Clean data quality issues
Now that we addressed the duplicate records in the system, we need to fix the data quality issues that we detected when we looked at the raw data.
For this task, we use the CluedIn data steward tool: CluedIn Clean.
In CluedIn, in the left hand menu, select Preparation -> Clean.
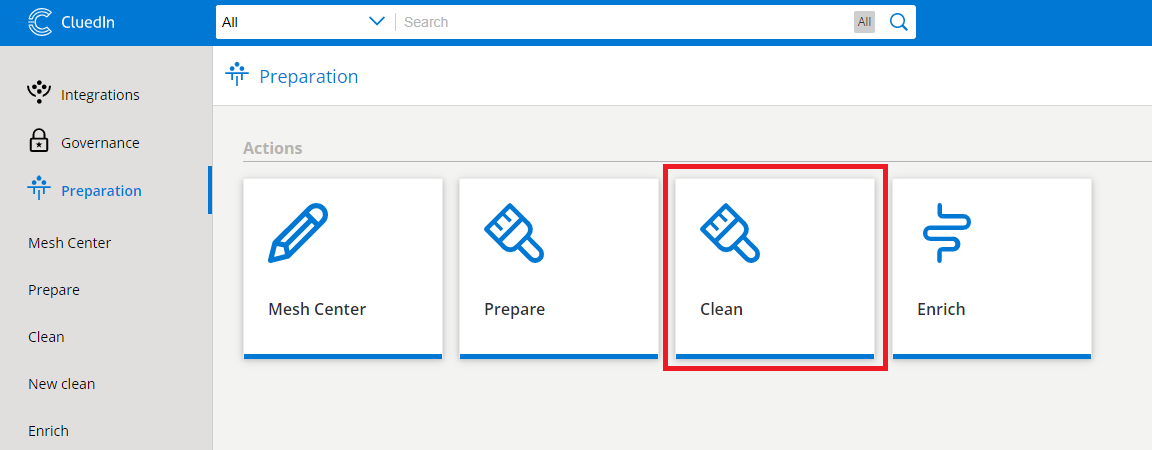
Select Create Project and choose the entity type. For this example, we choose Employee.
In the new cleaning project, select Create new clean project.
1.When finished, select the new clean project from the menu. This launches a studio in a new tab with your employee records.
On the employee.job header, select the drop-down, select Facet, and select Text Facet.
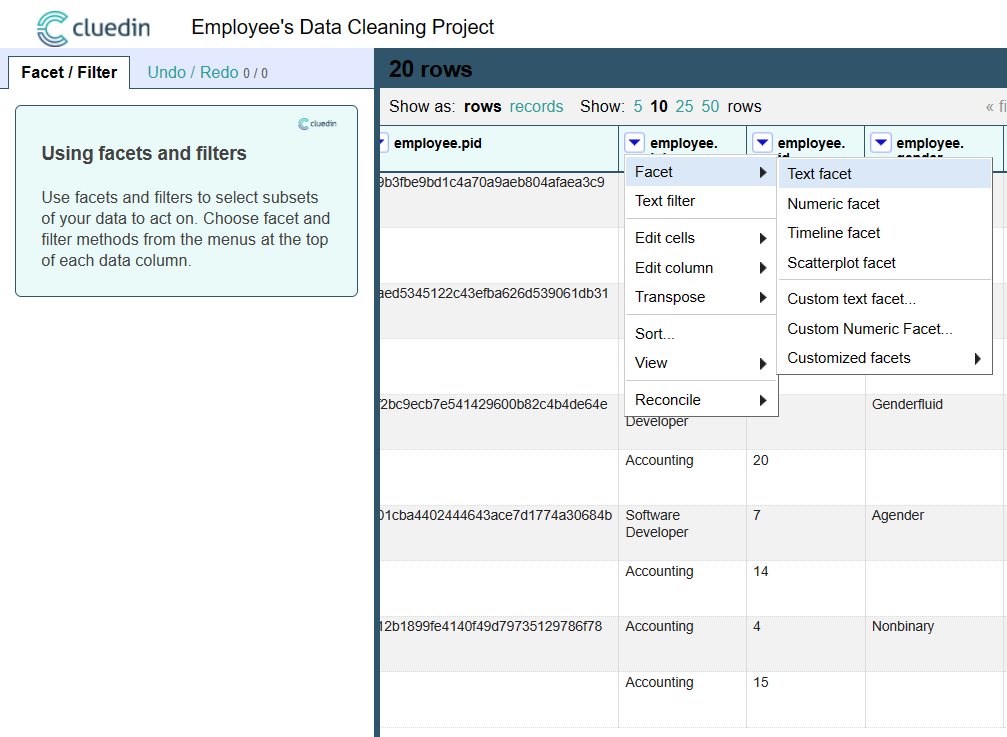
On the left hand side, you see that CluedIn shows an aggregation of all of the unique values of that column. It also shows a count next to each item to reflect how many rows share a column value.
