Big data options on the Microsoft SQL Server platform
Applies to: ![]() SQL Server 2019 (15.x) and later versions
SQL Server 2019 (15.x) and later versions
Microsoft SQL Server 2019 Big Clusters is an add-on for the SQL Server Platform that allows you to deploy scalable clusters of SQL Server, Spark, and HDFS containers running on Kubernetes. These components are running side by side to enable you to read, write, and process big data using Transact-SQL or Spark libraries, allowing you to easily combine and analyze your high-value relational data with non-relational high-volume big data. Big data clusters also allow you to virtualize data with PolyBase, so that you can query data from external SQL Server, Oracle, Teradata, MongoDB, and other data sources using external tables. The Microsoft SQL Server 2019 Big Clusters add-on provides high availability for the SQL Server master instance and all databases by using Always On availability group technology.
The SQL Server 2019 Big Data Clusters add-on runs on-premises and in the cloud using the Kubernetes platform, for any standard deployment of Kubernetes. Additionally, the SQL Server 2019 Big Data Clusters add-on integrates with Active Directory and includes role-based access control to satisfy security and compliance needs of your enterprise.
Retirement of the SQL Server 2019 Big Data Clusters add-on
On February 28, 2025, we will retire SQL Server 2019 Big Data Clusters. All existing users of SQL Server 2019 with Software Assurance will be fully supported on the platform and the software will continue to be maintained through SQL Server cumulative updates until that time. For more information, see the announcement blog post.
Changes to PolyBase support in SQL Server
Related to the SQL Server 2019 Big Data Clusters retirement are some features related to scale out queries.
The PolyBase scale-out groups feature of Microsoft SQL Server has been retired. Scale-out group functionality is removed from the product in SQL Server 2022 (16.x). In-market versions of SQL Server 2019, SQL Server 2017, and SQL Server 2016, continue to support the functionality to the end of life of those products. PolyBase data virtualization continues to be fully supported as a scale-up feature in SQL Server.
Cloudera (CDP) and Hortonworks (HDP) Hadoop external data sources will also be retired for all in-market versions of SQL Server and aren't included in SQL Server 2022. Support for external data sources is limited to product versions in mainstream support by the respective vendor. You are advised encouraged to use the new object storage integration available in SQL Server 2022 (16.x).
In SQL Server 2022 (16.x) and later versions, users must configure their external data sources to use new connectors when connecting to Azure Storage. The following table summarizes the change:
| External Data Source | From | To |
|---|---|---|
| Azure Blob Storage | wasb[s] |
abs |
| ADLS Gen 2 | abfs[s] |
adls |
Note
Azure Blob Storage (abs) will require usage of Shared Access Signature (SAS) for the SECRET in the database scoped credential. In SQL Server 2019 and earlier, the wasb[s] connector used Storage Account Key with database scoped credential when authenticating to Azure Storage account.
Understand the Big Data Clusters architecture for replacement and migration options
To create your replacement solution for a Big Data storage and processing system, it's important to understand what SQL Server 2019 Big Data Clusters provides, and its architecture can help inform your choices. The architecture of a big data cluster is as follows:

This architecture provides the following functionality mapping:
| Component | Benefit |
|---|---|
| Kubernetes | Open-source orchestrator for deploying and managing container-based applications at scale. Provides a declarative method to create and control resiliency, redundancy, and portability for the entire environment with elastic scale. |
| Big Data Clusters Controller | Provides management and security for the cluster. It contains the control service, the configuration store, and other cluster-level services such as Kibana, Grafana, and Elastic Search. |
| Compute Pool | Provides computational resources to the cluster. It contains nodes running SQL Server on Linux pods. The pods in the compute pool are divided into SQL Compute instances for specific processing tasks. This component also provides Data Virtualization using PolyBase to query external data sources without moving or copying the data. |
| Data Pool | Provides data persistence for the cluster. The data pool consists of one or more pods running SQL Server on Linux. It is used to ingest data from SQL queries or Spark jobs. |
| Storage Pool | The storage pool consists of storage pool pods comprised of SQL Server on Linux, Spark, and HDFS. All the storage nodes in a big data cluster are members of an HDFS cluster. |
| App Pool | Enables the deployment of applications on a big data cluster by providing interfaces to create, manage, and run applications. |
For more information on these functions, see Introducing SQL Server Big Data Clusters.
