SQL Graph Architecture
Applies to: ![]() SQL Server 2017 (14.x) and later
SQL Server 2017 (14.x) and later ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Learn about the architecture of SQL Graph. Knowing the basics make it easier to understand other SQL Graph articles.
SQL Graph database
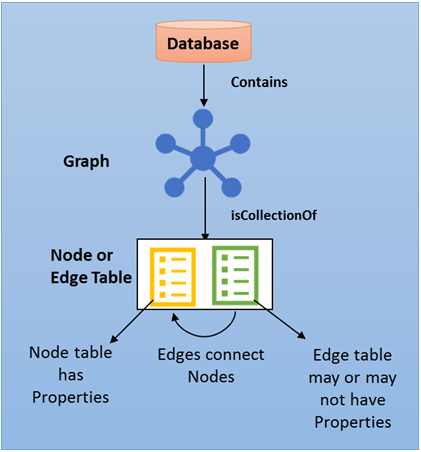
Users can create one graph per database. A graph is a collection of node and edge tables. Node or edge tables can be created under any schema in the database, but they all belong to one logical graph. A node table is collection of similar type of nodes. For example, a Person node table holds all the Person nodes belonging to a graph. Similarly, an edge table is a collection of similar type of edges. For example, a Friends edge table holds all the edges that connect a Person to another Person. Since nodes and edges are stored in tables, most of the operations supported on regular tables are supported on node or edge tables.
The following diagram shows the SQL Graph database architecture.
Node table
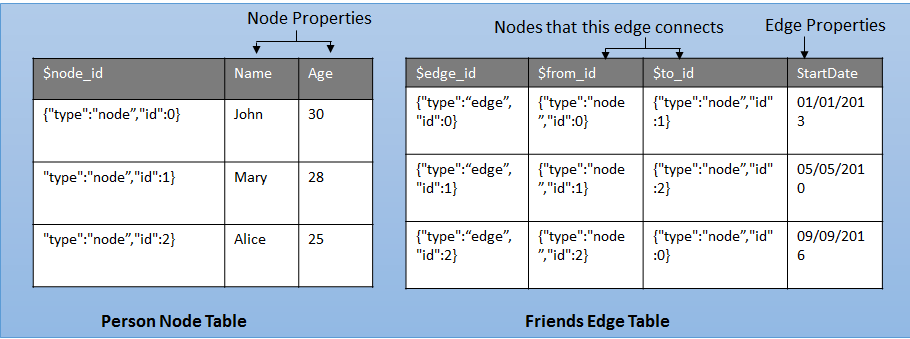
A node table represents an entity in a graph schema. Every time a node table is created, along with the user-defined columns, an implicit $node_id column is created, which uniquely identifies a given node in the database. The values in $node_id are automatically generated and are a combination of object ID for the graph table of that node table and an internally generated bigint value. However, when the $node_id column is selected, a computed value in the form of a JSON string is displayed. Also, $node_id is a pseudo-column that maps to an internal name with a unique suffix. When you select the $node_id pseudo-column from the table, the column name appears as $node_id_<unique suffix>.
Note
Using the pseudo-columns in queries is the only supported and recommended way of querying the internal $node_id column. You should not directly use the $node_id_<hex_string> columns in any queries.
Further, the computed JSON representation shown in the pseudo-columns, is an implementation detail. You should not take a direct dependency on the format of that JSON representation. If you must deal with this JSON representation, please consider using the NODE_ID_FROM_PARTS() and other related System Functions.
It's not recommended to directly use the graph pseudo-columns ($node_id, $from_id, $to_id) in predicates. For example, a predicate like n.$node_id = e.$from_id should be avoided. Such comparisons tend to be inefficient, due to the conversion to the JSON representation. Instead, rely on the MATCH function as far as possible.
It's recommended that users create a unique constraint or index on the $node_id column at the time of creation of node table, but if one isn't created, a default unique, nonclustered index is automatically created. However, any index on a graph pseudo-column is created on the underlying internal columns. That is, an index created on the $node_id column, appears on the internal graph_id_<hex_string> column.