Select the Cluster button. CluedIn shows a prompt that suggests where the data quality issues lie, and the proposed solution on what to normalize the values to.
From the dropdown, choose the Keying function option. Choose the metaphone3 option in the subsequent dropdown.
You notice that CluedIn is recommending that all of the different spelling of Accounting on the left and proposing that they're all normalized into Accounting on the right. Accept this suggestion and the one for Software Dev.
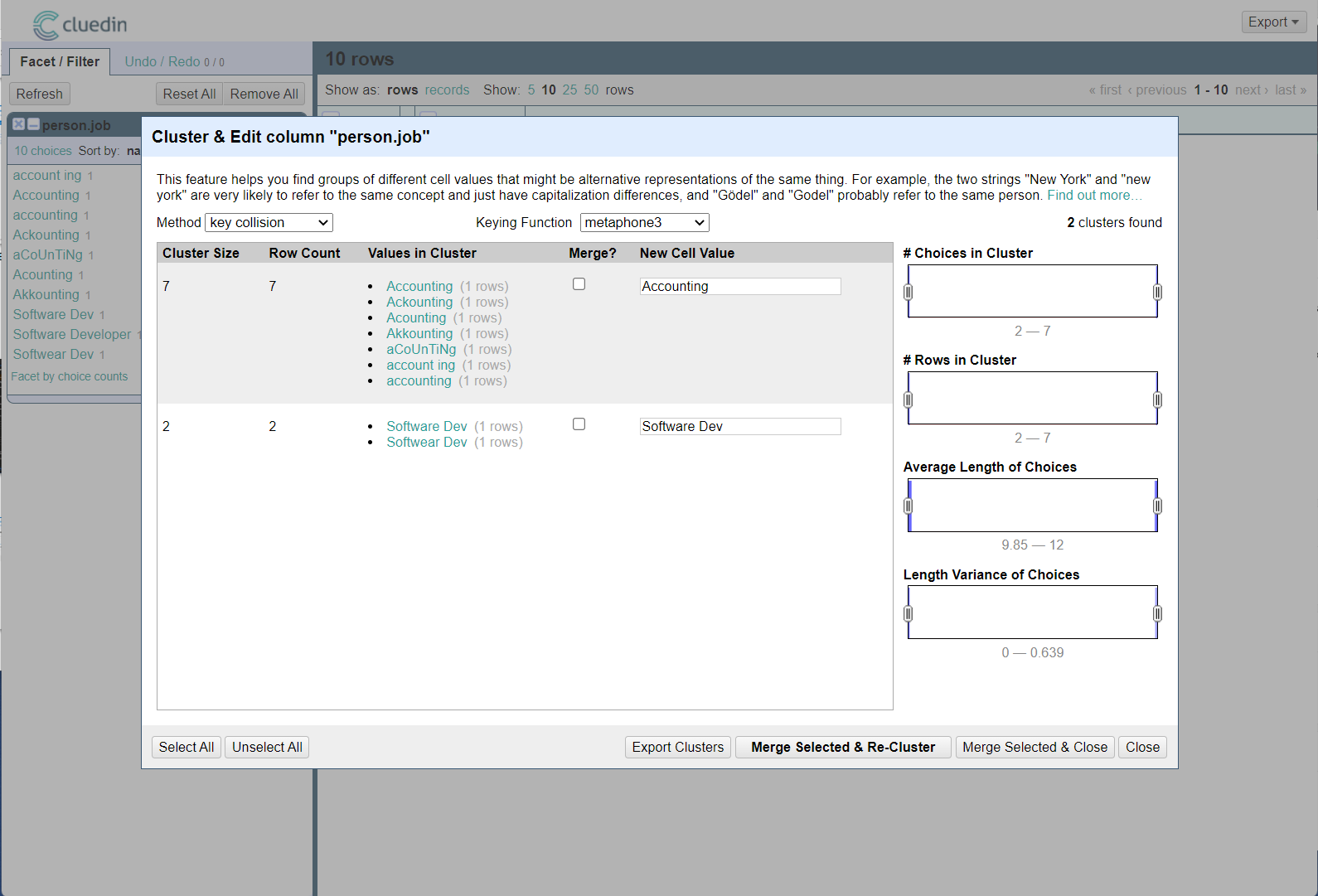
Cycle through all the other Keying functions and their suggestions until all the values are normalized. There are now only two permutations of the Job titles that we had in the original raw data.
