Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
DirectQuery in Power BI lets you keep data in the source and query it at report time instead of importing it. This article explains when to use DirectQuery, its limitations, and alternatives such as hybrid tables, Direct Lake, and live connections so you can choose the right mode.
This article describes:
- Power BI data connectivity modes and where DirectQuery fits
- When to use DirectQuery versus Import, hybrid tables, Direct Lake, or a live connection
- Limitations, implications, and performance considerations
- Recommendations for modeling and report design
- Diagnose and improve performance
Note
DirectQuery is also a feature of SQL Server Analysis Services. Although there are similarities, this article focuses on DirectQuery with Power BI semantic models.
For more about composite models, see Use composite models in Power BI Desktop. Download the PDF DirectQuery in SQL Server 2016 Analysis Services from Microsoft.
Quick decision guide
The following table summarizes which Power BI connectivity mode to consider based on your requirements. Use it as a quick reference to help choose between Import, DirectQuery, Hybrid tables, Direct Lake, or live connections:
| If you need | Consider first | Why |
|---|---|---|
| Maximum interactivity and full transformation flexibility | Import | In-memory columnar engine and rich modeling features |
| Near real-time changes on recent fact data plus historical context | Hybrid table (Import and DirectQuery partition) | Queries source for hot data and caches historical data. |
| Large lakehouse or warehouse scale with low latency reads (Fabric) | Direct Lake | Bypasses scheduled refresh and retains Import behaviors |
| Federated access to multiple external sources without full ingestion | DirectQuery (composite model) | Leaves data in place and blends sources. |
| Central governed enterprise model already published | Live connection to semantic model or Analysis Services | Reuses curated model and avoids duplication. |
| Push parameters to source at runtime (user-driven filtering) | DirectQuery with dynamic M parameters | Reduces scanned data and improves performance. |
| High concurrency and remote latency challenges | Import or Aggregations over DirectQuery | Aggregations accelerate common queries |
Power BI data connectivity modes
Power BI connects to many data sources:
- Online services like Salesforce and Dynamics 365
- Databases like SQL Server, PostgreSQL, MySQL, Oracle, Snowflake, and Amazon Redshift
- Files (Excel, CSV, JSON, Parquet)
- Big data and analytics engines like Spark and Databricks
- Other sources like websites and Microsoft Exchange
Import data from these sources. Some also support DirectQuery. For a maintained list, see Power BI data sources. DirectQuery-enabled sources typically deliver interactive aggregate query performance.
Use import by default. It uses Power BI's high-performance in-memory engine and provides the richest feature set. Move beyond import only when specific constraints (latency, size, governance, security, or architecture) require it.
Modern enhancements—Hybrid tables, Direct Lake, automatic aggregations, composite models, and incremental refresh—reduce how often you need pure DirectQuery.
The following sections cover Import, DirectQuery, and live connection modes. The remainder of the article focuses on DirectQuery, while acknowledging alternative approaches.
Import connections
When you import data:
- Get data selections define queries per table set; you can shape them (filter, aggregate, join) before loading.
- All data defined by those queries is loaded into the semantic model’s in-memory cache.
- Building visuals queries only the cached data—fast and fully interactive.
- Visuals don’t reflect source changes until you refresh (reimport).
- Publishing uploads a semantic model containing the imported data. You can schedule refresh (frequency depends on license) and might need an on-premises data gateway.
- Building or opening reports in the service uses the imported data.
- Pinned dashboard tiles refresh when the semantic model refreshes.
DirectQuery connections
When you use DirectQuery:
- Get data establishes a connection to a supported source. For relational sources, you can still select tables or views; for multidimensional sources (for example SAP BW), you select the source model.
- No data is imported at load time. Each visual triggers one or more queries to the underlying source.
- Visual refresh latency depends entirely on the underlying source performance (and network/gateway overhead if applicable).
- Changes in source data appear only after actions that requery (navigation, slicer/filter changes, manual refresh).
- Publishing creates a semantic model definition (schema and metadata) without imported data.
- Reports in the service query the source. A gateway might be required for on-premises sources.
