Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Applies to: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
The Microsoft SQL Server 2019 Big Data Clusters is retired. Support for SQL Server 2019 Big Data Clusters ended as of February 28, 2025. For more information, see the announcement blog post and Big data options on the Microsoft SQL Server platform.
This article describes the role of SQL Server data pools in a SQL Server big data cluster. The following sections describe the architecture, functionality, and usage scenarios of a data pool.
This 5-minute video introduces data pools and shows you how to query data from data pools:
Data pool architecture
A data pool consists of one or more SQL Server data pool instances that provide persistent SQL Server storage for the cluster. It allows for performance querying of cached data against external data sources and offloading of work. Data is ingested into the data pool using either T-SQL queries or from Spark jobs. In order to enhanced performance across large data sets, the ingested data is distributed into shards and stored across all SQL Server instances in the pool. Supported distributions methods are round robin and replicated. For read access optimization, a clustered columnstore index is created on each table in each data pool instance. A data pool serves as the scale-out data mart for SQL Server Big Data Clusters.
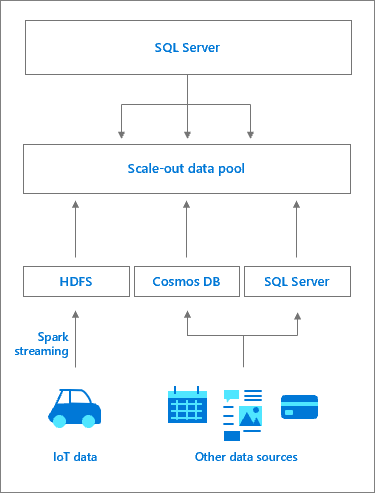
Access to the SQL server instances in the data pool is managed from the SQL Server master instance. An external data source to the data pool is created, along with the PolyBase external tables to store the data cache. In the background, the controller creates a database in the data pool with tables that match the external tables. From the SQL Server master instance the workflow is transparent; the controller redirects the specific external table requests to the SQL Server instances in the data pool, which may be through the compute pool, executes queries and returns the result set. Data in the data pool can only be ingested or queried and cannot be modified. Any data refreshes would therefore require a drop of the table, followed by table recreation and subsequent data repopulation.
Data pool scenarios
Reporting purposes is a common data pool scenario. For example, a complex query joining multiple PolyBase data sources, used for a weekly report, could be offloaded to the data pool. The cached data provides a local fast compute and eliminates the necessity to go back to original datasets. Likewise, dashboard data that requires periodically refreshing could be cached in the data pool for optimized reporting. Machine Learning repeat exploration can also benefit from caching of datasets in the data pool.
Next steps
To learn more about the SQL Server Big Data Clusters, see the following resources: