Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Caution
Microsoft retired all classic eDiscovery experiences on August 31, 2025. This retirement includes classic Content Search, classic eDiscovery (Standard), and classic eDiscovery (Premium).
The guidance in this article only applies to organizations hosted in Microsoft 365 operated by 21Vianet (China). If your organization isn't hosted by 21Vianet, use the guidance for the new eDiscovery experience in the Microsoft Purview portal.
This article presents a quick start for using predictive coding in Microsoft Purview eDiscovery (Premium). The predictive coding module uses intelligent, machine learning capabilities to help you cull large volumes of case content that's not relevant to your investigation. This is accomplished by creating and training your own predictive coding models that help you prioritize the most relevant items for review.
Here's an a quick overview of the predictive coding process:

To get started, you create a model, label as few as 50 items as relevant or not relevant. The system then uses this training to apply prediction scores to every item in the review set. This lets you filter items based on the prediction score, which allows you to review the most relevant (or non-relevant) items first. If you want to train models with higher accuracies and recall rates, you can continue labeling items in subsequent training rounds until the model stabilizes. Once the model is stabilized, you can apply the final prediction filter to prioritize items to review.
For a detailed overview of predictive coding, see Learn about predictive coding in eDiscovery (Premium).
Step 1: Create a new predictive coding model
The first step is to create a new predictive coding model in the review set:
In the Microsoft Purview portal, open an eDiscovery (Premium) case and then select the Review sets tab.
Open a review set and then select Analytics > Manage predictive coding (preview).
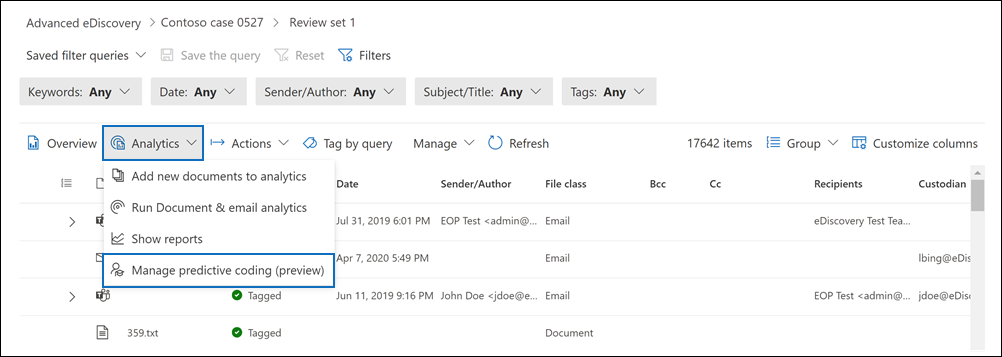
On the Predictive coding models (preview) page, select New model.
On the flyout page, type a name for the model and an optional description.
Select Save to create the model.
It will take a couple minutes for the system to prepare your model. After it's ready, you can perform the first round of training.
For more detailed instructions, see Create a predictive coding model.
Step 2: Perform the first training round
After you create the model, the next step is to complete the first training round by labeling items as relevant or not relevant.
Open the review set and then select Analytics > Manage predictive coding (preview).
On the Predictive coding models (preview) page, select the model that you want to train.
On the Overview tab, under Round 1, select Start next training round.
The Training tab is displayed and contains 50 items for you to label.
Review each document and then select Relevant or Not relevant at the bottom of the reading pane to label it.
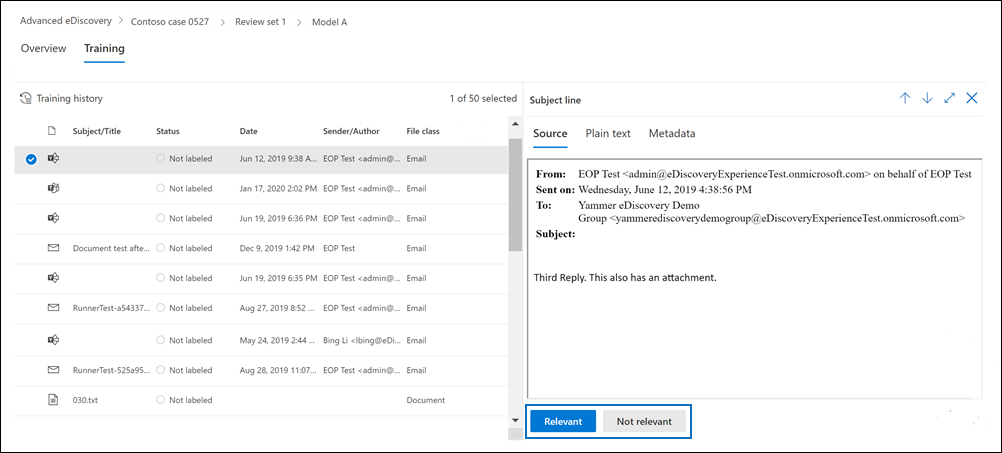
After you've labeled all 50 items, select Finish.
It will take a couple minutes for the system to "learn" from your labeling and update the model. When this process is complete, a status of Ready is displayed for the model on the Predictive coding models (preview) page.
For more detailed instructions, see Train a predictive coding model.
Step 3: Apply the prediction score filter to items in review set
After you perform at lease one training round, you can apply the prediction score filter to items in review set. This lets you review the items the model has predicted as relevant or not relevant.