Functionality replacement options for Big Data and SQL Server
The operational data function facilitated by SQL Server inside the Big Data Clusters can be replaced by SQL Server on premises in a hybrid configuration or using the Microsoft Azure platform. Microsoft Azure offers a choice of fully managed relational, NoSQL, and in-memory databases, spanning proprietary and open-source engines, to fit the needs of modern app developers. Infrastructure management—including scalability, availability, and security—is automated, saving you time and money, and allows you to focus on building applications while Azure-managed databases make your job simpler by surfacing performance insights through embedded intelligence, scaling without limits, and managing security threats. For more information, see Azure databases.
The next decision point is the locations of compute and data storage for analytics. The two architecture choices are in-cloud and hybrid deployments. Most analytic workloads can be migrated to the Microsoft Azure platform. Data "born in the cloud" (originated in Cloud-based applications) are prime candidates for these technologies, and data movement services can migrate large-scale on-premises data securely and quickly. For more on data movement options, see Data transfer solutions.
Microsoft Azure has systems and certifications allowing secure data and data processing in various tools. For more information on these certifications, see the Trust Center.
Note
The Microsoft Azure platform provides a very high level of security, multiple certifications for various industries, and honors data sovereignty for government requirements. Microsoft Azure also has a dedicated cloud platform for government workloads. Security alone should not be the primary decision point for on-premises systems. You should carefully evaluate the level of security provided by Microsoft Azure before deciding to retain your big data solutions on-premises.
In the in-cloud architecture option, all components reside in Microsoft Azure. Your responsibility lies with the data and code you create for storage and processing of your workloads. Those options are covered in more detail in this article.
- This option works best for a wide variety of components for storage and processing of data, and when you want to focus on data and processing constructs rather than infrastructure.
In the hybrid architecture options, some components are retained on-premises and others are placed in a Cloud Provider. Connectivity between the two is designed for the best placement of processing-over-data.
- This option works best when you have a considerable investment in on-premises technologies and architectures, but you wish to use the offerings of Microsoft Azure, or when you have either processing and application targets residing on-premises or for a worldwide audience.
For more information on building scalable architectures, see Build a scalable system for massive data.
In-cloud
Azure SQL with Synapse
You can replace the functionality of SQL Server Big Data Clusters by using one or more Azure SQL database options for operational data, and Microsoft Azure Synapse for your analytic workloads.
Microsoft Azure Synapse is an enterprise analytics service that accelerates time to insight across data warehouses and big data systems, using distributed processing and data constructs. Azure Synapse brings together SQL technologies used in enterprise data warehousing, Spark technologies used for big data, Pipelines for data integration and ETL/ELT, and deep integration with other Azure services such as Power BI, Cosmos DB, and Azure Machine Learning.
Use Microsoft Azure Synapse as a replacement for SQL Server 2019 Big Data Clusters when you need to:
- Use both serverless and dedicated resource models. For predictable performance and cost, create dedicated SQL pools to reserve processing power for data stored in SQL tables.
- Process unplanned or "burst" workloads, access an always-available, serverless SQL endpoint.
- Use built-in streaming capabilities to land data from cloud data sources into SQL tables.
- Integrate AI with SQL by using machine learning models to score data using the T-SQL PREDICT function.
- Use ML models with SparkML algorithms and Azure Machine Learning integration for Apache Spark 2.4 supported for Linux Foundation Delta Lake.
- Use a simplified resource model that frees you from having to worry about managing clusters.
- Process data that requires fast Spark start-up and aggressive autoscaling.
- Process data using.NET for Spark allowing you to reuse your C# expertise and existing .NET code within a Spark application.
- Work with tables defined on files in the data lake, seamlessly consumed by either Spark or Hive.
