Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Automatic aggregations use state-of-the-art machine learning (ML) to continuously optimize DirectQuery semantic models for maximum report query performance. Automatic aggregations are built on top of existing user-defined aggregations infrastructure first introduced with composite models for Power BI. Unlike user-defined aggregations, automatic aggregations don’t require extensive data modeling and query-optimization skills to configure and maintain. Automatic aggregations are both self-training and self-optimizing. They enable model owners of any skill level to improve query performance, providing faster report visualizations for large models.
With automatic aggregations:
- Report visualizations are faster - An optimal percentage of report queries are returned by an automatically maintained in-memory aggregations cache instead of backend data source systems. Outlier queries that aren't returned by the in-memory cache are passed directly to the data source using DirectQuery.
- Balanced architecture - When compared to pure DirectQuery mode, most query results are returned by the Power BI query engine and in-memory aggregations cache. Query processing load on data source systems at peak reporting times can be significantly reduced, which means increased scalability in the data source backend.
- Easy setup - Model owners can enable automatic aggregations training and schedule one or more refreshes for the model. With the first training and refresh, automatic aggregations begin creating an aggregations framework and optimal aggregations. The system automatically tunes itself over time.
- Fine-tuning – With a simple and intuitive user interface in the model settings, you can estimate the performance gains for a different percentage of queries returned from the in-memory aggregations cache and make adjustments for even greater gains. A single slide bar control helps you easily fine-tune your environment.
Requirements
Supported plans
Automatic aggregations are supported for Power BI Premium per capacity, Premium per user, and Power BI Embedded models.
Supported data sources
Automatic aggregations are supported for the following data sources:
- Azure SQL Database
- Azure Synapse Dedicated SQL pool
- SQL Server 2019 or later
- Google BigQuery
- Snowflake
- Databricks
- Amazon Redshift
Supported modes
Automatic aggregations are supported for DirectQuery mode models. Composite model models with both import tables and DirectQuery connections are supported. Automatic aggregations are supported for the DirectQuery connection only.
Permissions
To enable and configure automatic aggregations, you must be the Model owner. Workspace admins can take over as owner to configure automatic aggregations settings.
Configuring automatic aggregations
Automatic aggregations are configured in model Settings. Configuring is simple - enable automatic aggregations training and schedule one or more refreshes. Before you configure automatic aggregations for your model, be sure to entirely read through this article. It provides a good understanding of how automatic aggregations work and can help you decide if automatic aggregations are right for your environment. When you're ready for step-by-step instructions on how to enable automatic aggregations training, configure a refresh schedule, and fine-tune for your environment, see Configure automatic aggregations.
Benefits
With DirectQuery, each time a model user opens a report or interacts with a report visualization, Data Analysis Expressions (DAX) queries are passed to the query engine and then to the backend data source as SQL queries. The data source must calculate and return results for each query. Compared to import mode models stored in-memory, DirectQuery data source round trips can be both time and process intensive, often causing slow query response times in report visualizations.
When enabled for a DirectQuery model, automatic aggregations can boost report query performance by avoiding data source query round trips. Pre-aggregated query results are automatically returned by an in-memory aggregations cache rather than being sent to and returned by the data source. The amount of pre-aggregated data in the in-memory aggregations cache is a small fraction of the amount of data kept in fact and detail tables at the data source. The result isn't only better report query performance, but also reduced load on backend data source systems. With automatic aggregations, only a small portion of report and ad-hoc queries that require aggregations not included in the in-memory cache are passed to the backend data source, just like with pure DirectQuery mode.