- Dashboard tiles based on DirectQuery models refresh on a schedule to cache tile results for fast dashboard opening.
- Dashboard tiles show the results from their last scheduled refresh unless manually refreshed.
Live connections
A live connection connects Power BI directly to an existing semantic model (for example Analysis Services or another published Power BI semantic model). It’s similar to DirectQuery (no imported data), but semantics (like role enforcement) are handled by the upstream model. When you connect live:
- The full external model fields list appears—no Power Query query definition.
- Live connections always pass the identity of the user to Analysis Services or the Power BI semantic model for security trimming.
- Some modeling activities (like adding calculated tables) aren’t available because the model is external.
Where DirectQuery fits among newer options
DirectQuery was the primary solution for very large or fast-changing data you couldn’t efficiently import. Today:
- Hybrid tables let you mix in-memory and DirectQuery partitions in one table (recent vs historical).
- Direct Lake (Fabric) allows near real-time access to lakehouse tables without traditional refresh overhead.
- Automatic aggregations and manual aggregation tables accelerate frequent queries.
- Incremental refresh with real-time allows the most recent time window DirectQuery to source while older data remains imported.
Evaluate these options before adopting a fully DirectQuery model.
For real-time, high-volume time-series workloads on Microsoft Fabric, a common pattern is DirectQuery to a Fabric KQL database (Real-Time Intelligence) paired with source-side aggregations and dynamic M parameters. See Kusto-based source considerations for guidance on this workload.
DirectQuery use cases
DirectQuery is most beneficial when:
- Data changes too frequently for import (even with incremental refresh and the maximum scheduled refresh frequency), and you need low latency visibility.
- Data volume or governance constraints make full ingestion impractical.
- Source enforced security (fine grained row rules) must remain authoritative via passthrough.
- Data sovereignty or regulatory rules restrict persisted full copies.
- The source is multidimensional or measure centric (like SAP BW), and server defined measures must be resolved per visual.
Data changes frequently and you need near real-time reporting
Imported models (Pro) can schedule up to 8 refreshes per day (plus on-demand/API triggers). Premium and PPU support up to 48 scheduled refreshes per day, plus incremental refresh and real-time DirectQuery for the latest partition (Hybrid). If your required latency still can’t be met—or full import is infeasible—use DirectQuery, Hybrid tables, or Direct Lake. DirectQuery dashboards can refresh tiles as often as every 15 minutes.
Data is large
Full import might exceed memory or refresh windows. DirectQuery queries data in place. If the source is too slow for interactive performance, consider:
- Importing only aggregated or filtered subsets.
- Using incremental refresh and aggregations.
- Using hybrid tables or Direct Lake for recent and high value segments.
See Large semantic models in Power BI Premium for managing sizable in-memory data.
Source enforced security
Import relies on Power BI credentials plus optional row-level security (RLS) defined in the semantic model. DirectQuery can (when supported) pass user identity (SSO) so the source enforces its own security rules. See Overview of single sign-on (SSO) for on-premises data gateways in Power BI.
Data sovereignty restrictions
When regulations require data to stay within a controlled boundary, DirectQuery limits persisted copies. Visual and tile caches can still contain limited aggregated data.
Source with server defined measures
Some systems (like SAP BW) contain semantic logic (measures and hierarchies) that you resolve at query time. DirectQuery enables per visual resolution. See DirectQuery and SAP BW and DirectQuery and SAP HANA.
Source specific considerations (including PostgreSQL and MySQL)
Behavior and performance differ by engine:
- PostgreSQL: Quoted identifiers are case sensitive. Ensure appropriate b-tree indexes on join and filter columns. Avoid functions that break query folding early. Check for implicit casts on text and numeric joins.
- MySQL: Use consistent collations and SQL modes. Create composite indexes for common filter and join patterns. Large
TEXTcolumns can reduce folding or force postprocessing. - Snowflake, BigQuery, and Databricks: Elastic scaling improves concurrency, but cold start latency can affect the first query. Send warmup pings or schedule periodic activity.
- Azure Synapse, SQL, and Fabric Warehouse: Columnstore indexes and result set caching provide strong acceleration. Pair them with automatic aggregations.
