Data structure
When a user submits a job, the associated HDFS data blocks are loaded and fed to the map tasks in the map phase (see Figure 2). Each map task processes one or many HDFS blocks encapsulated in what is called a split. A split can contain one or many references (not actual data) to one or many HDFS blocks. Split size, how many HDFS blocks a split references, is a configurable parameter. Each map task is always responsible for processing only one split. Thus, the number of splits dictates the number of map tasks in a MapReduce job, which in return dictates the overall map parallelism. If a split points to only one HDFS block, the number of map tasks becomes equal to the number of HDFS blocks.1,3 For data-locality reasons, a common practice in Hadoop is to have each split encapsulate only one HDFS block. Specifically, MapReduce attempts to schedule map tasks in proximity to input splits so as to diminish network traffic and improve application performance. Hence, when a split references more than one block, the probability of these blocks existing at the same node where the respective map task will run becomes low. This leads to a network transfer of at least one block (64 MB by default) per map task. With a one-to-one mapping between splits and blocks, however, a map task can run at a node at which the required block exists and, subsequently, leverage data locality and reduce network traffic.
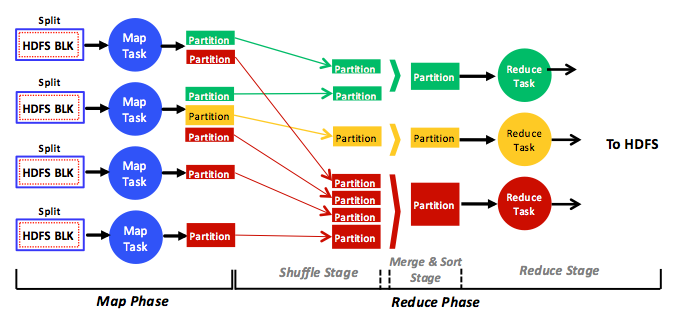
Figure 2: A full, simplified view of the phases, stages, tasks, data input, data output, and data flow in the MapReduce analytics engine
In the presence of a reduce phase, map tasks store partitions on local disks (not in HDFS) and hash them to designated reduce tasks. Each reduce task collects (shuffles) its corresponding partitions from local disks, merges and sorts them, runs a user-defined reduce function, and stores the final result in HDFS. Thus, the reduce phase is usually broken into shuffle, merge and sort, and reduce stages, as shown in Figure 2. In the absence of a reduce phase, map tasks write their outputs directly to HDFS. Figure 2 shows that reduce tasks can receive varied numbers of partitions with different sizes. This phenomenon is called partitioning skew1, 4 and has some effects on reduce task scheduling.
Figure 2 demonstrates a simplified view of what the Hadoop MapReduce engine actually does. For instance, MapReduce overlaps the map and the reduce phases for performance reasons. In particular, reduce tasks are scheduled after only a certain percentage (by default 5%) of map tasks finish so they can gradually start shuffling their partitions. Specifically, the shuffle and the merge and sort stages execute simultaneously so that partitions are continuously merged while being fetched. The rationale behind such a strategy is to interleave execution of map and reduce tasks and enhance, accordingly, the turnaround times of MapReduce jobs. Such an interleaving technique is commonly called the early shuffle technique.2, 4
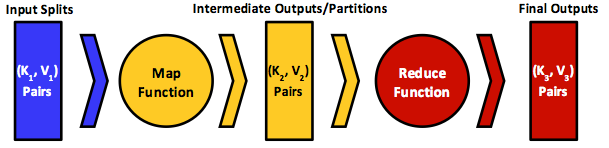
Figure 3: The key-value data model that MapReduce employs, and the input and the output to and from the map and reduce functions
MapReduce has been inspired by functional languages. Programmers write functional-style code comprising sequential map and reduce functions that are submitted as jobs to the MapReduce engine. The engine transforms jobs into map and reduce tasks, distributing and scheduling them at participating cluster nodes.2 Map and reduce function inputs and outputs are always structured as key-value pairs, and dataflow follows the general pattern shown in Figure 3. Typically, the map input key and value types, $K_{1}- V_{1}$, will differ from the function's output key-value types, $K_{2}$ and $V_{2}$. The reduce input key and value types, $K_{2}$ and $V_{2}$, however, should match map function outputs. The reduce function allows aggregating values, so it usually receives an iterator (list) of input values from multiple map tasks. It then applies the user-defined reduce function on these values collectively, possibly returning new key-value(s) types, $K_{3}$ and $V_{3}$. A key from a map task can appear at only one reduce task, while a reduce task can receive and process keys from one or many map tasks. This property is guaranteed by the MapReduce engine (specifically the hashing function used in partitioning the map output). Last, an extra function, called the combiner function, can be introduced at the map function output where it acts just like a reduce function. In this case, the combiner function's output will subsequently form the input to the reduce function.
The combiner function is best illustrated through an example. Assume that a map function parses files representing a company's predicted earnings over the next 5 years, producing key-value pairs in the form [$K_{2}$ = year, $V_{2}$ = estimated earnings (millions US dollars)]. Suppose that multiple mathematical models generate the predictions, possibly different, for any particular year. Assume also a reduce function that receives the map output and computes the maximum earnings over years. Suppose that two map tasks, $M_{1}$ and $M_{2}$, process the estimates for 2015 (which reside in two different splits) and generate results of {[2015, 29], [2015, 31]} by $M_{1}$ and {[2015, 23], [2015, 31], [2015, 28]} by $M_{2}$. The outputs of $M_{1}$ and $M_{2}$ will then be hashed and shuffled to the same reduce task, and the reduce function will be called with an input {[2015, 29], [2015, 31], [2015, 23], [2015, 31], [2015, 28]} and produce an output [2015, 31] giving the maximum predicted amount. If, however, a combiner function also computes the maximum predicted earnings at the outputs of $M_{1}$ and $M_{2}$, only [2015, 31] and [2015, 31] will be shuffled to the corresponding reduce task from $M_{1}$ and $M_{2}$. The combiner will thus diminish the amount of data shuffled over the network, save the bandwidth available on the cluster, and potentially improve performance. Although this tactic works for our example computation, it will not necessarily succeed for others. For instance, if we were to compute the average predicted earnings over years, we could not compute an average in the combiner because, mathematically, the average of averages of multiple values is not always equal to the average of all (the same) values. Suitable combiner functions must be commutative and associative functions or distributive functions as denoted in Gray and associates, "Data Cube: A Relational Aggregation Operator Generalizing Group-by, Cross-tab, and Sub-totals."5
1 The number of HDFS blocks of a job can be computed by dividing the job's dataset size by the configurable HDFS block size.
2 Each reduce task processes one or many values produced by one or many map tasks.
References
- S. Ibrahim, H. Jin, L. Lu, S. Wu, B. He, and L. Qi (Dec. 2010). LEEN: Locality/Fairness-Aware Key Partitioning for MapReduce in the Cloud CloudComm
- M. Hammoud and M. F. Sakr (2011). Locality-Aware Reduce Task Scheduling for MapReduce CloudCom
- HDFS Architecture Guide Hadoop
- M. Hammoud, M. S. Rehman, and M. F. Sakr (2012). Center-of-Gravity Reduce Task Scheduling to Lower MapReduce Network Traffic CLOUD
- J. Gray, S. Chaudhuri, A. Bosworth, A. Layman, D. Reichart, M. Venkatrao, and H. Pirahesh (1997). Data Cube: A Relational Aggregation Operator Generalizing Group-by, Cross-tab, and Sub-totals Data Mining and Knowledge Discovery