Events
Take the Microsoft Learn AI Skills Challenge
Sep 24, 11 PM - Nov 1, 11 PM
Elevate your skills in Microsoft Fabric and earn a digital badge by November 1.
Register nowThis browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
This article targets you as a data modeler working with Power BI Desktop. It provides you with guidance on when to create bi-directional model relationships. A bi-directional relationship is one that filters in both directions.
Note
An introduction to model relationships is not covered in this article. If you're not completely familiar with relationships, their properties or how to configure them, we recommend that you first read the Model relationships in Power BI Desktop article.
It's also important that you have an understanding of star schema design. For more information, see Understand star schema and the importance for Power BI.
Generally, we recommend minimizing the use of bi-directional relationships. They can negatively impact on model query performance, and possibly deliver confusing experiences for your report users.
There are three scenarios when bi-directional filtering can solve specific requirements:
Bi-directional relationships play an important role when creating the following two special model relationship types:
Bi-directional relationships can deliver slicers that limit items to where data exists. (If you're familiar with Excel PivotTables and slicers, it's the default behavior when sourcing data from a Power BI semantic model (previously known as a dataset), or an Analysis Services model.) To help explain what it means, first consider the following model diagram.
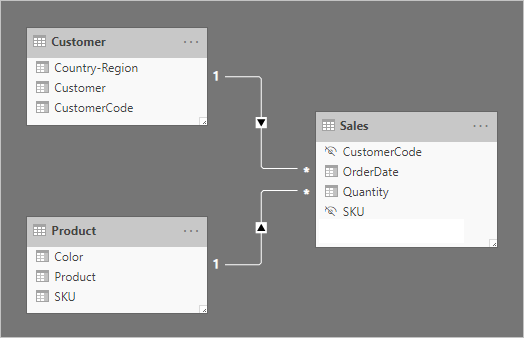
The first table is named Customer, and it contains three columns: Country-Region, Customer, and CustomerCode. The second table is named Product, and it contains three columns: Color, Product, and SKU. The third table is named Sales, and it contains four columns: CustomerCode, OrderDate, Quantity, and SKU. The Customer and Product tables are dimension-type tables, and each has a one-to-many relationship to the Sales table. Each relationship filters in a single direction.
To help describe how bi-directional filtering works, the model diagram has been modified to reveal the table rows. All examples in this article are based on this data.
Note
It's not possible to display table rows in the Power BI Desktop model diagram. It's done in this article to support the discussion with clear examples.
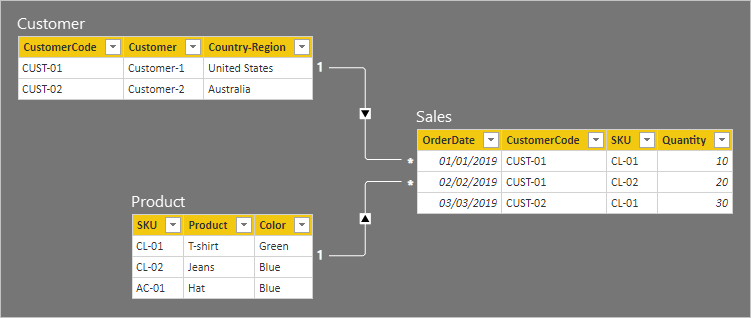
The row details for the three tables are described in the following bulleted list:
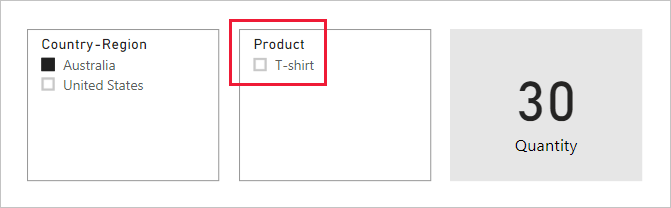
Now consider the following report page.
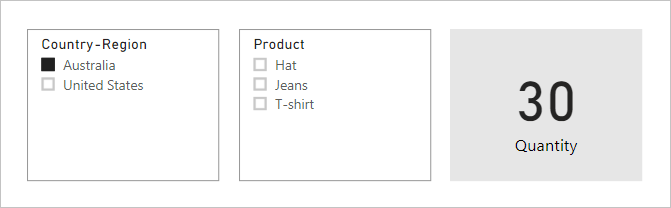
The page consists of two slicers and a card visual. The first slicer is for Country-Region and it has two items: Australia and United States. It currently slices by Australia. The second slicer is for Product, and it has three items: Hat, Jeans, and T-shirt. No items are selected (meaning no products are filtered). The card visual displays a quantity of 30.