- Kusto-based sources (Azure Data Explorer and Fabric KQL databases): Projection pruning matters. Select only the required columns and push filters early. For high-volume time-series telemetry, use source-side aggregation rather than client-side grouping: push
make-series,summarize, andseries_decompose_anomaliesto the KQL engine and return aggregated results to visuals. Confirm that Power Query steps fold to native KQL so that summarized results — not raw events — are returned to Power BI. - SAP BW and SAP HANA: Measure resolution and hierarchy semantics drive query patterns. Avoid overlayering transformations that block folding.
Confirm query folding (select View Native Query in Power Query Editor) so transformations push down.
DirectQuery limitations
Using DirectQuery has implications across consistency, performance, security, transformations, modeling, and reporting.
General implications
The following general implications apply when using DirectQuery in Power BI:
- Refresh to see the latest data. Caches (visual, tile, result) mean a visual can show prior results until refreshed. Select Refresh to force a requery of all visuals on a page.
- Visuals aren't always time consistent. Different visuals (or internal queries in one visual) can execute at slightly different times. Refresh the page or design aggregated snapshots if strict point-in-time accuracy is required.
- Schema changes require a Power BI Desktop refresh. The service doesn't automatically detect dropped or renamed columns. Open the model in Power BI Desktop and refresh to reconcile model metadata.
- One million row intermediate result limit. Any query (or intermediate operation) that returns more than 1,000,000 rows fails. Premium capacities can raise this limit—see Max Intermediate Row Set Count.
- Changing storage mode is constrained. You can't globally switch an Import-only model to DirectQuery. See the next section.
Important
Because the engine that stores and queries data in Power BI is case insensitive, take special care when you work in DirectQuery mode with a case-sensitive source. Power BI assumes that the source has eliminated duplicate rows. Because Power BI is case insensitive, it treats two values that differ only by case as duplicate, whereas the source might not treat them as such. In such cases, the final result is undefined.
To avoid this situation, if you use DirectQuery mode with a case-sensitive data source, normalize casing in the source query or in Power Query Editor.
Changing storage modes (Import ↔ DirectQuery)
You can't toggle an entire Import model to DirectQuery. Instead:
- Add a new DirectQuery connection to the same source and map visuals to new tables.
- Create a composite model: keep Import dimensions, add DirectQuery fact tables (or vice versa), and optionally set some tables to Dual.
- Use Hybrid tables (recent DirectQuery partitions and historical Import) for hot and cold optimization.
- Rebuild with fold-friendly transformations if earlier steps prevent DirectQuery.
Note
Individual tables added through a DirectQuery-capable connection can switch between DirectQuery, Import, and Dual if all applied transformations still fold.
Performance and load implications
Interactive performance depends on source latency and concurrency. Aim for common visual refresh times under 5 seconds; more than 30 seconds degrades usability. Each user action triggers queries. High user, visual, and tile refresh counts can create significant load—plan capacity accordingly.
Security implications
Unless SSO is configured, DirectQuery uses configured stored credentials for all viewers. Define RLS in the semantic model as needed. Multiple sources in composite models can move data between sources; assess sensitive data movement—see Security implications.
Data transformation limitations
Power Query folding is required for scalable performance. Transformations must condense into a single native query. Complex steps (nonfoldable operations, certain custom functions, multistep procedural logic) can cause errors that require simplification or switching to Import. OLAP sources like SAP BW disallow in-query transformations because the entire external model is exposed. Stored procedure calls and common table expressions (CTEs) aren't supported in a way that allows folding in DirectQuery.
Modeling limitations
Most enrichment works, but some capabilities are reduced:
- No automatic date hierarchy (create explicit Date table).
- Time precision limited to seconds (remove milliseconds at source).
- Calculated columns limited to row-level expressions that fold; unsupported functions omitted from autocomplete.
- No parent-child PATH functions.
- Clustering not supported.
