Database files and filegroups
Applies to: ![]() SQL Server
SQL Server ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
At a minimum, every SQL Server database has two operating system files: a data file and a log file. Data files contain data and objects such as tables, indexes, stored procedures, and views. Log files contain the information that is required to recover all transactions in the database. Data files can be grouped together in filegroups for allocation and administration purposes.
Database files
SQL Server databases have three types of files, as shown in the following table.
| File | Description |
|---|---|
| Primary | Contains startup information for the database and points to the other files in the database. Every database has one primary data file. The recommended file name extension for primary data files is .mdf. |
| Secondary | Optional user-defined data files. Data can be spread across multiple disks by putting each file on a different disk drive. The recommended file name extension for secondary data files is .ndf. |
| Transaction Log | The log holds information used to recover the database. There must be at least one log file for each database. The recommended file name extension for transaction logs is .ldf. |
For example, a simple database named Sales has one primary file that contains all data and objects and a log file that contains the transaction log information. A more complex database named Orders can be created that includes one primary file and five secondary files. The data and objects within the database spread across all six files, and the four log files contain the transaction log information.
By default, the data and transaction logs are put on the same drive and path to handle single-disk systems. This choice might not be optimal for production environments. We recommend that you put data and log files on separate disks.
Logical and physical file names
SQL Server files have two file name types:
logical_file_name:Thelogical_file_nameis the name used to refer to the physical file in all Transact-SQL statements. The logical file name must comply with the rules for SQL Server identifiers and must be unique among logical file names in the database.os_file_name:Theos_file_nameis the name of the physical file including the directory path. It must follow the rules for the operating system file names.
For more information on the NAME and FILENAME argument, see ALTER DATABASE File and Filegroup Options (Transact-SQL).
Tip
SQL Server data and log files can be put on either FAT or NTFS file systems. On Windows systems, Microsoft recommends using the NTFS file system because the security aspects of NTFS.
Warning
Read/write data filegroups and log files are not supported on an NTFS compressed file system. Only read-only databases and read-only secondary filegroups are allowed to be put on an NTFS compressed file system. For space savings, it is highly recommended to use data compression instead of file system compression.
When multiple instances of SQL Server are running on a single computer, each instance receives a different default directory to hold the files for the databases created in the instance. For more information, see File Locations for Default and Named Instances of SQL Server.
Data file pages
Pages in a SQL Server data file are numbered sequentially, starting with zero (0) for the first page in the file. Each file in a database has a unique file ID number. To uniquely identify a page in a database, both the file ID and the page number are required. The following example shows the page numbers in a database that has a 4-MB primary data file and a 1-MB secondary data file.
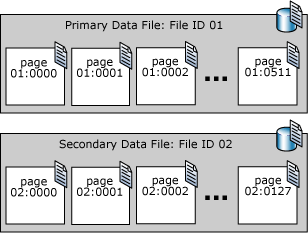
A file header page is the first page that contains information about the attributes of the file. Several of the other pages at the start of the file also contain system information, such as allocation maps. One of the system pages stored in both the primary data file and the first log file is a database boot page that contains information about the attributes of the database.
File Size
SQL Server files can grow automatically from their originally specified size. When you define a file, you can specify a specific growth increment. Every time the file is filled, it increases its size by the growth increment. If there are multiple files in a filegroup, they won't autogrow until all the files are full.
For more information about pages and page types, see Pages and Extents Architecture Guide.
Each file can also have a maximum size specified. If a maximum size isn't specified, the file can continue to grow until it has used all available space on the disk. This feature is especially useful when SQL Server is used as a database embedded in an application where the user doesn't have convenient access to a system administrator. The user can let the files autogrow as required to reduce the administrative burden of monitoring free space in the database and manually allocating additional space.
For more information on transaction log file management, see Manage the size of the transaction log file.
Database snapshot files
The form of file that is used by a database snapshot to store its copy-on-write data depends on whether the snapshot is created by a user or used internally:
- A database snapshot that is created by a user stores its data in one or more sparse files. Sparse file technology is a feature of the NTFS file system. At first, a sparse file contains no user data, and disk space for user data hasn't been allocated to the sparse file. For general information about the use of sparse files in database snapshots and how database snapshots grow, see View the Size of the Sparse File of a Database Snapshot.
- Database snapshots are used internally by certain DBCC commands. These commands include
DBCC CHECKDB,DBCC CHECKTABLE,DBCC CHECKALLOC, andDBCC CHECKFILEGROUP. An internal database snapshot uses sparse alternate data streams of the original database files. Like sparse files, alternate data streams are a feature of the NTFS file system. The use of sparse alternate data streams allows for multiple data allocations to be associated with a single file or folder without affecting the file size or volume statistics.
Filegroups
- The primary filegroup contains the primary data file and any secondary files that aren't put into other filegroups.
- User-defined filegroups can be created to group data files together for administrative, data allocation, and placement purposes.
For example: Data1.ndf, Data2.ndf, and Data3.ndf, can be created on three disk drives, respectively, and assigned to the filegroup fgroup1. A table can then be created specifically on the filegroup fgroup1. Queries for data from the table will be spread across the three disks; it will improve performance. The same performance improvement can be accomplished by using a single file created on a RAID (redundant array of independent disks) stripe set. However, files and filegroups let you easily add new files to new disks.