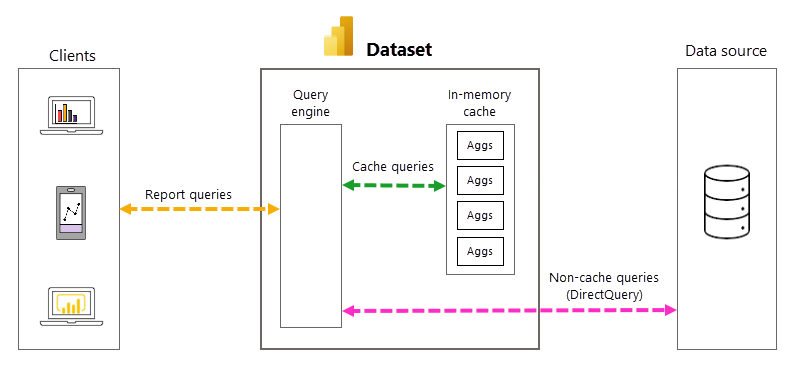
Automatic query and aggregations management
While automatic aggregations eliminate the need to create user-defined aggregation tables and dramatically simplify implementing a pre-aggregated data solution, a deeper familiarity with the underlying processes and dependencies is helpful in understanding how automatic aggregations work. Power BI relies on the following to create and manage automatic aggregations.
Query log
Power BI tracks model and user report queries in a query log. For each model, Power BI maintains seven days of query log data. Query log data is rolled forward each day. The query log is secure and not visible to users or through the XMLA endpoint.
Training operations
As part of the first scheduled model refresh operation for your selected frequency (Day or Week), Power BI first initiates a training operation that evaluates the query log to ensure aggregations in the in-memory aggregations cache adapt to changing query patterns. In-memory aggregation tables are created, updated, or dropped, and special queries are sent to the data source to determine aggregations to be included in the cache. Calculated aggregations data, however, isn't loaded into the in-memory cache during training - it's loaded during the subsequent refresh operation.
For example, if you choose a Day frequency and the schedule refreshes at 4:00AM, 9:00AM, 2:00PM, and 7:00PM, only the 4:00AM refresh each day will include both a training operation and a refresh operation. The subsequent 9:00AM, 2:00PM, and 7:00PM scheduled refreshes for that day are refresh only operations that update the existing aggregations in the cache.
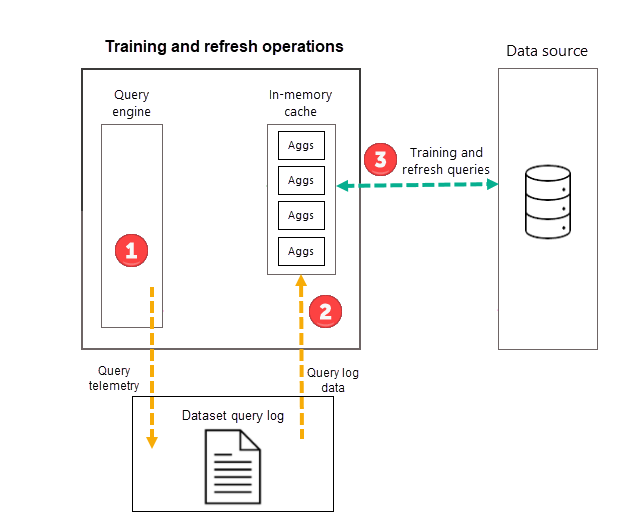
While training operations evaluate past queries from the query log, the results are sufficiently accurate to ensure future queries are covered. There's no guarantee however that future queries will be returned by the in-memory aggregations cache because those new queries could be different than those derived from the query log. Those queries not returned by the in-memory aggregations cache are passed to the data source by using DirectQuery. Depending on the frequency and ranking of those new queries, aggregations for them may be included in the in-memory aggregations cache with the next training operation.
The training operation has a 60-minute time limit. If training is unable to process the entire query log within the time limit, a notification is logged in the model Refresh history and training resumes the next time it's launched. The training cycle completes and replaces the existing automatic aggregations when the entire query log is processed.