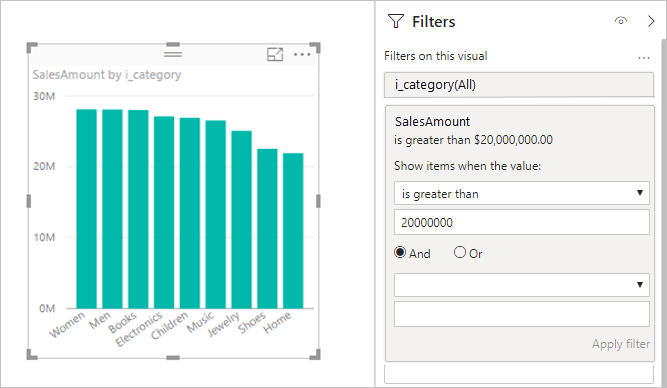
Reporting limitations
Most visuals work if the source is responsive. Watch these limitations and performance considerations:
- Long text columns longer than 32,764 characters aren't supported.
- Measure filters, TopN filters,
Median, advanced text contains/begins filters, multi-select slicers, and totals/subtotals (especially withDistinctCount) can add extra queries or degrade performance. - Consider simplifying design or disabling certain interactions.
Example (measure filter):
DirectQuery recommendations
This section provides practical recommendations for designing, optimizing, and troubleshooting DirectQuery models in Power BI. Follow these guidelines to improve performance, reliability, and user experience when working with DirectQuery connections.
Underlying data source performance
Validate baseline interactive queries. If they're slow, inspect queries by using Performance Analyzer and optimize the source schema (indexes, statistics, and columnstore where applicable). Favor integer keys for joins.
Model design
- Keep Power Query steps simple and foldable. Preview “View Native Query” often.
- Start with simple measures then iterate.
- Avoid joins on calculated expression columns—materialize in source if needed.
- Avoid joins on
uniqueidentifierwhere casts break index usage; materialize alternative key types. - Hide surrogate/system keys; create visible aliased columns if needed.
- Review calculated tables/columns that can produce nonfoldable expressions.
- Limit bidirectional filters to required cases only. Test the performance impact.
- Consider Assume referential integrity to enable
INNER JOINusage. - Avoid relative date filters in Power Query. Implement relative logic in the model or report layer instead.
Filtering example:
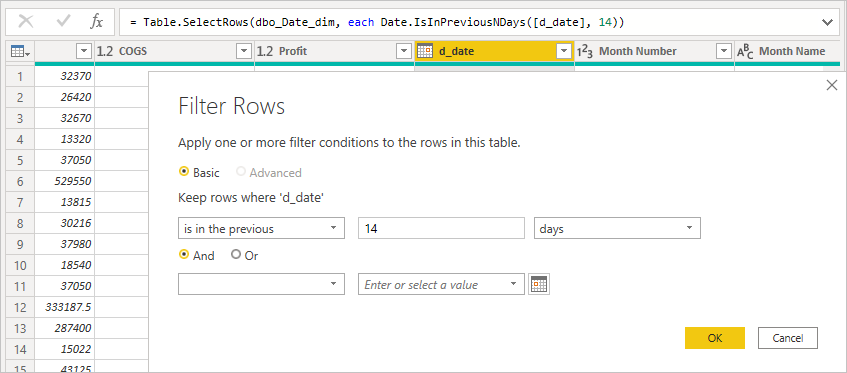
Resulting native query uses a fixed literal date:

Report design
When designing reports that use DirectQuery, consider the following best practices to optimize usability and performance:
Use query reduction options (use the Apply button for slicers and filters, and disable cross highlighting where latency hurts the experience).