Edge table
An edge table represents a relationship in a graph. Edges are always directed and connect two nodes. An edge table enables users to model many-to-many relationships in the graph. User defined columns ("attributes") are optional in an edge table. Every time an edge table is created, along with the user-defined columns, three implicit columns are created in the edge table:
| Column name | Description |
|---|---|
$edge_id |
Uniquely identifies a given edge in the database. It's a generated column and the value is a combination of object_id of the edge table and an internally generated bigint value. However, when the $edge_id column is selected, a computed value in the form of a JSON string is displayed. $edge_id is a pseudo-column that maps to an internal name with a unique suffix. When you select $edge_id from the table, the column name appears as $edge_id_<unique suffix>. Using pseudo-column names in queries is the recommended way of querying the internal $edge_id column and using internal name with hex string should be avoided. |
$from_id |
Stores the $node_id of the node, from where the edge originates. |
$to_id |
Stores the $node_id of the node, at which the edge terminates. |
The nodes that a given edge can connect to are controlled by the data inserted in the $from_id and $to_id columns. In the first release, it's not possible to define constraints on the edge table, to restrict it from connecting any two type of nodes. That is, an edge can connect any two nodes in the graph, regardless of their types.
Similar to the $node_id column, it's recommended that users create a unique index or constraint on the $edge_id column at the time of creation of the edge table, but if one isn't created, a default unique, nonclustered index is automatically created on this column. However, any index on a graph pseudo-column is created on the underlying internal columns. That is, an index created on the $edge_id column, appears on the internal graph_id_<unique suffix> column. It's also recommended, for OLTP scenarios, that users create an index on ($from_id, $to_id) columns, for faster lookups in the direction of the edge.
The following diagram shows how node and edge tables are stored in the database.
Metadata
Use these metadata views to see attributes of a node or edge table.
sys.tables
The following bit columns in sys.tables can be used to identify graph tables. If is_node is set to 1, the table is a node table, and if is_edge is set to 1, the table is an edge table.
| Column Name | Data Type | Description |
|---|---|---|
| is_node | bit | For node tables, is_node is set to 1. |
| is_edge | bit | For edge tables, is_edge is set to 1. |
sys.columns
The graph_type and graph_type_desc columns in the sys.columns view are useful in understanding the different types of columns used in graph node and edge tables:
| Column Name | Data Type | Description |
|---|---|---|
| graph_type | int | Internal column with a set of values. The values are between 1-8 for graph columns and NULL for others. |
| graph_type_desc | nvarchar(60) | Internal column with a set of values. |
The following table lists the valid values for graph_type column:
| Column Value | Description |
|---|---|
| 1 | GRAPH_ID |
| 2 | GRAPH_ID_COMPUTED |
| 3 | GRAPH_FROM_ID |
| 4 | GRAPH_FROM_OBJ_ID |
| 5 | GRAPH_FROM_ID_COMPUTED |
| 6 | GRAPH_TO_ID |
| 7 | GRAPH_TO_OBJ_ID |
| 8 | GRAPH_TO_ID_COMPUTED |
sys.columns also stores information about implicit columns created in node or edge tables. Following information can be retrieved from sys.columns, however, users can't select these columns from a node or edge table.
The implicit columns in a node table are:
| Column Name | Data Type | is_hidden | Comment |
|---|---|---|---|
graph_id_\<hex_string> |
BIGINT | 1 | Internal graph ID value. |
$node_id_\<hex_string> |
NVARCHAR | 0 | External, character representation of the node ID. |
The implicit columns in an edge table are:
| Column Name | Data Type | is_hidden | Comment |
|---|---|---|---|
graph_id_\<hex_string> |
BIGINT | 1 | Internal graph ID value. |
$edge_id_\<hex_string> |
NVARCHAR | 0 | Character representation of the edge ID. |
from_obj_id_\<hex_string> |
INT | 1 | Internal object_id value for the "from node." |
from_id_\<hex_string> |
BIGINT | 1 | Internal graph ID value for the "from node." |
$from_id_\<hex_string> |
NVARCHAR | 0 | character representation of the "from node." |
to_obj_id_\<hex_string> |
INT | 1 | Internal object_id for the "to node." |
to_id_\<hex_string> |
BIGINT | 1 | Internal graph ID value for the "to node." |
$to_id_\<hex_string> |
NVARCHAR | 0 | External, character representation of the "to node." |
System functions
You can use the following built-in functions to interact with the pseudo-columns in graph tables. Detailed references are provided for each of these functions in the respective T-SQL function references.
