Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Microsoft Graph Data Connect lets developers create applications that customers can use to provide managed access to their at-scale Microsoft Graph datasets. This article provides tips that help you take advantage of the Microsoft Graph Data Connect feature. For an introduction to Microsoft Graph Data Connect, see the overview.
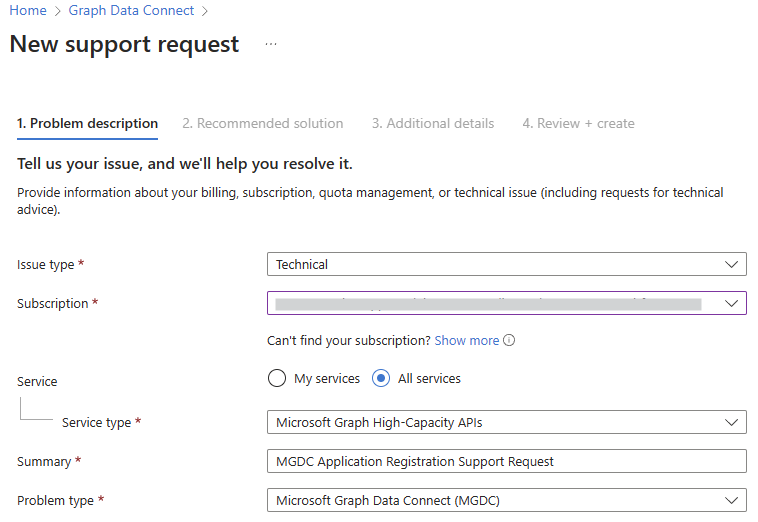
For more questions, see troubleshooting or create a new Azure support request with the following selections:
- Service type: Choose Microsoft Graph High-Capacity APIs
- Problem type: Choose Microsoft Graph Data Connect (MGDC)
Is Microsoft Graph Data Connect right for me?
Microsoft Graph Data Connect and Microsoft Graph APIs provide access to the same underlying data but in very different ways. Microsoft Graph Data Connect is designed to extract large amounts of datasets in bulk, scalable to your entire organization; while Microsoft Graph APIs are suitable for accessing small amount of data from selected users and groups in your organization.
For example, you might want to use Microsoft Graph Data Connect to do an initial extraction of the last year of email data, and then use Microsoft Graph APIs to analyze emails in real time moving forward. Microsoft Graph Data Connect and Microsoft Graph APIs are different tools for different jobs. It's important to think about which access method best fits your scenario. For more information, see When should I use Microsoft Graph API or Microsoft Graph Data Connect.
What are some scenarios that companies use Microsoft 365 data for?
There are any number of use cases that can be powered by Microsoft 365 data. The following are some top scenarios that customers are interested in:
Customer Relationship Analytics: For commercial business leaders, go beyond traditional CRM insights and understand customer interactions and relationships based on communication and collaboration patterns.
Business Process Analytics: For better operations, see how work really flows through the organization on a day-to-day basis. Pinpoint the manual processes and workflow bottlenecks that should be automated or optimized.
Security and Compliance Analytics: To secure sensitive data, learn how employees are using and sharing sensitive information. Implement anomaly detection, threat intelligence, audit log analysis, risk management, and legal forensics.
People Productivity Analytics: For driving transformation, export your Viva productivity metrics, so you can convert insights into solutions with digital adoption, smart meetings and content, hybrid workplaces, and cultural change.
How do Viva Insights and Microsoft Graph Data Connect differ?
Viva Insights and Microsoft Graph Data Connect are complementary. Although both rely on Microsoft 365, Viva Insights and Data Connect serve different audiences and needs.
When customers are looking for insights and analytics beyond Viva Insights, Data Connect provides the extensibility to deliver custom requirements. For example, it offers Teams call records and transcripts as well as SharePoint Online data sets, which aren't currently in scope for Viva Insights. Additionally, Data Connect raw data provides granular details that aren’t otherwise available from Viva Insights.
Is there any initial overhead with Microsoft Graph Data Connect?
Because Data Connect is designed to extract large amounts of data in bulk, some overhead is incurred before the data can be extracted. This overhead is around 45 minutes, which means that all pipelines take at least that long regardless of the data size. If the initial overhead is too long for your use case, please create a new Azure support request, including the details mentioned in the previous section.
What regions is Microsoft Graph Data Connect available in?
Microsoft Graph Data Connect is currently available in multiple regions across the following geographies: North America, Europe, Asia Pacific, United Kingdom, and Australia. Other regions will be available in the future.
For a list of Office to Azure regions and mappings, see Dataset, regions and sinks.
What datasets are available through Microsoft Graph Data Connect?
The following types of datasets are available:
Basic: Datasets generated from raw customer created content and inputs from Microsoft 365 applications and services (for example, Microsoft Entra ID, Outlook, or Teams datasets).
Cleaned: Datasets generated by either normalization and deduplication from basic datasets, or datasets created from user activity or behavior signals in Microsoft 365 (for example, SharePoint, Office 365 datasets).