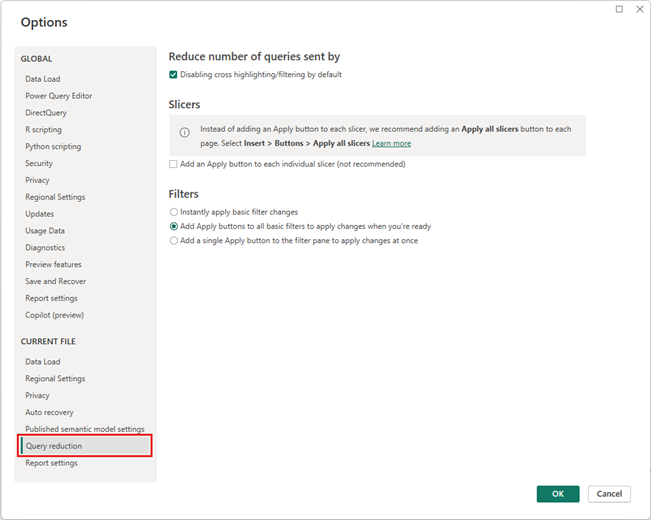
Apply key filters early to reduce intermediate row counts and avoid hitting limits.
Limit visuals per page to minimize parallel and serialized queries.
Disable unnecessary interactions (cross filtering or highlighting) if they trigger expensive source queries.
Maximum number of connections
Adjust per file DirectQuery concurrency (default 10) in File > Options and settings > Options > DirectQuery for the current file.
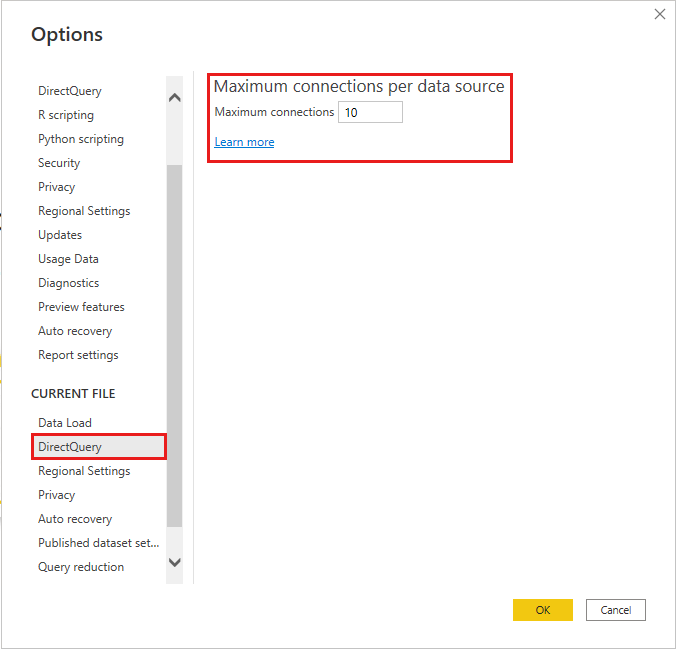
Higher values can improve throughput for many visuals, but they can also increase source load. Published behavior also depends on service or capacity limits.
| Environment | Upper limit per data source |
|---|---|
| Power BI Pro | 10 active connections |
| Power BI Premium | Depends on semantic model stock-keeping unit (SKU) limitation |
| Power BI Report Server | 10 active connections |
Note
The maximum DirectQuery connections setting applies to all DirectQuery sources when enhanced metadata is enabled (default for new models).
Performance mitigation features
Use these features to improve DirectQuery performance:
- Automatic aggregations and manual aggregation tables: Cache summarized data to reduce source queries.
- Hybrid tables: Maintain recent data via DirectQuery, historical via Import.
- Aggregation-aware measure design: Ensure DAX evaluates at the aggregation layer when possible.
- Dynamic M parameters: Push user selections into source predicates early.
- Query and result caching (capacity settings): Reuse recent result sets for repeated visuals.
- Dual storage mode for shared dimension tables: Reduce repeated remote dimension scans.
DirectQuery in the Power BI service
All DirectQuery data sources are supported through Power BI Desktop. Only a limited subset starts directly from the service UI. Start in Power BI Desktop for richer modeling and transformation control. For the current list of sources available directly in the service, see Power BI data sources.
Performance in the service depends on:
- Number of concurrent users
- Visual complexity and count per page
- Presence of row-level security (can reduce cache reuse)
- Tile refresh schedules
Report behavior in the Power BI service
Opening a report page runs queries for each visual (sometimes multiple per visual). Interactions (slicer changes, cross-highlighting, filters) run the queries again. The service caches some results. Exact repeat queries can return instantly unless security boundaries differ.
