Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
APPLIES TO:  Machine Learning Studio (classic)
Machine Learning Studio (classic)  Azure Machine Learning
Azure Machine Learning
Important
Support for Machine Learning Studio (classic) will end on 31 August 2024. We recommend you transition to Azure Machine Learning by that date.
Beginning 1 December 2021, you will not be able to create new Machine Learning Studio (classic) resources. Through 31 August 2024, you can continue to use the existing Machine Learning Studio (classic) resources.
- See information on moving machine learning projects from ML Studio (classic) to Azure Machine Learning.
- Learn more about Azure Machine Learning
ML Studio (classic) documentation is being retired and may not be updated in the future.
To use your own data in Machine Learning Studio (classic) to develop and train a predictive analytics solution, you can use data from:
- Local file - Load local data ahead of time from your hard drive to create a dataset module in your workspace
- Online data sources - Use the Import Data module to access data from one of several online sources while your experiment is running
- Machine Learning Studio (classic) experiment - Use data that was saved as a dataset in Machine Learning Studio (classic)
- SQL Server database - Use data from a SQL Server database without having to copy data manually
Note
There are a number of sample datasets available in Machine Learning Studio (classic) that you can use for training data. For information on these, see Use the sample datasets in Machine Learning Studio (classic).
Prepare data
Machine Learning Studio (classic) is designed to work with rectangular or tabular data, such as text data that's delimited or structured data from a database, though in some circumstances non-rectangular data may be used.
It's best if your data is relatively clean before you import it into Studio (classic). For example, you'll want to take care of issues such as unquoted strings.
However, there are modules available in Studio (classic) that enable some manipulation of data within your experiment after you import your data. Depending on the machine learning algorithms you'll be using, you may need to decide how you'll handle data structural issues such as missing values and sparse data, and there are modules that can help with that. Look in the Data Transformation section of the module palette for modules that perform these functions.
At any point in your experiment, you can view or download the data that's produced by a module by clicking the output port. Depending on the module, there may be different download options available, or you may be able to visualize the data within your web browser in Studio (classic).
Supported data formats and data types
You can import a number of data types into your experiment, depending on what mechanism you use to import data and where it's coming from:
- Plain text (.txt)
- Comma-separated values (CSV) with a header (.csv) or without (.nh.csv)
- Tab-separated values (TSV) with a header (.tsv) or without (.nh.tsv)
- Excel file
- Azure table
- Hive table
- SQL database table
- OData values
- SVMLight data (.svmlight) (see the SVMLight definition for format information)
- Attribute Relation File Format (ARFF) data (.arff) (see the ARFF definition for format information)
- Zip file (.zip)
- R object or workspace file (.RData)
If you import data in a format such as ARFF that includes metadata, Studio (classic) uses this metadata to define the heading and data type of each column.
If you import data such as TSV or CSV format that doesn't include this metadata, Studio (classic) infers the data type for each column by sampling the data. If the data also doesn't have column headings, Studio (classic) provides default names.
You can explicitly specify or change the headings and data types for columns using the Edit Metadata module.
The following data types are recognized by Studio (classic):
- String
- Integer
- Double
- Boolean
- DateTime
- TimeSpan
Studio uses an internal data type called data table to pass data between modules. You can explicitly convert your data into data table format using the Convert to Dataset module.
Any module that accepts formats other than data table will convert the data to data table silently before passing it to the next module.
If necessary, you can convert data table format back into CSV, TSV, ARFF, or SVMLight format using other conversion modules. Look in the Data Format Conversions section of the module palette for modules that perform these functions.
Data capacities
Modules in Machine Learning Studio (classic) support datasets of up to 10 GB of dense numerical data for common use cases. If a module takes more than one input, the 10 GB value is the total of all input sizes. You can sample larger datasets by using queries from Hive or Azure SQL Database, or you can use Learning by Counts preprocessing before you import the data.
The following types of data can expand to larger datasets during feature normalization and are limited to less than 10 GB:
- Sparse
- Categorical
- Strings
- Binary data
The following modules are limited to datasets less than 10 GB:
- Recommender modules
- Synthetic Minority Oversampling Technique (SMOTE) module
- Scripting modules: R, Python, SQL
- Modules where the output data size can be larger than input data size, such as Join or Feature Hashing
- Cross-validation, Tune Model Hyperparameters, Ordinal Regression, and One-vs-All Multiclass, when the number of iterations is very large
For datasets that are larger than a couple GBs, upload the data to Azure Storage or Azure SQL Database, or use Azure HDInsight, rather than uploading directly from a local file.
You can find information about image data in the Import Images module reference.