- Use SQL with Spark to directly explore and analyze Parquet, CSV, TSV, and JSON files stored in a data lake.
- Enable fast, scalable data loading between SQL and Spark databases.
- Ingest data from 90+ data sources.
- Enable "Code-Free" ETL with Data flow activities.
- Orchestrate notebooks, Spark jobs, stored procedures, SQL scripts, and more.
- Monitor resources, usage, and users across SQL and Spark.
- Use Role-based access control to simplify access to analytics resources.
- Write SQL or Spark code and integrate with enterprise CI/CD processes.
The architecture of Microsoft Azure Synapse is as follows:

For more information on Microsoft Azure Synapse, see What is Azure Synapse Analytics?
Azure SQL plus Azure Machine Learning
You can replace the functionality of SQL Server Big Data Clusters by using one or more Azure SQL database options for operational data, and Microsoft Azure Machine Learning for your predictive workloads.
Azure Machine Learning is a cloud-based service that can be used for any kind of machine learning, from classical ML to deep learning, supervised, and unsupervised learning. Whether you prefer to write Python or R code with the SDK or work with no-code/low-code options in the studio, you can build, train, and track machine learning and deep-learning models in an Azure Machine Learning Workspace. With Azure Machine Learning, you can start training on your local machine and then scale out to the cloud. The service also interoperates with popular deep learning and reinforcement open-source tools such as PyTorch, TensorFlow, scikit-learn, and Ray RLlib.
Use Microsoft Azure Machine Learning as a replacement for SQL Server 2019 Big Data Clusters when you need:
- A designer-based web environment for Machine Learning: drag-n-drop modules to build your experiments and then deploy pipelines in a low-code environment.
- Jupyter notebooks: use our example notebooks or create your own notebooks to use our SDK for Python samples for your machine learning.
- R scripts or notebooks in which you use the SDK for R to write your own code or use the R modules in the designer.
- The Many Models Solution Accelerator builds on Azure Machine Learning and enables you to train, operate, and manage hundreds or even thousands of machine learning models.
- Machine learning extensions for Visual Studio Code (preview) provide you with a full-featured development environment for building and managing your machine learning projects.
- A Machine learning Command-Line Interface (CLI), Azure Machine Learning includes an Azure CLI extension that provides commands for managing with Azure Machine Learning resources from the command line.
- Integration with open-source frameworks such as PyTorch, TensorFlow, and scikit-learn and many more for training, deploying, and managing the end-to-end machine learning process.
- Reinforcement learning with Ray RLlib.
- MLflow to track metrics and deploy models or Kubeflow to build end-to-end workflow pipelines.
The architecture of a Microsoft Azure Machine Learning deployment is as follows:

For more information on Microsoft Azure Machine Learning, see How Azure Machine Learning works.
Azure SQL from Databricks
You can replace the functionality of SQL Server Big Data Clusters by using one or more Azure SQL database options for operational data, and Microsoft Azure Databricks for your analytic workloads.
Azure Databricks is a data analytics platform optimized for the Microsoft Azure cloud services platform. Azure Databricks offers two environments for developing data intensive applications: Azure Databricks SQL Analytics and Azure Databricks Workspace.
Azure Databricks SQL Analytics provides an easy-to-use platform for analysts who want to run SQL queries on their data lake, create multiple visualization types to explore query results from different perspectives, and build and share dashboards.
Azure Databricks Workspace provides an interactive workspace that enables collaboration between data engineers, data scientists, and machine learning engineers. For a big data pipeline, the data (raw or structured) is ingested into Azure through Azure Data Factory in batches, or streamed near real-time using Apache Kafka, Event Hubs, or IoT Hub. This data lands in a data lake for long term persisted storage, in Azure Blob Storage or Azure Data Lake Storage. As part of your analytics workflow, use Azure Databricks to read data from multiple data sources and turn it into breakthrough insights using Spark.
Use Microsoft Azure Databricks as a replacement for SQL Server 2019 Big Data Clusters when you need:
- Fully managed Spark clusters with Spark SQL and DataFrames.