Capability nuances:
- Quick insights: Not supported for DirectQuery semantic models.
- Explore in Excel / Analyze in Excel: Supported but can feel slower. Consider import mode or aggregations for heavy Excel usage.
- Hierarchies in Excel: Some DirectQuery semantic model hierarchies don't appear the same in Excel.
Dashboard refresh
DirectQuery tiles refresh on a schedule. The default is hourly and you can set it from every 15 minutes up to weekly. With row-level security, each user runs separate tile queries. A high tile count multiplied by user count and refresh frequency can create heavy load—plan capacity and consider aggregations.
Query timeouts
The service enforces a 4-minute timeout per query. Visuals that exceed the limit fail with a timeout error. Make sure underlying sources provide interactive performance before you choose DirectQuery.
Performance diagnostics
Diagnose performance first in Power BI Desktop.
Use the Performance analyzer to isolate slow visuals. Focus on one problematic visual at a time.
Use SQL Server Profiler to see queries
Power BI Desktop writes session traces, including DirectQuery SQL for some sources, to the FlightRecorderCurrent.trc file in the user's AnalysisServicesWorkspaces folder.
To locate the trace:
In Power BI Desktop, select File > Options and settings > Options > Diagnostics.
Select Open crash dump/traces folder.
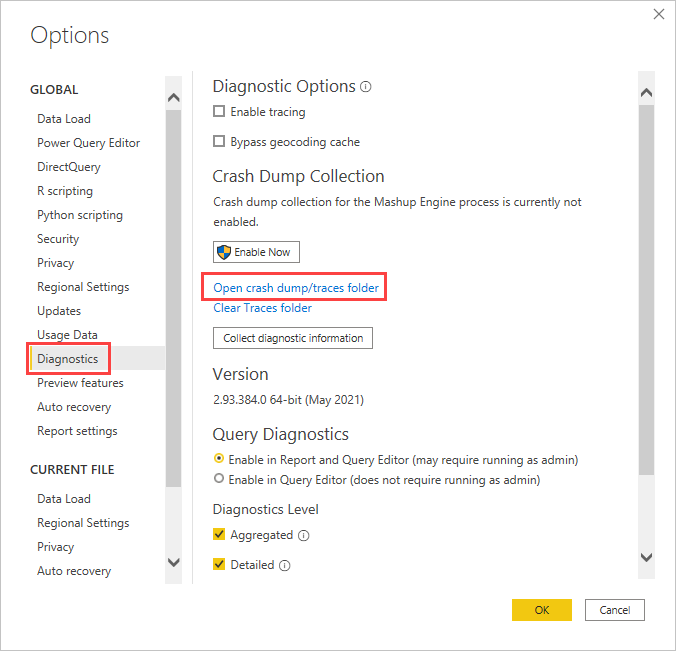
Go up one level to AnalysisServicesWorkspaces, open the active workspace folder, then Data, and locate FlightRecorderCurrent.trc.
In SQL Server Profiler, open the file: File > Open > Trace File.