Import from a local file
You can upload a data file from your hard drive to use as training data in Studio (classic). When you import a data file, you create a dataset module ready for use in experiments in your workspace.
To import data from a local hard drive, do the following:
- Click +NEW at the bottom of the Studio (classic) window.
- Select DATASET and FROM LOCAL FILE.
- In the Upload a new dataset dialog, browse to the file you want to upload.
- Enter a name, identify the data type, and optionally enter a description. A description is recommended - it allows you to record any characteristics about the data that you want to remember when using the data in the future.
- The checkbox This is the new version of an existing dataset allows you to update an existing dataset with new data. To do so, click this checkbox and then enter the name of an existing dataset.
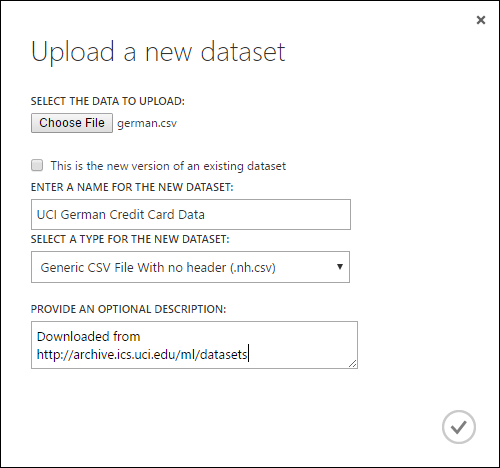
Upload time depends on the size of your data and the speed of your connection to the service. If you know the file will take a long time, you can do other things inside Studio (classic) while you wait. However, closing the browser before the data upload is complete causes the upload to fail.
Once your data is uploaded, it's stored in a dataset module and is available to any experiment in your workspace.
When you're editing an experiment, you can find the datasets you've uploaded in the My Datasets list under the Saved Datasets list in the module palette. You can drag and drop the dataset onto the experiment canvas when you want to use the dataset for further analytics and machine learning.
Import from online data sources
Using the Import Data module, your experiment can import data from various online data sources while the experiment running.
Note
This article provides general information about the Import Data module. For more detailed information about the types of data you can access, formats, parameters, and answers to common questions, see the module reference topic for the Import Data module.
By using the Import Data module, you can access data from one of several online data sources while your experiment is running:
- A Web URL using HTTP
- Hadoop using HiveQL
- Azure blob storage
- Azure table
- Azure SQL Database. SQL Managed Instance, or SQL Server
- A data feed provider, OData currently
- Azure Cosmos DB
Because this training data is accessed while your experiment is running, it's only available in that experiment. By comparison, data that has been stored in a dataset module is available to any experiment in your workspace.
To access online data sources in your Studio (classic) experiment, add the Import Data module to your experiment. Then select Launch Import Data Wizard under Properties for step-by-step guided instructions to select and configure the data source. Alternatively, you can manually select Data source under Properties and supply the parameters needed to access the data.
The online data sources that are supported are itemized in the table below. This table also summarizes the file formats that are supported and parameters that are used to access the data.
Important
Currently, the Import Data and Export Data modules can read and write data only from Azure storage created using the Classic deployment model. In other words, the new Azure Blob Storage account type that offers a hot storage access tier or cool storage access tier is not yet supported.
Generally, any Azure storage accounts that you might have created before this service option became available should not be affected. If you need to create a new account, select Classic for the Deployment model, or use Resource manager and select General purpose rather than Blob storage for Account kind.
For more information, see Azure Blob Storage: Hot and Cool Storage Tiers.
Supported online data sources
The Machine Learning Studio (classic) Import Data module supports the following data sources:
| Data Source | Description | Parameters |
|---|---|---|
| Web URL via HTTP | Reads data in comma-separated values (CSV), tab-separated values (TSV), attribute-relation file format (ARFF), and Support Vector Machines (SVM-light) formats, from any web URL that uses HTTP | URL: Specifies the full name of the file, including the site URL and the file name, with any extension. Data format: Specifies one of the supported data formats: CSV, TSV, ARFF, or SVM-light. If the data has a header row, it is used to assign column names. |
| Hadoop/HDFS | Reads data from distributed storage in Hadoop. You specify the data you want by using HiveQL, a SQL-like query language. HiveQL can also be used to aggregate data and perform data filtering before you add the data to Studio (classic). | Hive database query: Specifies the Hive query used to generate the data. HCatalog server URI : Specified the name of your cluster using the format <your cluster name>.azurehdinsight.net. Hadoop user account name: Specifies the Hadoop user account name used to provision the cluster. Hadoop user account password : Specifies the credentials used when provisioning the cluster. For more information, see Create Hadoop clusters in HDInsight. Location of output data: Specifies whether the data is stored in a Hadoop distributed file system (HDFS) or in Azure.