Refresh operations
As described previously, after the training operation completes as part of the first scheduled refresh for your selected frequency, Power BI performs a refresh operation that queries and loads new and updated aggregations data into the in-memory aggregations cache and removes any aggregations that no longer rank high enough (as determined by the training algorithm). All subsequent refreshes for your chosen Day or Week frequency are refresh only operations that query the data source to update existing aggregations data in the cache. By using our previous example, the 9:00AM, 2:00PM, and 7:00PM scheduled refreshes for that day are refresh only operations.
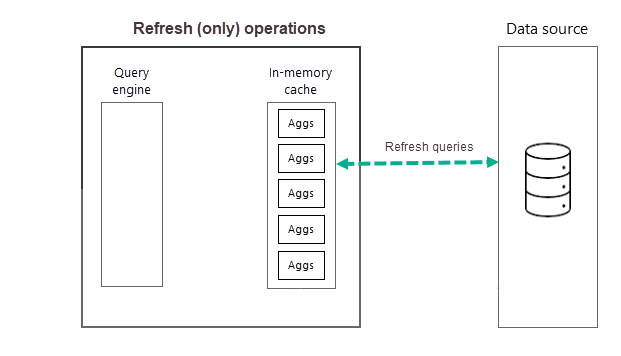
Regularly scheduled refreshes throughout the day (or week) ensure aggregations data in the cache are more up to date with data at the backend data source. Through model Settings, you can schedule up to 48 refreshes per day to ensure report queries that are returned by the aggregations cache are getting results based on the most recent refreshed data from the backend data source.
Caution
Training and refresh operations are process and resource intensive for both the Power BI service and the data source systems. Increasing the percentage of queries that use aggregations means more aggregations must be queried and calculated from data sources during training and refresh operations, increasing the probability of excessive use of system resources and potentially causing timeouts. To learn more, see Fine tuning.
Training on demand
As mentioned earlier, a training cycle may not complete within the time limits of a single data refresh cycle. If you don’t want to wait until the next scheduled refresh cycle that includes training, you can also trigger automatic aggregations training on-demand by selecting Train and Refresh Now in model Settings. By using Train and Refresh Now triggers both a training operation and a refresh operation. Check the model Refresh history to see if the current operation is finished before running another on-demand training and refresh operation, if necessary.
Refresh history
Each refresh operation is recorded in the model Refresh history. Important information about each refresh is shown, including the number of memory aggregations in the cache are consuming for the configured query percentage. To view refresh history, in the model Settings page, select Refresh history. If you want to drill down a little further, select Show details.
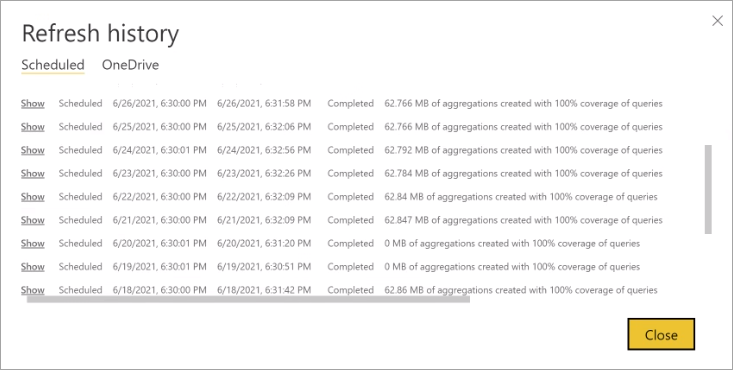
By regularly checking the refresh history you can ensure your scheduled refresh operations are completing within an acceptable period. Make sure refresh operations are successfully completing before the next scheduled refresh begins.
Training and refresh failures
While Power BI performs training and refresh operations as part of the first scheduled refresh for the day or week frequency you choose, these operations are implemented as separate transactions. If a training operation can't fully process the query log within its time limits, Power BI is going to proceed refreshing the existing aggregations (and regular tables in a composite model) using the previous training state. In this case, the refresh history will indicate the refresh succeeded and training is going to resume processing the query log the next time training launches. Query performance might be less optimized if client report query patterns changed and aggregations didn't adjust yet but the achieved performance level should still be far better than a pure DirectQuery model without any aggregations.