All data files are stored in the filegroups listed in the following table.
| Filegroup | Description |
|---|---|
| Primary | The filegroup that contains the primary file. All system tables are part of the primary filegroup. |
| Memory Optimized Data | A memory-optimized filegroup is based on filestream filegroup |
| Filestream | |
| User-defined | Any filegroup that is created by the user when the user first creates or later modifies the database. |
Default (primary) filegroup
When objects are created in the database without specifying which filegroup they belong to, they are assigned to the default filegroup. At any time, exactly one filegroup is designated as the default filegroup. The files in the default filegroup must be large enough to hold any new objects not allocated to other filegroups.
The PRIMARY filegroup is the default filegroup unless it is changed by using the ALTER DATABASE statement. Allocation for the system objects and tables remains within the PRIMARY filegroup, not the new default filegroup.
Memory-optimized data filegroup
For more information on memory-optimized filegroups, see Memory Optimized Filegroup.
FILESTREAM filegroup
For more information on FILESTREAM filegroups, see FILESTREAM and Create a FILESTREAM-Enabled Database.
File and filegroup example
The following example creates a database on an instance of SQL Server. The database has a primary data file, a user-defined filegroup, and a log file. The primary data file is in the primary filegroup and the user-defined filegroup has two secondary data files. An ALTER DATABASE statement makes the user-defined filegroup the default. A table is then created specifying the user-defined filegroup. (This example uses a generic path c:\Program Files\Microsoft SQL Server\MSSQL.1 to avoid specifying a version of SQL Server.)
USE master;
GO
-- Create the database with the default data
-- filegroup, filestream filegroup and a log file. Specify the
-- growth increment and the max size for the
-- primary data file.
CREATE DATABASE MyDB
ON PRIMARY
( NAME='MyDB_Primary',
FILENAME=
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_Prm.mdf',
SIZE=4MB,
MAXSIZE=10MB,
FILEGROWTH=1MB),
FILEGROUP MyDB_FG1
( NAME = 'MyDB_FG1_Dat1',
FILENAME =
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_FG1_1.ndf',
SIZE = 1MB,
MAXSIZE=10MB,
FILEGROWTH=1MB),
( NAME = 'MyDB_FG1_Dat2',
FILENAME =
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_FG1_2.ndf',
SIZE = 1MB,
MAXSIZE=10MB,
FILEGROWTH=1MB),
FILEGROUP FileStreamGroup1 CONTAINS FILESTREAM
( NAME = 'MyDB_FG_FS',
FILENAME = 'c:\Data\filestream1')
LOG ON
( NAME='MyDB_log',
FILENAME =
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB.ldf',
SIZE=1MB,
MAXSIZE=10MB,
FILEGROWTH=1MB);
GO
ALTER DATABASE MyDB
MODIFY FILEGROUP MyDB_FG1 DEFAULT;
GO
-- Create a table in the user-defined filegroup.
USE MyDB;
CREATE TABLE MyTable
( cola int PRIMARY KEY,
colb char(8) )
ON MyDB_FG1;
GO
-- Create a table in the filestream filegroup
CREATE TABLE MyFSTable
(
cola int PRIMARY KEY,
colb VARBINARY(MAX) FILESTREAM NULL
)
GO
The following illustration summarizes the results of the previous example (except for the Filestream data).

File and filegroup fill strategy
Filegroups use a proportional fill strategy across all the files within each filegroup. As data is written to the filegroup, the SQL Server Database Engine writes an amount proportional to the free space in the file to each file within the filegroup, instead of writing all the data to the first file until full. It then writes to the next file. For example, if file f1 has 100 MB free and file f2 has 200 MB free, one extent is given from file f1, two extents from file f2, and so on. In this way, both files become full at about the same time, and simple striping is achieved.
For example, a filegroup is made up of three files, all set to automatically grow. When space in all the files in the filegroup is exhausted, only the first file is expanded. When the first file is full and no more data can be written to the filegroup, the second file is expanded. When the second file is full and no more data can be written to the filegroup, the third file is expanded. If the third file becomes full and no more data can be written to the filegroup, the first file is expanded again, and so on.
Rules for designing files and filegroups
The following rules pertain to files and filegroups:
- A file or filegroup cannot be used by more than one database. For example, file
sales.mdfandsales.ndf, which contain data and objects from the sales database, can't be used by any other database. - A file can be a member of only one filegroup.
- Transaction log files are never part of any filegroups.
Recommendations
Recommendations when working with files and filegroups:
- Most databases will work well with a single data file and a single transaction log file.
- If you use multiple data files, create a second filegroup for the additional file and make that filegroup the default filegroup. In this way, the primary file will contain only system tables and objects.
- To maximize performance, create files or filegroups on different available disks as possible. Put objects that compete heavily for space in different filegroups.
- Use filegroups to enable placement of objects on specific physical disks.
- Put different tables used in the same join queries in different filegroups. This step will improve performance, because of parallel disk I/O searching for joined data.
- Put heavily accessed tables and the nonclustered indexes that belong to those tables on different filegroups. Using different filegroups will improve performance, because of parallel I/O if the files are located on different physical disks.
- Don't put the transaction log file(s) on the same physical disk that has the other files and filegroups.
- If you need to extend a volume or partition on which database files reside using tools like Diskpart, you should back up all system and user databases and stop SQL Server services first. Also, once disk volumes are extended successfully, you should consider running
DBCC CHECKDBcommand to ensure the physical integrity of all databases residing on the volume.
For more information on transaction log file management recommendations, see Manage the size of the transaction log file.
Related content
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for