When report users slice by Australia, you might want to limit the Product slicer to display items where data relates to Australian sales. It's what's meant by showing slicer items "with data". You can achieve this behavior by configuring the relationship between the Product and Sales table to filter in both directions.
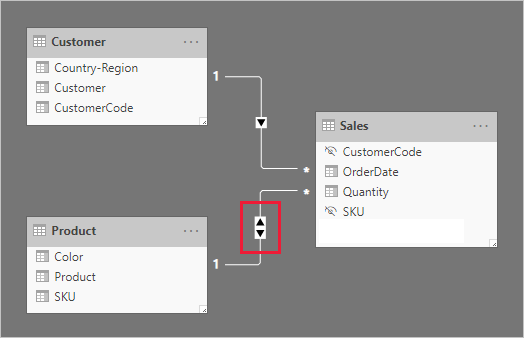
The Product slicer now lists a single item: T-shirt. This item represents the only product sold to Australian customers.
We first suggest you consider carefully whether this design works for your report users. Some report users find the experience confusing. They don't understand why slicer items dynamically appear or disappear when they interact with other slicers.
If you do decide to show slicer items "with data", we don't recommend you configure bi-directional relationships. Bi-directional relationships require more processing and so they can negatively impact on query performance—especially as the number of bi-directional relationships in your model increases.
There's a better way to achieve the same result: Instead of using bi-directional filters, you can apply a visual-level filter to the Product slicer itself.
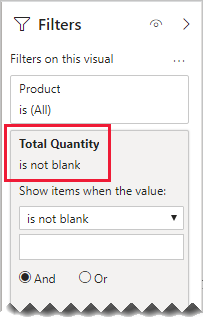
Let's now consider that the relationship between the Product and Sales table no longer filters in both directions. And, the following measure definition has been added to the Sales table.
Total Quantity = SUM(Sales[Quantity])
To show the Product slicer items "with data", it simply needs to be filtered by the Total Quantity measure using the "is not blank" condition.
A different scenario involving bi-directional relationships treats a fact-type table like a bridging table. This way, it supports analyzing dimension-type table data within the filter context of a different dimension-type table.
Using the example model in this article, consider how the following questions can be answered:
Both questions can be answered without summarizing data in the bridging fact-type table. They do, however, require that filters propagate from one dimension-type table to the other. Once filters propagate via the fact-type table, summarization of dimension-type table columns can be achieved using the DISTINCTCOUNT DAX function—and possibly the MIN and MAX DAX functions.
As the fact-type table behaves like a bridging table, you can follow the many-to-many relationship guidance to relate two dimension-type tables. It will require configuring at least one relationship to filter in both directions. For more information, see Many-to-many relationship guidance (Relate many-to-many dimensions).
However, as already described in this article, this design will likely result in a negative impact on performance, and the user experience consequences related to slicer items "with data". So, we recommend that you activate bi-directional filtering in a measure definition by using the CROSSFILTER DAX function instead. The CROSSFILTER function can be used to modify filter directions—or even disable the relationship—during the evaluation of an expression.
Consider the following measure definition added to the Sales table. In this example, the model relationship between the Customer and Sales tables has been configured to filter in a single direction.
Different Countries Sold =
CALCULATE(
DISTINCTCOUNT(Customer[Country-Region]),
CROSSFILTER(
Customer[CustomerCode],
Sales[CustomerCode],
BOTH
)
)
During the evaluation of the Different Countries Sold measure expression, the relationship between the Customer and Sales tables filters in both directions.
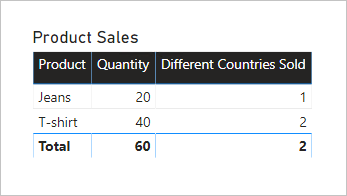
The following table visual present statistics for each product sold. The Quantity column is simply the sum of quantity values. The Different Countries Sold column represents the distinct count of country-region values of all customers who have purchased the product.
For more information related to this article, check out the following resources:
Events
Take the Microsoft Learn AI Skills Challenge
Sep 24, 11 PM - Nov 1, 11 PM
Elevate your skills in Microsoft Fabric and earn a digital badge by November 1.
Register nowTraining
Module
Design a semantic model in Power BI - Training
The process of creating a complicated semantic model in Power BI is straightforward. If your data is coming in from more than one transactional system, before you know it, you can have dozens of tables that you have to work with. Building a great semantic model is about simplifying the disarray. A star schema is one way to simplify a semantic model, and you learn about the terminology and implementation of them in this module. You will also learn about why choosing the correct data granularity is important
Certification
Microsoft Certified: Power BI Data Analyst Associate - Certifications
Demonstrate methods and best practices that align with business and technical requirements for modeling, visualizing, and analyzing data with Microsoft Power BI.