Profiler displays grouped events:
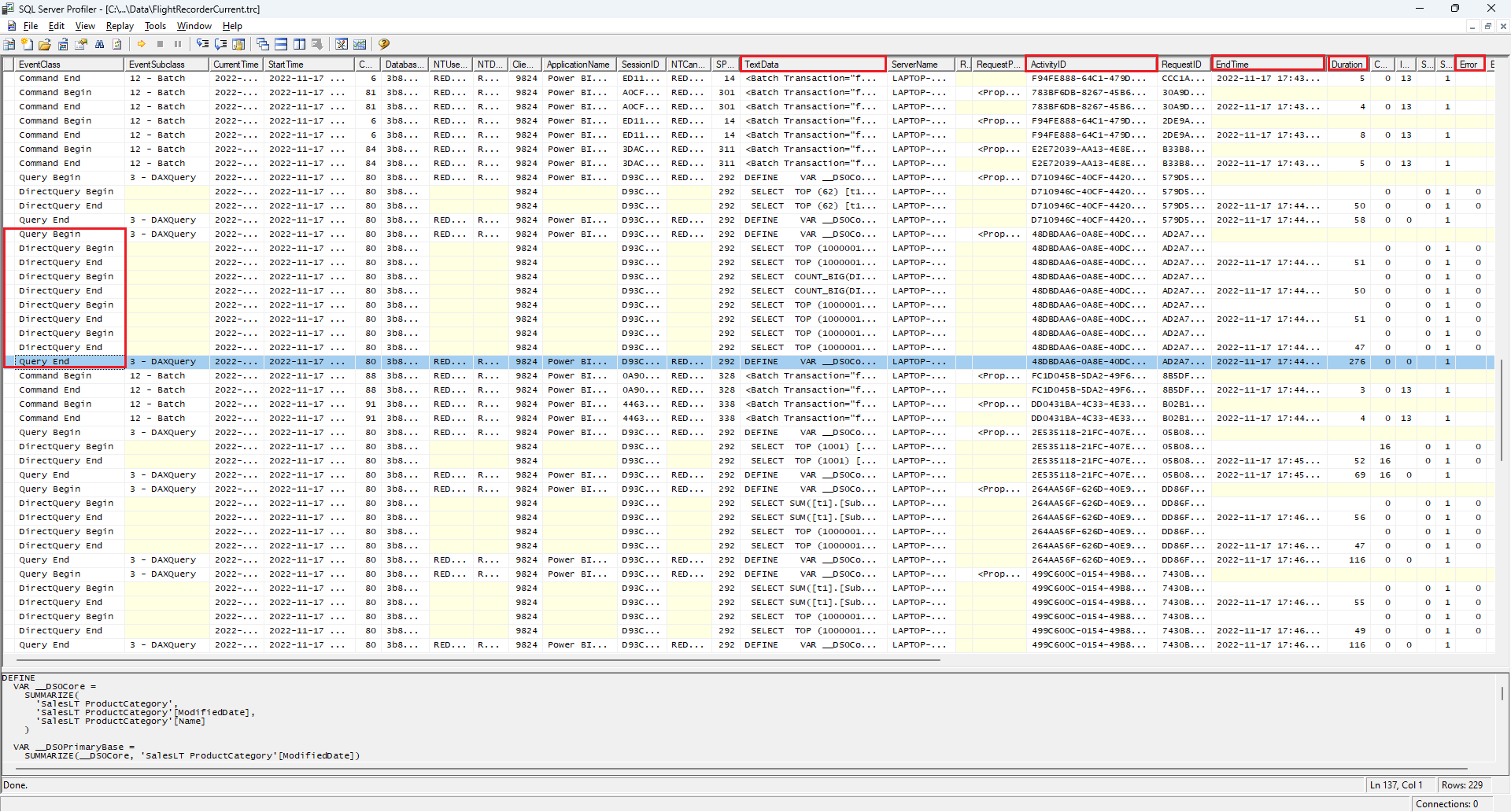
Event columns:
- TextData: DAX (for Query Begin/End) or native SQL (for DirectQuery Begin/End).
- Duration (ms) and EndTime help pinpoint slow stages.
- ActivityID groups related events.
Capture guidance:
- Keep sessions short (≈10 seconds of targeted actions).
- Reopen the trace file to view newly flushed events.
- Avoid multiple concurrent Desktop instances to reduce confusion.
Understand the format of queries
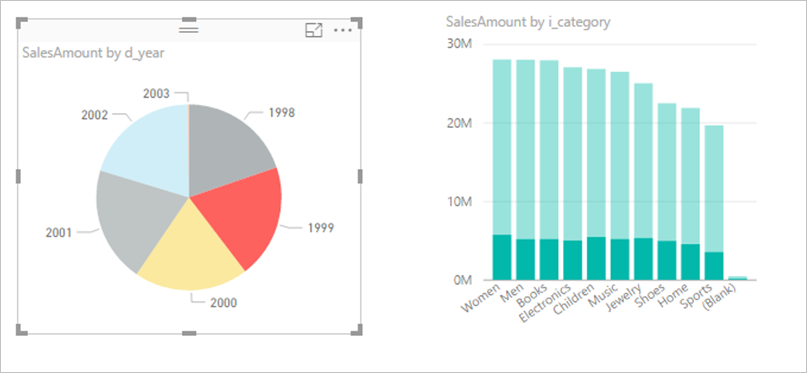
Power BI often uses a subselect (derived table) for each referenced logical table defined by Power Query steps.