- Streaming for real-time data processing and analysis for analytical and interactive applications, Integrating with HDFS, Flume, and Kafka.
- Access to the MLlib library, consisting of common learning algorithms and utilities, including classification, regression, clustering, collaborative filtering, dimensionality reduction, and underlying optimization primitives.
- Documentation of your progress in notebooks in R, Python, Scala, or SQL.
- Visualization of data in a few steps, using familiar tools like Matplotlib, ggplot, or d3.
- Interactive dashboards to create dynamic reports.
- GraphX, for Graphs and graph computation for a broad scope of use cases from cognitive analytics to data exploration.
- Cluster creation in seconds, with dynamic autoscaling clusters, sharing them across teams.
- Programmatic cluster access using REST APIs.
- Instant access to the latest Apache Spark features with each release.
- A Spark Core API: Includes support for R, SQL, Python, Scala, and Java.
- An interactive workspace for exploration and visualization.
- Fully managed SQL endpoints in the cloud.
- SQL queries that run on fully managed SQL endpoints sized according to query latency and number of concurrent users.
- Integration with Microsoft Entra ID (formerly Azure Active Directory).
- Role-based access for fine-grained user permissions for notebooks, clusters, jobs, and data.
- Enterprise-grade SLAs.
- Dashboards for sharing insights, combining visualizations and text to share insights drawn from your queries.
- Alerts help you monitor and integrate, and notification when a field returned by a query meets a threshold. Use alerts to monitor your business or integrate them with tools to start workflows such as user onboarding or support tickets.
- Enterprise security, including Microsoft Entra ID integration, role-based controls, and SLAs that protect your data and your business.
- Integration with Azure services and Azure databases and stores including Synapse Analytics, Cosmos DB, Data Lake Store, and Blob storage.
- Integration with Power BI and other BI tools, such as Tableau Software.
The architecture of a Microsoft Azure Databricks deployment is as follows:
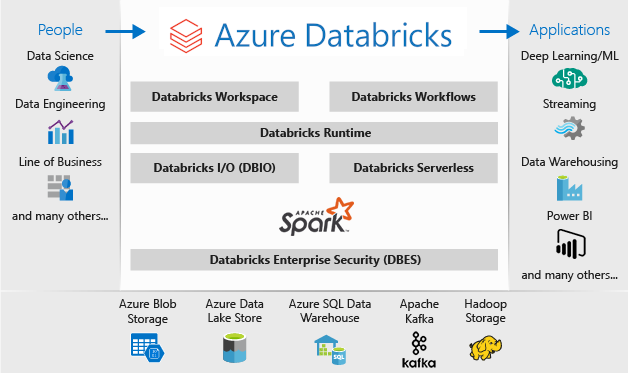
For more information on Microsoft Azure Databricks, see What is Databricks Data Science & Engineering?
Hybrid
Fabric Mirrored Database
As a data replication experience, Database Mirroring in Fabric (Preview) is a low-cost and low-latency solution to bring data from various systems together into a single analytics platform. You can continuously replicate your existing data estate directly into Fabric's OneLake, including data from Azure SQL Database, Snowflake, and Cosmos DB.
With the most up-to-date data in a queryable format in OneLake, you can now use all the different services in Fabric, such as running analytics with Spark, executing notebooks, data engineering, visualizing through Power BI Reports, and more.
Mirroring in Fabric provides an easy experience to speed the time-to-value for insights and decisions, and to break down data silos between technology solutions, without developing expensive Extract, Transform, and Load (ETL) processes to move data.
With Mirroring in Fabric, you don't need to piece together different services from multiple vendors. Instead, you can enjoy a highly integrated, end-to-end, and easy-to-use product that is designed to simplify your analytics needs, and built for openness and collaboration between technology solutions that can read the open-source Delta Lake table format.
For more information, see:
- Microsoft Fabric mirrored databases (Preview)
- Microsoft Fabric mirrored databases monitoring
- Explore data in your Mirrored database using Microsoft Fabric
- What is Microsoft Fabric?
- Model data in the default Power BI semantic model in Microsoft Fabric
- What is the SQL analytics endpoint for a Lakehouse?