| Built-in | Description |
|---|---|
| OBJECT_ID_FROM_NODE_ID | Extract the object ID for the graph table from a node_id. |
| GRAPH_ID_FROM_NODE_ID | Extract the graph ID value from a node_id. |
| NODE_ID_FROM_PARTS | Construct a node_id from an object ID for the graph table and a graph ID value. |
| OBJECT_ID_FROM_EDGE_ID | Extract object ID for the graph table from edge_id. |
| GRAPH_ID_FROM_EDGE_ID | Extract the graph ID value for a given edge_id. |
| EDGE_ID_FROM_PARTS | Construct edge_id from object ID for the graph table and graph ID value. |
Transact-SQL reference
Learn the Transact-SQL extensions introduced in SQL Server and Azure SQL Database that enable creating and querying graph objects. The query language extensions help query and traverse the graph using ASCII art syntax.
Data Definition Language (DDL) statements
| Task | Related Article | Notes |
|---|---|---|
| CREATE TABLE | CREATE TABLE (Transact-SQL) | CREATE TABLE is now extended to support creating a table AS NODE or AS EDGE. An edge table isn't required to have any user-defined attributes. |
| ALTER TABLE | ALTER TABLE (Transact-SQL) | Node and edge tables can be altered the same way a relational table is, using the ALTER TABLE. Users can add or modify user-defined columns, indexes or constraints. However, altering internal graph columns, like $node_id or $edge_id, results in an error. |
| CREATE INDEX | CREATE INDEX (Transact-SQL) | Users can create indexes on pseudo-columns and user-defined columns in node and edge tables. All index types are supported, including clustered and nonclustered columnstore indexes. |
| CREATE EDGE CONSTRAINTS | EDGE CONSTRAINTS (Transact-SQL) | Users can now create edge constraints on edge tables to enforce specific semantics and also maintain data integrity |
| DROP TABLE | DROP TABLE (Transact-SQL) | Node and edge tables can be dropped the same way a relational table is, using the DROP TABLE. Currently, there are no mechanisms to prevent deleting nodes, which are referenced by edges. There's no support for cascaded deletion of edges, upon deletion of a node (or dropping the entire node table). In all such cases, any edges connected to the deleted nodes must be deleted manually, to maintain the consistency of the graph. |
Data Manipulation Language (DML) statements
| Task | Related Article | Notes |
|---|---|---|
| INSERT | INSERT (Transact-SQL) | Inserting into a node table is no different than inserting into a relational table. The values for $node_id column are automatically generated. Trying to insert a value in $node_id or $edge_id column results in an error. Users must provide values for $from_id and $to_id columns while inserting into an edge table. $from_id and $to_id are the $node_id values of the nodes that a given edge connects. |
| DELETE | DELETE (Transact-SQL) | Data from node or edge tables can be deleted in same way as it's deleted from relational tables. However, in this release, there are no constraints to ensure that no edges point to a deleted node and cascaded deletion of edges, upon deletion of a node isn't supported. It's recommended that whenever a node is deleted, all the connecting edges to that node are also deleted. |
| UPDATE | UPDATE (Transact-SQL) | Values in user-defined columns can be updated using the UPDATE statement. You can't update the internal graph columns, $node_id, $edge_id, $from_id and $to_id. |
| MERGE | MERGE (Transact-SQL) | MERGE statement is supported on a node or edge table. |
Query Statements
| Task | Related Article | Notes |
|---|---|---|
| SELECT | SELECT (Transact-SQL) | Because nodes and edges are stored as tables, most table operations are also supported on node and edge tables. |
| MATCH | MATCH (Transact-SQL) | MATCH built-in is introduced to support pattern matching and traversal through the graph. |
Limitations
There are certain limitations on node and edge tables:
- Local or global temporary tables can't be node or edge tables.
- Table types and table variables can't be declared as a node or edge table.
- Node and edge tables can't be created as system-versioned temporal tables.
- Node and edge tables can't be memory optimized tables.
- Users can't update the
$from_idand$to_idcolumns of an edge using UPDATE statement. To update nodes that are referenced by an edge, users have to insert a new edge pointing to new nodes, and delete the previous one. - Cross database queries on graph objects aren't supported.
- Graph pseudo-columns (
node_id,$from_id,$to_idandedge_id) can't be used as the sort columns for an ordered clustered columnstore index. Attempting to use any graph pseudo-columns as the sort columns for ordered clustered columnstore results in anMsg 102: Incorrect syntaxerror.
See also
Next steps
- To get started with SQL Graph, see SQL Graph Database - Sample
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for