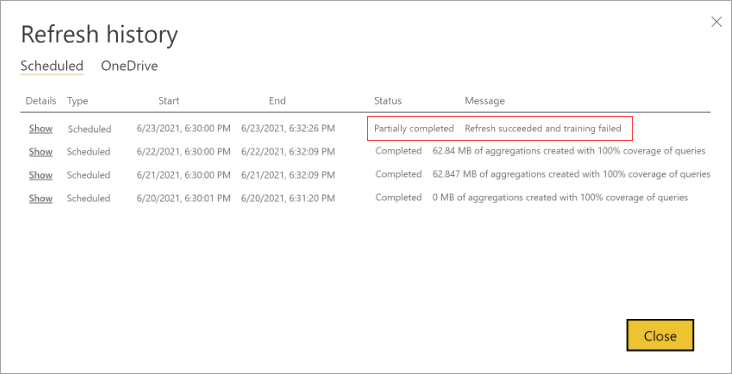
If a training operation requires too many cycles to finish processing the query log, consider reducing the percentage of queries that use the in-memory aggregations cache in model Settings. This will reduce the number of aggregations created in the cache, but allow more time for training and refresh operations to complete. To learn more, see Fine tuning.
If training succeeds but refresh fails, the entire refresh is marked as Failed because the result is an unavailable in-memory aggregations cache.
When scheduling refresh, you can specify email notifications if there are refresh failures.
User-defined and automatic aggregations
User-defined aggregations in Power BI can be manually configured based on hidden aggregated tables in the model. Configuring user-defined aggregations is often complex, requiring a greater level of data-modeling and query-optimization skills. Automatic aggregations on the other hand eliminate this complexity as part of an AI-driven system. Unlike user-defined aggregations that remain static, Power BI continuously maintains query logs and from those logs determines query patterns based on machine learning (ML) predictive modeling algorithms. Pre-aggregated data is calculated and stored in-memory based on query pattern analysis. With automatic aggregations, models are both self-training and self-optimizing. As client report query patterns change, automatic aggregations adjust, prioritizing and caching those aggregations used most often.
Because automatic aggregations are built on top of the existing user-defined aggregations infrastructure, it's possible to use both user-defined and automatic aggregations together in the same model. Skilled data modelers can define aggregations for tables using DirectQuery, Import (with or without Incremental refresh), or Dual storage modes, while at the same time having the benefits of more automatic aggregations for queries over DirectQuery connections that don’t hit the user-defined aggregation tables. This flexibility enables balanced architectures that can reduce query loads and avoid bottlenecks.
Aggregations created in the in-memory cache by the automatic aggregations training algorithm are identified as System aggregations. The training algorithm creates and deletes only those System aggregations as reporting queries are analyzed and adjustments are made to maintain the optimal aggregations for the model. Both user-defined and automatic aggregations are refreshed with refresh. Only those aggregations created by automatic aggregations and marked as system-generated aggregations are included in automatic aggregations processing.
Query caching and automatic aggregations
Power BI Premium also supports Query caching in Power BI Premium/Embedded to maintain query results. Query caching is a different feature from automatic aggregations. With query caching, Power BI Premium uses its local caching service to implement caching, whereas automatic aggregations are implemented at the model level. With query caching, the service only caches queries for the initial report page load, therefore query performance isn't improved when users interact with a report. In contrast, automatic aggregations optimize most report queries by pre-caching aggregated query results, including those queries generated when users interact with reports. Query caching and automatic aggregations can both be enabled for a model, but it's likely not necessary.
