference definitions. Given the number of potential roles, binding each role individual would result in a tedious user experience. Role groups are a collection of RefRole codes.
{
"@odata.type": "#microsoft.graph.industryDataRoleGroup",
"id": "37a9781b-db61-4a3c-a3c1-8cba92c9998e",
"displayName": "Staff",
"roles": [
{ "code": "adjunct" },
{ "code": "administrator" },
{ "code": "advisor" },
{ "code": "affiliate" },
{ "code": "aide" },
{ "code": "alumni" },
{ "code": "assistant" }
]
}
Industry data connectors
An industryDataConnector acts as a bridge between a sourceSystemDefinition and an inboundFlow. It's responsible for acquiring data from an external source and providing the data to inbound data flows.
Upload and validate CSV data
For information about CSV data, see:
The following are requirements for the CSV file:
- File names and column headers are case-sensitive.
- CSV files must be in UTF-8 format.
- Incoming data must not have line breaks.
To review and download sample set of SDS V2.1 CSV files, see the SDS GitHub repository.
Important
The industryDataConnector doesn't accept delta changes so each upload session must contain the complete data set. Supplying only partial or delta data results in the transition of any missing records to an inactive state.
Request an upload session
The azureDataLakeConnector uses CSV files uploaded to a secure container. This container lives within the context of a single fileUploadSession and is automatically destroyed after data validation or the file upload session expires.
The current file upload session is retrieved from an azureDataLakeConnector via the getUploadSession that returns the SAS URL for uploading the CSV files.
Validate uploaded files
Uploaded data files must be validated before an inbound flow can process the data. The validation process finalizes the current fileUploadSession and verifies that all required files are present and properly formatted. Validation is initiated by calling the industryDataConnector: validate action of the azureDataLakeConnector resource.
The validate action creates a long-running fileValidateOperation. The URI for the fileValidateOperation is provided in the Location header of the response. You can use this URI to track the status of the long-running operation, and any errors or warnings created during validation.
Next steps
Use the Microsoft Graph industry data APIs as an extract, transform, and load (ETL) engine. To learn more:
- Explore the resources and methods that are most helpful to your scenario.
- Try the API in the Graph Explorer.