- Direct Lake
Use SQL Server 2022 with Azure Synapse Link for SQL
SQL Server 2022 (16.x) contains a new feature that allows connectivity between SQL Server tables and the Microsoft Azure Synapse platform, the Azure Synapse Link for SQL. Azure Synapse Link for SQL Server 2022 (16.x) provides automatic change feeds that capture the changes within SQL Server and load them into Azure Synapse Analytics. It provides near real-time analysis and hybrid transactional and analytical processing with minimal impact on operational systems. Once the data is in Synapse, you can combine it with many different data sources regardless of their size, scale, or format and run powerful analytics over all of it using your choice of Azure Machine Learning, Spark, or Power BI. Since the automated change feeds only push what is new or different, data transfer happens much faster and now allows for near real-time insights, with minimal impact on the performance of the source database in SQL Server 2022 (16.x).
For your operational and even much of your analytic workloads, SQL Server can handle massive database sizes - for more information on maximum capacity specifications for SQL Server, see Compute capacity limits by edition of SQL Server. Using multiple SQL Server Instances on separate machines with partitioned T-SQL requests allow a scale-out environment for applications.
Using PolyBase enables your SQL Server instance to query data with T-SQL directly from SQL Server, Oracle, Teradata, MongoDB, and Cosmos DB without separately installing client connection software. You can also use the generic ODBC connector on a Microsoft Windows-based instance to connect to additional providers using third-party ODBC drivers. PolyBase allows T-SQL queries to join the data from external sources to relational tables in an instance of SQL Server. This allows the data to stay in its original location and format. You can virtualize the external data through the SQL Server instance, so that it can be queried in place like any other table in SQL Server. SQL Server 2022 (16.x) also allows ad hoc queries and backup/restore over Object-Store (using the S3-API) hardware or software storage options.
Two general reference architectures are to use SQL Server on a stand-alone server for structured data queries and a separate installation of a scale-out non-relational system (such as Apache Hadoop or Apache Spark) for on-premises Link to Synapse, and the other option is to use a set of containers in a Kubernetes cluster with all components for your solution.
Microsoft SQL Server on Windows, Apache Spark, and object storage on-premises
You can install SQL Server on Windows or Linux, and scale up the hardware architecture, using the SQL Server 2022 (16.x) object-storage query capability and the PolyBase feature to enable queries across all data in your system.
Installing and configuring a scale-out platform such as Apache Hadoop or Apache Spark allows for querying non-relational data at scale. Using a central set of Object-Storage systems that support the S3-API allows both SQL Server 2022 (16.x) and Spark to access the same set of data across all systems.
The Microsoft Apache Spark connector for SQL Server and Azure SQL also has that allow you to query data directly from SQL Server using Spark Jobs. For more information on the Apache Spark connector for SQL Server and Azure SQL, see Apache Spark connector: SQL Server & Azure SQL.
You can also use the Kubernetes container orchestration system for your deployment. This allows a declarative-architecture that can run on-premises or in any Cloud that supports Kubernetes or the Red Hat OpenShift platform. To learn more about deploying SQL Server into a Kubernetes environment, see Deploy a SQL Server container cluster on Azure or watch Deploying SQL Server 2019 in Kubernetes.
Use SQL Server and Hadoop/Spark on-premises as a replacement for SQL Server 2019 Big Data Clusters when you need to:
- Retain the entire solution on-premises
- Use dedicated hardware for all parts of the solution
- Access relational and non-relational data from the same architecture, in both directions
- Share a single set of non-relational data between SQL Server and the scale-out non-relational system
Perform the migration
Once you pick a location (In-Cloud or Hybrid) for your migration, you should weigh the downtime and cost vectors to determine whether you run a new system and move the data from the previous system to the new in real-time (side-by-side migration) or a backup and restore, or a new-start of the system from existing data sources (in-place migration).
Your next decision is to either rewrite the current functionality in your system using the new architecture choice or move as much of the code as possible to the new system. While the former choice can take longer, it allows you to use the new methods, concepts, and advantages that the new architecture provides. In that case, the data access and functionality maps are the primary planning efforts you should focus on.