Sample query logic:
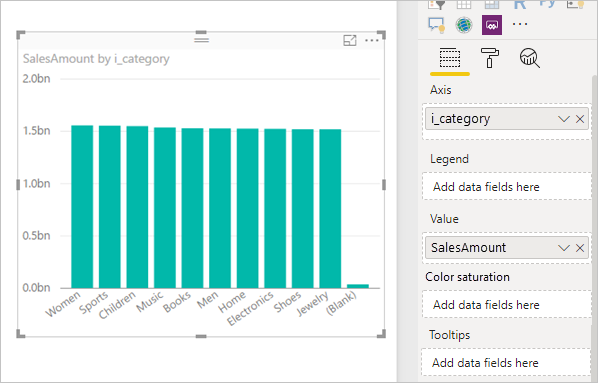
SalesAmount (SUMX(Web_Sales, [ws_sales_price]*[ws_quantity]))
by Item[i_category]
for Date_dim[d_year] = 2000
Resulting visual:
Generated SQL with subselects:
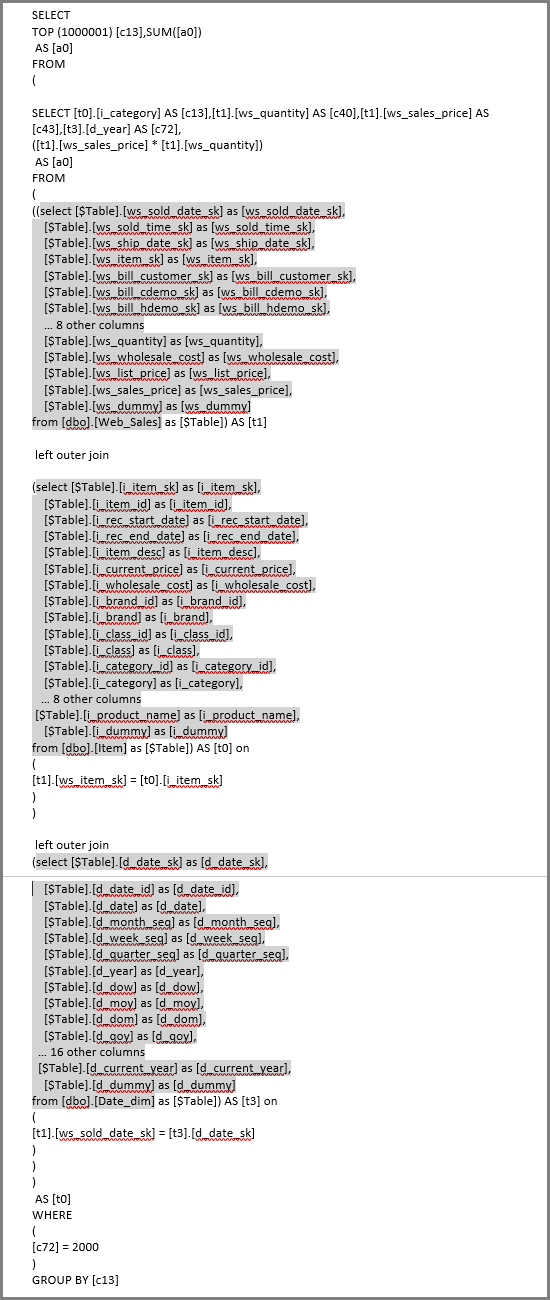
Subselect query patterns usually don't hurt performance on supported engines because optimizers eliminate unused columns. Prioritize foldability.
Note
This article provides general guidance on DirectQuery in Power BI. Always validate DirectQuery performance and behavior with your specific data source, schema, indexes, workload, and concurrency requirements before deploying to production.