Monitor with Azure Log Analytics
Azure Log Analytics (LA) is a service within Azure Monitor which Power BI can use to save activity logs. With Azure Monitor suite, you can collect, analyze, and act on telemetry data from your Azure and on-premises environments. It offers long-term storage, an ad-hoc query interface, and API access to allow data export and integration with other systems. To learn more, see Using Azure Log Analytics in Power BI.
If Power BI is configured with an Azure LA account, as described in Configuring Azure Log Analytics for Power BI, you can analyze the success rate of your automatic aggregations. Among other things, you can determine if report queries are answered from the in-memory cache.
To use this ability, download the PBIT template and connect it to your log analytics account, as described in this Power BI blog post. In the report, you can view data at three different levels: Summary view, DAX query level view, and SQL query level view.
The following image shows the summary page for all the queries. As you can see, the marked chart shows the percentage of total queries that were satisfied by aggregations vs. the ones that had to utilize the data source.
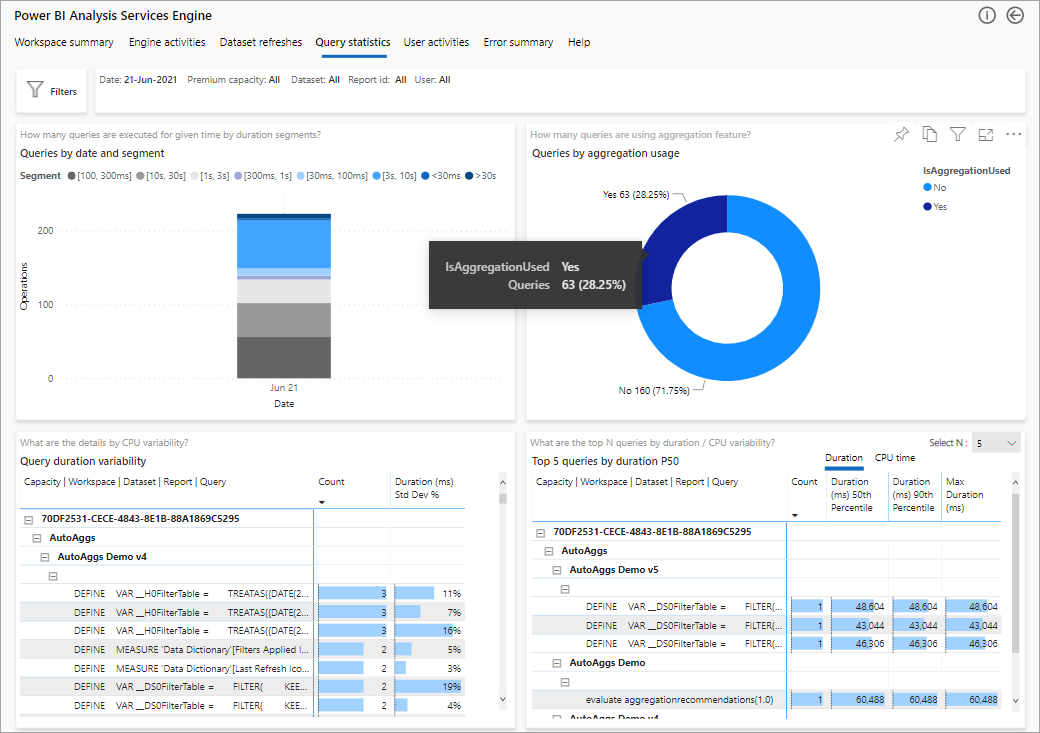
The next step to dive deeper is to look at the use of aggregations at a DAX query level. Right-click a DAX query from the list (bottom left) > Drill through > Query history.
