Synchronize data on Azure SQL Database with SQL Data Sync
Scenario
As the CTO of our healthcare company, you might decide to build a solution that automatically synchronizes data bidirectionally between your national and regional inventory databases. For such a use case, SQL Data Sync might be a great solution.
How it works
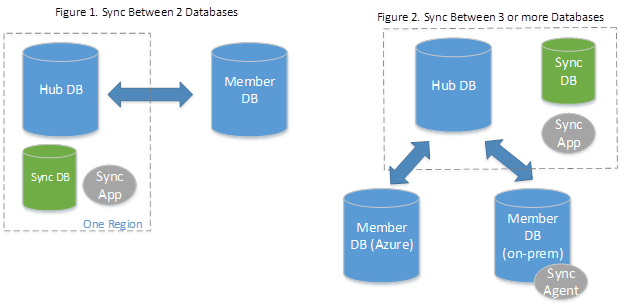
SQL Data Sync is a service built on Azure SQL Database that lets you synchronize the data you select bidirectionally across multiple databases, both on-premises (SQL Server) and in the cloud (Azure SQL Database). Data Sync is based around the concept of a sync group. A sync group is a group of databases that you want to synchronize using a hub and spoke topology. You'll define one of the databases in the sync group as the hub database, while the rest of the databases are member databases.
Within a sync group:
The hub database must be an Azure SQL Database.
The member databases can be either databases in Azure SQL Database or in instances of SQL Server.
The Sync Metadata Database contains the metadata and log for Data Sync; it has to be an Azure SQL Database located in the same region as the hub database. The Sync Metadata Database is customer created and customer owned, and you can only have one Sync Metadata Database per region and subscription. The Sync Metadata Database cannot be deleted or renamed while sync groups or sync agents exist.
Additionally, a sync group has the following properties:
- The Sync schema describes which data is being synchronized. For synchronization, you can select specific columns within your tables. Bear in mind that tables selected for synchronization must have a primary key (PK).
- The Sync direction can be bidirectional or can flow in only one direction; that is, the Sync direction can be hub to member, member to hub, or both.
- The Sync interval describes how often synchronization occurs. You can configure sync to run synchronization automatically (for example, every few seconds up to every 30 days) or manually on demand.
- The Conflict Resolution Policy is a group-level policy, which can be hub wins or member wins.
Using SQL Data Sync
SQL Data Sync tracks changes using insert, update, and delete triggers. The changes are recorded in a side table in the user's database. During the sync process, the hub database syncs with each member individually within a sync group. More specifically, changes from the hub are downloaded to the member, and then changes from the member are uploaded to the hub. If a conflict occurs during the synchronization process, SQL Data Sync provides two options for conflict resolution: Hub wins or Member wins. If the user selects Hub wins, the changes in the hub always overwrite changes in the member. If the user selects Member wins, the changes in the member overwrite changes in the hub. If there's more than one member, the final value depends on which member syncs first.
Additionally, the private link for SQL Data Sync allows you to choose a service-managed private endpoint to establish a secure connection between the sync service and your member/hub databases during the data synchronization process. A service-managed private endpoint is a private IP address within a specific virtual network and subnet. Within Data Sync, the service-managed private endpoint is created by Microsoft and is exclusively used by the Data Sync service for a given sync operation. Currently, the service-managed private endpoint must be manually approved in order for the sync group to be created. Additionally, when using the SQL Data Sync private link, both the hub and member databases must be hosted in Azure (same or different regions) and in the same cloud type (for example, both in public cloud or both in government cloud).
User interface options
You can use SQL Data Sync through the Azure portal, PowerShell, or REST API.
Key use cases
SQL Data Sync is useful in cases where data needs to be kept updated across several databases in Azure SQL Database or SQL Server. Here are the main use cases for Data Sync:
- Hybrid Data Synchronization: With Data Sync, you can keep data synchronized between your databases in SQL Server and Azure SQL Database to enable hybrid applications. This capability might appeal to customers who are considering moving to the cloud and would like to put some of their applications in Azure.
- Distributed Applications: In many cases, it's beneficial to separate different workloads across different databases. For example, if you have a large production database and need to run a reporting or analytics workload on this data, it's helpful to have a second database for the additional workload. This approach minimizes the performance impact on your production workload. You can use Data Sync to keep these two databases synchronized.
- Globally Distributed Applications: Many businesses span several countries/regions. To minimize network latency, it's best to have your data in a region close to you. With Data Sync, you can easily keep databases in regions around the world synchronized.