Open the review set.
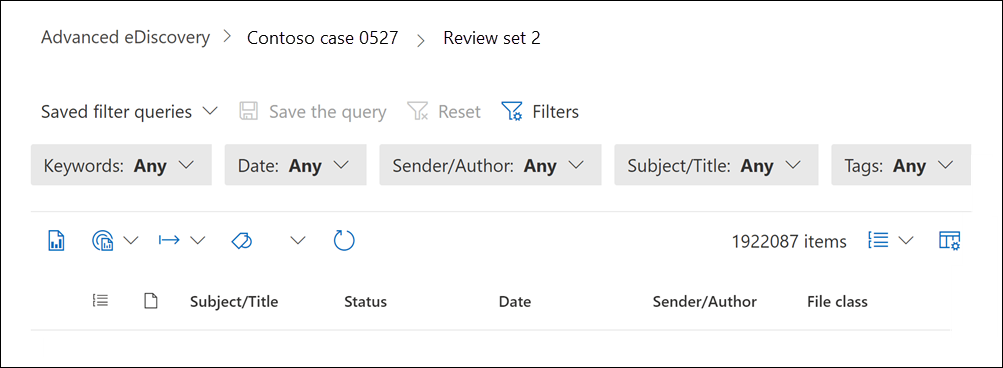
The pre-loaded default filters are displayed at the top of the review set page. You can leave these set to Any.
Select Filters to display the Filters flyout page.
Expand the Analytics & predictive coding section to display a set of filters.
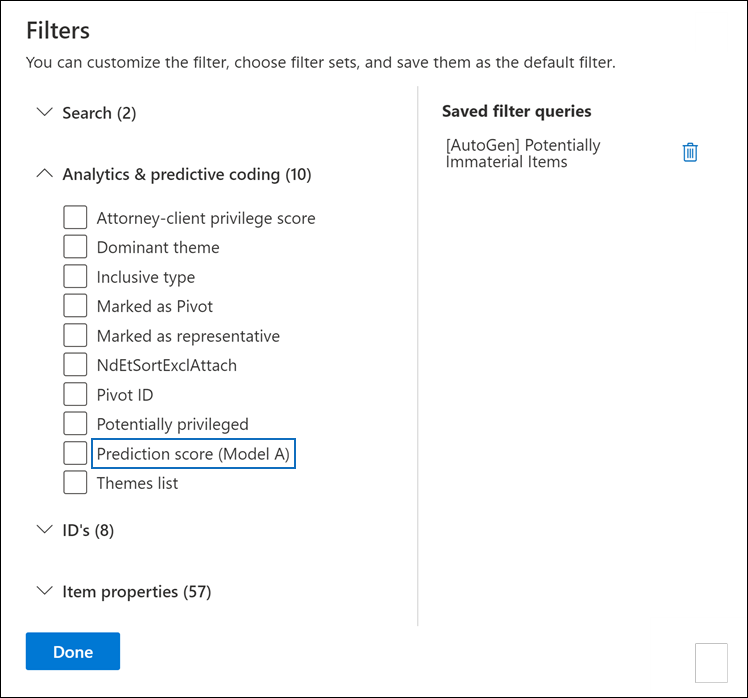
The naming convention for prediction score filters is Prediction score (model name). For example, the prediction score filter name for a model named Model A is Prediction score (Model A).
Select the prediction score filter that you want to use and then select Done.
On the review set page, select the dropdown for the prediction score filter and type minimum and maximum values for the prediction score range. For example, the following screenshot shows a prediction score range between .5 and 1.0.
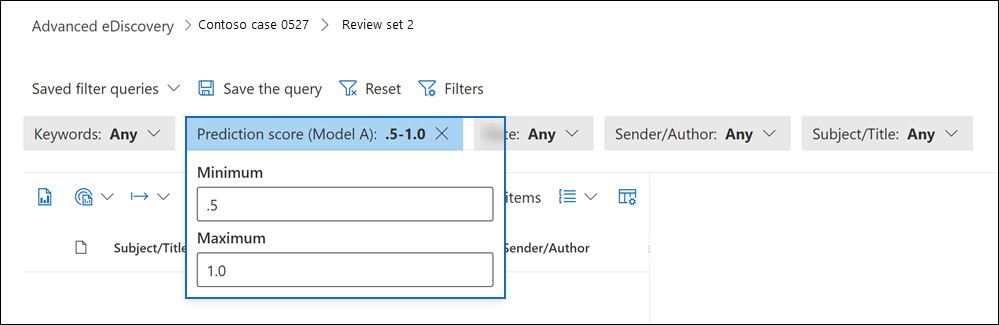
Select outside the filter to automatically apply the filter to the review set.
A list of documents with a prediction score within the range you specified is displayed on the review set page.
For more detailed instructions, see Apply a prediction filter to a review set.
Step 4: Perform more training rounds
More than likely, you'll have to perform more training rounds to train the module to better predict relevant and non-relevant items in the review set. In general, you'll train the model enough times until it stabilizes enough to meet your requirements.
For more information, see Perform additional training rounds
Step 5: Apply the final prediction score filter to prioritize review
Repeat the instructions in Step 3 to apply the final prediction score to the review set to prioritize the review of relevant and non-relevant items after you complete all the training rounds and stabilize the model.