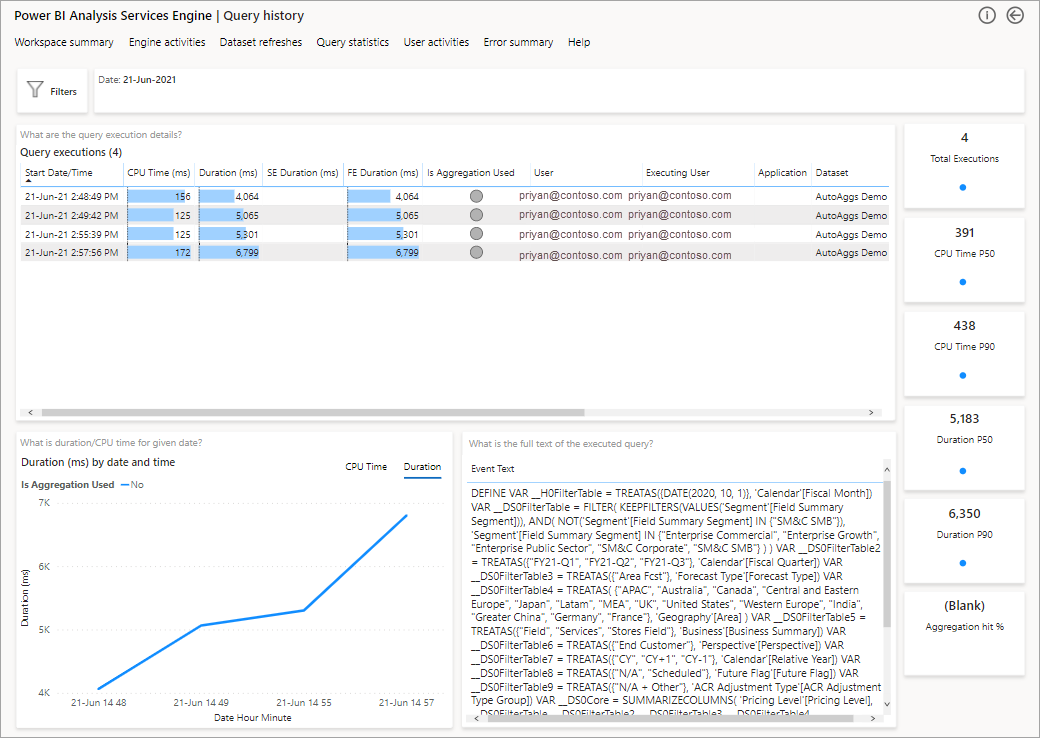
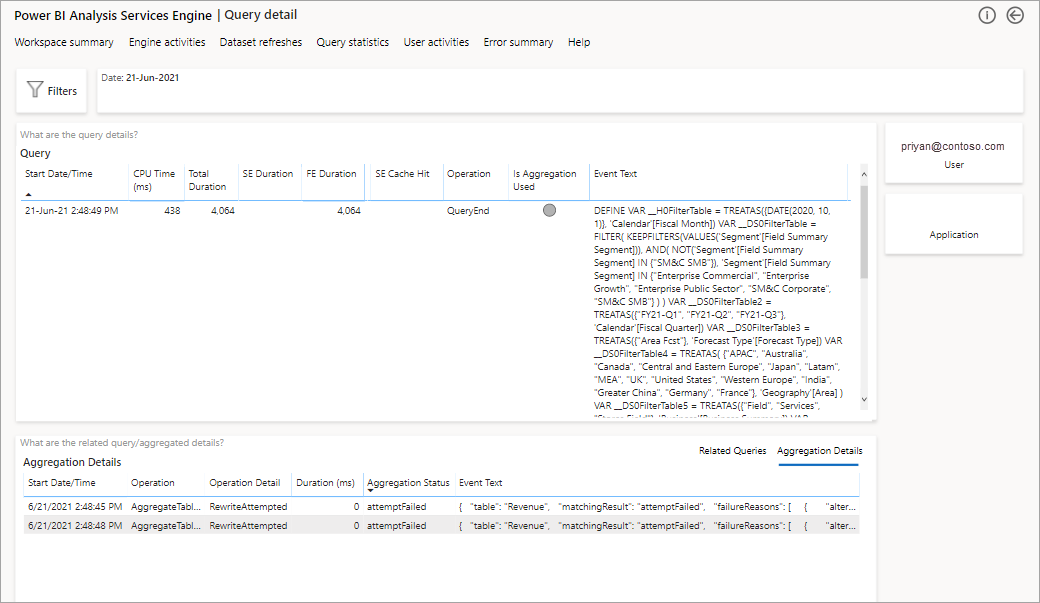
This will provide you with a list of all the pertinent queries. Drill through to the next level to show more aggregation details.