If you plan to migrate the current system with as little code-change as possible, the language compatibility is your primary focus for planning.
Code migration
Your next step is to audit the code the current system uses and what changes it needs to run against the new environment.
There are two primary vectors for code migration to consider:
- Sources and sinks
- Functionality migration
Sources and sinks
The first task in code migration is to identify the data source connection methods, strings, or APIs that the code uses to access the data that is imported, its path, and its ultimate destination. Document those sources and create a map to the new architecture's locations.
- If the current solution is using a pipeline system to move the data through the system, map the new architecture sources, steps, and sinks to the pipeline's components.
- If the new solution is also replacing the pipeline architecture, treat the system as a new installation for planning purposes, even if you are reusing the hardware or cloud platform as the replacement.
Functionality migration
The most complex work needed in a migration is to reference, update, or create the documentation of the functionality of the current system. If you are planning an in-place upgrade and attempting to reduce the amount of code rewrite as much as possible, this step takes the most time.
However, a migration from a previous technology is often an optimal time to update yourself on the latest advancements in technology and take advantage of the constructs that it provides. Often you can gain more security, performance, feature choices and even cost optimizations by a rewrite of your current system.
In either case, you have two primary factors involved in the migration: the code and languages the new system supports, and the choices around data movement. Usually, you should be able to change connection strings from the current big data cluster to the SQL Server instance and Spark environment. Any data connection information and the code cutover should be minimal.
If you are envisioning a rewrite of your current functionality, map the new libraries, packages, and DLLs to the architecture you chose for your migration. You'll find a list of each of the libraries, languages, and functions that each solution offers in the documentation references shown in the previous sections. Map out any suspect or unsupported languages and plan for the replacement with the chosen architecture.
Data migration options
There are two common approaches for data movement in a large-scale analytic system. The first is to create a "cutover" process where the original system continues processing data, and that data is rolled up into a smaller set of aggregated report-data source. The new system then starts with fresh data and is used from the migration date onward.
In some cases, all data needs to move from the legacy system to the new system. In this case, you can mount the original file stores from SQL Server Big Data Clusters if the new system supports it and then copy the data piecewise to the new system, or you can create a physical move.
Migrating your current data from SQL Server 2019 Big Data Clusters to another system is highly dependent on two factors: the location of your current data, and the destination being on-premises or to-cloud.
On-premises data migration
For on-premises to on-premises migrations, you can migrate the SQL Server data with a backup and restore strategy, or you can set up replication to move some or all your relational data. SQL Server Integration Services can also be used to copy data from SQL Server to another location. For more information about moving data with SSIS, see SQL Server Integration Services.
For the HDFS data in your current SQL Server Big Data Cluster environment, the standard approach is to mount the data to a stand-alone Spark Cluster, and either use the Object Storage process to move the data so that a SQL Server 2022 (16.x) instance can access it or leave it as-is and continue to process it with Spark Jobs.
In-cloud data migration
For data located in cloud storage or on premises, you can use the Azure Data Factory, which has over 90 connectors for a full pipeline of transfer, with scheduling, monitoring, alerting, and other services. For more information on Azure Data Factory, see What is Azure Data Factory?
If you would like to move large amounts of data securely and quickly from your local data estate to Microsoft Azure, you can use the Azure Import/Export Service. The Azure Import/Export service is used to securely import large amounts of data to Azure Blob storage and Azure Files by shipping disk drives to an Azure datacenter. This service can also be used to transfer data from Azure Blob storage to disk drives and ship to your on-premises sites. Data from one or more disk drives can be imported either to Azure Blob storage or Azure Files. For extremely large amounts of data, using this service can be the fastest path.
If you want to transfer data using disk drives supplied by Microsoft, you can use Azure Data Box Disk to import data into Azure. For more information, see What is Azure Import/Export service?
For more information on these choices and the decisions that accompany them, see Using Azure Data Lake Storage Gen1 for big data requirements.
Related content
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for