If you store your output data in Azure, you must specify the Azure storage account name, Storage access key and Storage container name. |
| SQL database | Reads data that is stored in Azure SQL Database, SQL Managed Instance, or in a SQL Server database running on an Azure virtual machine. | Database server name: Specifies the name of the server on which the database is running.
In case of a SQL server hosted on an Azure Virtual machine enter tcp:<Virtual Machine DNS Name>, 1433 Database name : Specifies the name of the database on the server. Server user account name: Specifies a user name for an account that has access permissions for the database. Server user account password: Specifies the password for the user account. Database query:Enter a SQL statement that describes the data you want to read. |
| On-premises SQL database | Reads data that is stored in a SQL database. | Data gateway: Specifies the name of the Data Management Gateway installed on a computer where it can access your SQL Server database. For information about setting up the gateway, see Perform advanced analytics with Machine Learning Studio (classic) using data from a SQL server. Database server name: Specifies the name of the server on which the database is running. Database name : Specifies the name of the database on the server. Server user account name: Specifies a user name for an account that has access permissions for the database. User name and password: Click Enter values to enter your database credentials. You can use Windows Integrated Authentication or SQL Server Authentication depending upon how your SQL Server is configured. Database query:Enter a SQL statement that describes the data you want to read. |
| Azure Table | Reads data from the Table service in Azure Storage. If you read large amounts of data infrequently, use the Azure Table Service. It provides a flexible, non-relational (NoSQL), massively scalable, inexpensive, and highly available storage solution. |
The options in the Import Data change depending on whether you are accessing public information or a private storage account that requires login credentials. This is determined by the Authentication Type which can have value of "PublicOrSAS" or "Account", each of which has its own set of parameters. Public or Shared Access Signature (SAS) URI: The parameters are:
Specifies the rows to scan for property names: The values are TopN to scan the specified number of rows, or ScanAll to get all rows in the table. If the data is homogeneous and predictable, it is recommended that you select TopN and enter a number for N. For large tables, this can result in quicker reading times. If the data is structured with sets of properties that vary based on the depth and position of the table, choose the ScanAll option to scan all rows. This ensures the integrity of your resulting property and metadata conversion.
Account key: Specifies the storage key associated with the account. Table name : Specifies the name of the table that contains the data to read. Rows to scan for property names: The values are TopN to scan the specified number of rows, or ScanAll to get all rows in the table. If the data is homogeneous and predictable, we recommend that you select TopN and enter a number for N. For large tables, this can result in quicker reading times. If the data is structured with sets of properties that vary based on the depth and position of the table, choose the ScanAll option to scan all rows. This ensures the integrity of your resulting property and metadata conversion. |
| Azure Blob Storage | Reads data stored in the Blob service in Azure Storage, including images, unstructured text, or binary data. You can use the Blob service to publicly expose data, or to privately store application data. You can access your data from anywhere by using HTTP or HTTPS connections. |
The options in the Import Data module change depending on whether you are accessing public information or a private storage account that requires login credentials. This is determined by the Authentication Type which can have a value either of "PublicOrSAS" or of "Account". Public or Shared Access Signature (SAS) URI: The parameters are:
File Format: Specifies the format of the data in the Blob service. The supported formats are CSV, TSV, and ARFF.
Account key: Specifies the storage key associated with the account. Path to container, directory, or blob : Specifies the name of the blob that contains the data to read. Blob file format: Specifies the format of the data in the blob service. The supported data formats are CSV, TSV, ARFF, CSV with a specified encoding, and Excel.
You can use the Excel option to read data from Excel workbooks. In the Excel data format option, indicate whether the data is in an Excel worksheet range, or in an Excel table. In the Excel sheet or embedded table option, specify the name of the sheet or table that you want to read from. |
| Data Feed Provider | Reads data from a supported feed provider. Currently only the Open Data Protocol (OData) format is supported. | Data content type: Specifies the OData format. Source URL: Specifies the full URL for the data feed. For example, the following URL reads from the Northwind sample database: https://services.odata.org/northwind/northwind.svc/ |
Import from another experiment
There will be times when you'll want to take an intermediate result from one experiment and use it as part of another experiment. To do this, you save the module as a dataset:
- Click the output of the module that you want to save as a dataset.
- Click Save as Dataset.
- When prompted, enter a name and a description that would allow you to identify the dataset easily.
- Click the OK checkmark.
When the save finishes, the dataset will be available for use within any experiment in your workspace. You can find it in the Saved Datasets list in the module palette.