Application Lifecycle Management
From development to test and from test to production, models with automatic aggregations enabled have special requirements for ALM solutions.
Deployment pipelines
With deployment pipelines, Power BI can copy the models with their model configuration from the current stage into the target stage. However, automatic aggregations must be reset in the target stage as the settings do no get transferred from current to target stage. You can also deploy content programmatically, using the deployment pipelines REST APIs. To learn more about this process, see Automate your deployment pipeline using APIs and DevOps.
Custom ALM solutions
If you use a custom ALM solution based on XMLA endpoints, keep in mind that your solution might be able to copy system-generated and user-created aggregations tables as part of the model metadata. However, you must enable automatic aggregations after each deployment step at the target stage manually. Power BI will retain the configuration if you overwrite an existing model.
Note
If you upload or republish a model as part of a Power BI Desktop (.pbix) file, system-created aggregation tables are lost as Power BI replaces the existing model with all its metadata and data in the target workspace.
Altering a model
After altering a model with automatic aggregations enabled via XMLA endpoints, such as adding or removing tables, Power BI preserves any existing aggregations that can be and removes those that are no longer needed or relevant. Query performance could be impacted until the next training phase is triggered.
Metadata elements
Models with automatic aggregations enabled contain unique system-generated aggregations tables. Aggregations tables aren't visible to users in reporting tools. They're visible through the XMLA endpoint by using tools with Analysis Services client libraries version 19.22.5 and higher. When working with models with automatic aggregations enabled, be sure to upgrade your data modeling and administration tools to the latest version of the client libraries. For SQL Server Management Studio (SSMS), upgrade to SSMS version 18.9.2 or higher. Earlier versions of SSMS aren't able to enumerate tables or script out these models.
Automatic aggregations tables are identified by a SystemManaged table property, which is new to the Tabular Object Model (TOM) in Analysis Services client libraries version 19.22.5 and higher. The following code snippet shows the SystemManaged property set to true for automatic aggregations tables and false for regular tables.
using System;
using System.Collections.Generic;
using System.Linq;
using Microsoft.AnalysisServices.Tabular;
namespace AutoAggs
{
class Program
{
static void Main(string[] args)
{
string workspaceUri = "<Specify the URL of the workspace where your model resides>";
string datasetName = "<Specify the name of your dataset>";
Server sourceWorkspace = new Server();
sourceWorkspace.Connect(workspaceUri);
Database dataset = sourceWorkspace.Databases.GetByName(datasetName);
// Enumerate system-managed tables.
IEnumerable<Table> aggregationsTables = dataset.Model.Tables.Where(tbl => tbl.SystemManaged == true);
if (aggregationsTables.Any())
{
Console.WriteLine("The following auto aggs tables exist in this dataset:");
foreach (Table table in aggregationsTables)
{
Console.WriteLine($"\t{table.Name}");
}
}
else
{
Console.WriteLine($"This dataset has no auto aggs tables.");
}
Console.WriteLine("\n\rPress [Enter] to exit the sample app...");
Console.ReadLine();
}
}
}
Executing this snippet outputs automatic aggregations tables currently included in the model in a console.

Keep in mind, aggregations tables are constantly changing as training operations determine the optimal aggregations to include in the in-memory aggregations cache.
Important
Power BI fully manages automatic aggregations system-generated table objects. Do not delete or modify these tables yourself. Doing so can cause degraded performance.