Curated: Datasets custom generated for a specific use case or analytics scenarios, or datasets from first-party Microsoft 365 analytics applications for their extensibility, for example, Viva Insights metrics).
Multiple datasets for each of the following are available:
- Teams
- Outlook
- Microsoft Entra ID
- OneDrive/Sharepoint
- Viva Insights
New datasets are added to Microsoft Graph Data Connect regularly. For a complete list, see Dataset, regions, and sinks.
Which datasets are in preview and which are generally available?
For information about datasets that are generally available or in preview only, see Dataset, regions, and sinks.
How is billing calculated?
Microsoft Graph Data Connect charges customers on a monthly basis and also does fractionable rounding up when calculating the bill. Each pipeline run is billed separately.
For example, a customer has 20 pipeline runs within the month, each yielding 500 rows. In total, the customer runs pipelines for 10,000 rows that month. However, their bill will not be 10,000 rows/1000 rows = 10 units.
Instead, the customer is billed for 20 units because Microsoft Graph Data Connect rounds up fractions. Because 500 rows/1000 rows = 0.5 and 0.5 is a fraction, it rounds up to 1. The customer is billed one unit per pipeline run, which results in 20 units billed in total.
What can I do if a dataset isn't yet supported for my tenant?
For preview datasets, make sure that you meet the criteria described in Datasets, regions, and sinks. These datasets are only available to customers who have opted in for them explicitly.
For questions, create a new Azure support request, including the details mentioned in the previous section.
What scenarios is Microsoft Graph Data Connect best for?
Organizations that can tap into the large datasets that power their productivity tools can gain tremendous insights into the challenges and opportunities they might encounter. Customers build applications across multiple scenarios, such as organization networks for people productivity analytics, information oversharing for security and compliance analytics, seller relationship strengths for customer relationship analytics, and more.
Is it possible for my data to stay within the organization's subscription with Microsoft Graph Data Connect?
Microsoft Graph Data Connect respects your organizational tenant boundary when delivering your requested datasets. Both Azure resources and Microsoft 365 services must be located within the same Microsoft Entra tenancy to access your Microsoft 365 dataset. Cross-tenant dataset access isn't available today.
Are service principals required with Microsoft Graph Data Connect?
When creating the Azure Synapse or Data Factory pipeline, you have to provide a service principal to the Microsoft 365 linked service. In Azure, a service principal is a security identity that represents an application/service (as opposed to a user). Microsoft Graph Data Connect uses this service principal as its identity when getting authorized access to your Microsoft 365 data.
If you create an Azure managed application for others to use in their tenants, you still provide a service principal for the app to use. This service principal exists in your (the publisher's) tenant. However, if the app needs other service principals, your customer (the installer) creates them in their own tenant. For example, your Azure Synapse or Azure Data Factory pipeline likely needs access to a storage resource in Azure. The customer creates the service principal with permissions to the storage account for the pipeline to use.
For more information about building your application with Azure Synapse or Azure Data Factory, see the Data Connect quick start.
Will every pipeline run require a new consent request?
As long as the scope of the data being extracted remains the same for datasets, columns, users, and sink, the pipeline run doesn't require a new consent request. Instead, the pipeline uses the approved active consent. Running a pipeline with the same scope for different dates doesn't require a new consent.
Can I deduplicate emails when needed?
When you extract emails from the Message dataset, there are often multiple JSON objects for the same email. These duplicates exist because when an email is sent to multiple people, there's a copy of the email in every recipient's mailbox. Because the dataset is extracted from every mailbox, it contains all copies across users. In some scenarios, it might be necessary to keep every copy, but in others, you might want to remove the duplicates.
You can deduplicate the exported JSON objects based on the internetMessageId of the messages: two messages with the same internetMessageId are duplicate copies of the same instance. Because the duplicates can exist in different blobs, you must deduplicate across all blobs rather than deduplicating in each blob separately.
Can I use the puser field to determine the relevant user?
The extracted data includes some meta properties that don't exist when using the corresponding Microsoft Graph APIs. Specifically, the puser field can be useful for determining which user the data was extracted from. In the scenario where you have two copies of the same email in different mailboxes, you can use the puser field to determine which copy came from which mailbox. The puser field is also useful for datasets such as the Manager dataset. The exported JSON contains information about a manager, but this is only useful if you know whose manager they are. The puser field tells you whose manager that JSON object corresponds to.
Is hybrid mode tenant setup supported?
If your Microsoft 365 setup has some users in Exchange Online and some users in Exchange on-premises, then the users who are in Exchange on-premises would not be supported. Unfortunately, Data Connect currently isn't supported for Exchange on-premises users.
Are resource accounts supported?
We don't currently support access to messages or events from resource accounts.
Why do I sometimes see multiple files per ADF pipeline run but other times see only one file per run?
Microsoft Graph Data Connect takes the user list for each pipeline run and then distributes the dataset extraction and curation across multiple jobs that run in parallel. For each parallel run, one output file is generated in the data sink defined by you. In some cases, if the user list is small, they might be mapped into one extraction and curation job, and in those cases only one output file would be generated in the data sink.