Close this tab, and on the previous tab you used to get to this application, select Commit.
When prompted, make sure that the checkbox for Auto-creating Rules is ticked.
Analyzing the results
The previous exercise yields a few elements, including:
- If we look at the records in CluedIn, we can see that some data is changed. For example, Lorain now has a new Job Title with the history of the old job title.
- Under the Rules menu within CluedIn, there are two business rules automatically created for us (disabled by default).
- If we look in our container storage, we can see that new files are created that include the delta changes.
Go back to the automated rules that were constructed and select them all. Toggle to activate them.
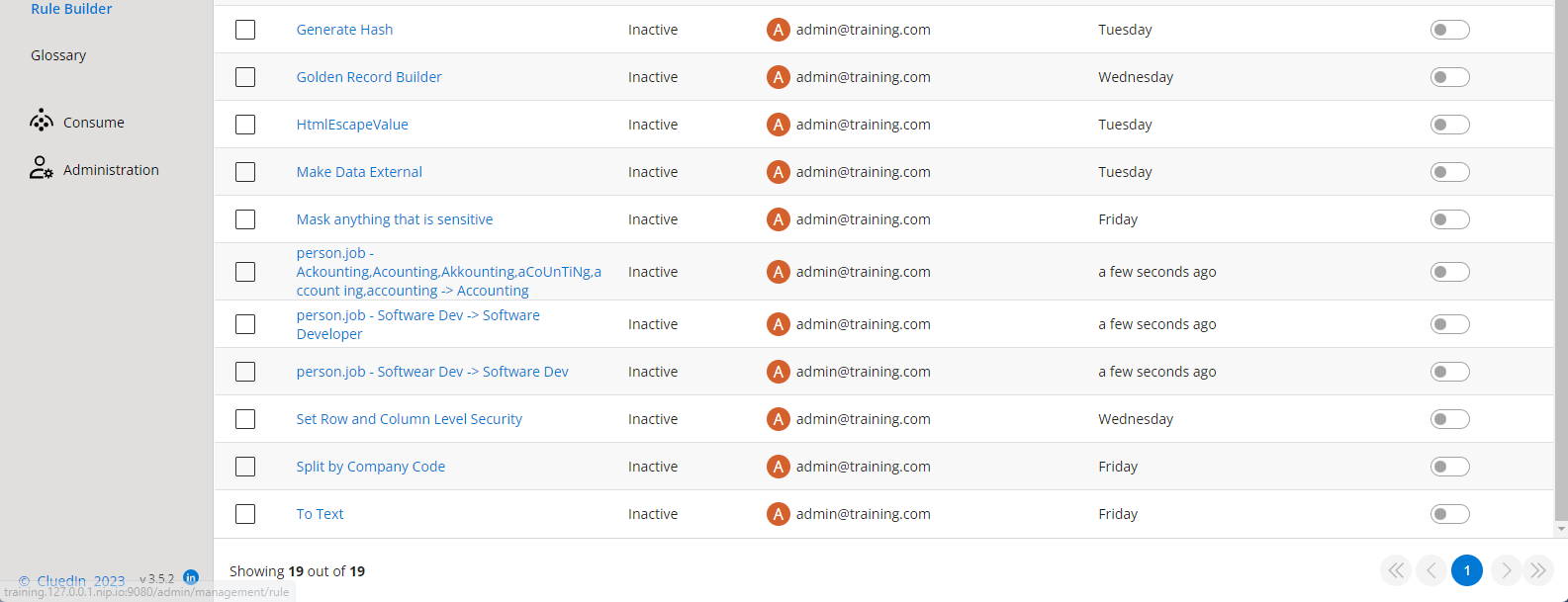
Return to the data sources in CluedIn. Map the final file called ContactsAddLater.csv that had the same data quality issues in it. This time, just process the data directly and don't clean it at all.
Go back to your container storage, and notice that you have even more files now. CluedIn's rules automatically fixed their job titles.
Next unit: Incrementally increase readiness
Having an issue? We can help!
- For issues related to this module, explore existing questions using the #Windows Training tag or Ask a question on Microsoft Q&A.
- For issues related to Certifications and Exams, post on Certifications Support Forums or visit our Credentials Help.