Power BI maintains the model configuration outside of the model. The presence of a system-managed aggregations table in a model doesn't necessarily mean the model is in fact enabled for automatic aggregations training. In other words, if you script out a full model definition for a model with automatic aggregations enabled, and create a new copy of the model (with a different name/workspace/capacity), the new resulting model isn't enabled for automatic aggregations training. You still need to enable automatic aggregations training for the new model in model Settings.
Considerations and limitations
When using automatic aggregations, keep the following in mind:
- Aggregations do not support Dynamic M Query Parameters.
- The SQL queries generated during the initial training phase can generate significant load for the data warehouse. If training keeps finishing incomplete and you can verify on the data warehouse side that the queries are encountering a timeout, consider temporarily scaling up your data warehouse to meet the training demand.
- Aggregations stored in the in-memory aggregations cache may not be calculated on the most recent data at the data source. Unlike pure DirectQuery, and more like regular import tables, there's a latency between updates at the data source and aggregations data stored in the in-memory aggregations cache. While there will always be some degree of latency, it can be mitigated through an effective refresh schedule.
- To further optimize performance, set all dimension tables to Dual mode and leave fact tables in DirectQuery mode.
- Automatic aggregations aren't available with Power BI Pro, Azure Analysis Services, or SQL Server Analysis Services.
- Power BI doesn't support downloading models with automatic aggregations enabled. If you uploaded or published a Power BI Desktop (.pbix) file to Power BI and then enabled automatic aggregations, you can no longer download the PBIX file. Make sure you keep a copy of the PBIX file locally.
- Automatic aggregations with external tables in Azure Synapse Analytics isn't supported. You can enumerate external tables in Synapse by using the following SQL query:
SELECT SCHEMA_NAME(schema_id) AS schema_name, name AS table_name FROM sys.external_tables. - Automatic aggregations are only available for models using enhanced metadata. If you want to enable automatic aggregations for an older model, upgrade the model to enhanced metadata first. To learn more, see Using enhanced model metadata.
- Don't enable automatic aggregations if the DirectQuery data source is configured for single sign-on and uses dynamic data views or security controls to limit the data a user is allowed to access. Automatic aggregations aren't aware of these data source-level controls, which makes it impossible to ensure correct data is provided on a per user basis. Training will log a warning in the refresh history that it detected a data source configured for single sign-on and skipped the tables that use this data source. If possible, disable SSO for these data sources to take full advantage of the optimized query performance automatic aggregations can provide.
- Don't enable automatic aggregations if the model contains only hybrid tables to avoid unnecessary processing overhead. A hybrid table uses both import partitions and a DirectQuery partition. A common scenario is incremental refresh with real-time data in which a DirectQuery partition fetches transactions from the data source that occurred after the last data refresh. However, Power BI imports aggregations during refresh. Automatic aggregations can't include transactions that occurred after the last data refresh. Training will log a warning in the refresh history that it detected and skipped hybrid tables.
- Calculated columns aren't considered for automatic aggregations. If you use a calculated column in DirectQuery mode, such as by using the
COMBINEVALUESDAX function to create a relationship based on multiple columns from two DirectQuery tables, the corresponding report queries won't hit the in-memory aggregations cache. - Automatic aggregations are only available in the Power BI service. Power BI Desktop doesn't create system-generated aggregations tables.
- If you modify the metadata of a model with automatic aggregations enabled, query performance might degrade until the next training process is triggered. As a best practice, you should drop the automatic aggregations, make the changes, and then retrain.
- Don't modify or delete system-generated aggregations tables unless you have automatic aggregations disabled and are cleaning up the model. The system takes responsibility for managing these objects.
Community
Power BI has a vibrant community where MVPs, BI pros, and peers share expertise in discussion groups, videos, blogs and more. When learning about automatic aggregations, be sure to check out these other resources: