Cloud challenges: Fault tolerance
One basic feature that distinguishes clouds and other distributed systems from uniprocessor systems is the concept of partial failures. Specifically, if one node or component fails in a distributed system, the whole system may be able to continue functioning. On the other hand, if one component (e.g., the RAM) fails in a uniprocessor system, the whole system will also fail. A crucial objective in designing distributed systems/programs is to construct them in a way that they can tolerate partial failures automatically, without seriously affecting performance. A key technique for masking faults in distributed systems is to use hardware redundancy, such as the RAID technology (see learning path 3 in this course). In most cases, however, distributed programs cannot depend solely on the underlying hardware fault-tolerance techniques of distributed systems. Among the popular techniques that the distributed programs can apply is software redundancy.
 .
.
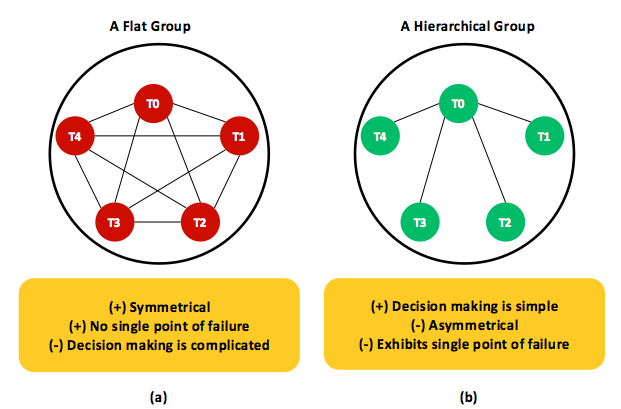
Figure 15: Two classical ways to employ task redundancy. (a) A flat group of tasks. (b) A hierarchical group of tasks with a central process (that is, T0, where T1 stands for task 1).
One common type of software redundancy is task redundancy (also called resiliency, or replication), which protects against task failures and slowness. Tasks can be replicated as flat or hierarchical groups, exemplified in Figure 15. In flat groups (see Figure 15(a)), all tasks are identical in that they all carry the same work. Eventually, only the result of one task is accepted, and the other results are discarded. Obviously, flat groups are symmetrical and preclude SPOFs: if one task crashes, the application will stay in business, yet the group will become smaller until recovered. However, if for some applications a decision is to be made (e.g., acquiring a lock), a voting mechanism may be required. As discussed earlier, voting mechanisms incur implementation complexity, communication delays, and performance overheads.
A hierarchical group (see Figure 15(b)) usually employs a coordinator task and specifies the rest of the tasks as workers. In this model, when a user request is made, it gets forwarded to the coordinator who, in turn, decides which worker is best suited to fulfill the request. Clearly, hierarchical and flat groups reflect opposing properties. In particular, the coordinator is an SPOF and a potential performance bottleneck (especially in large-scale systems with millions of users). In contrast, as long as the coordinator is protected, the whole group remains functional. Furthermore, decisions can be easily made, solely by the coordinator, without bothering any worker or incurring communication delays and performance overheads. A hybrid of flat and hierarchical task groups is adopted by Hadoop MapReduce but only for task failures. Details on that adoption are provided in the section on Hadoop MapReduce.
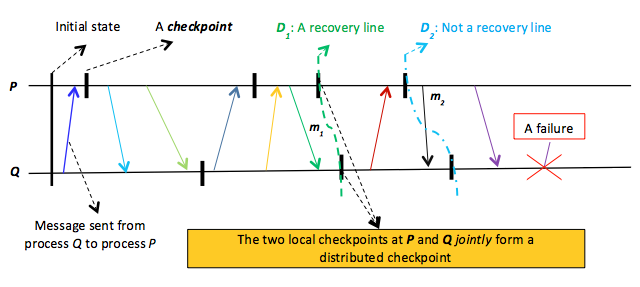
Figure 16: Demonstrating distributed checkpointing. D1 is a valid distributed checkpoint, while D2 is not because it is inconsistent. Specifically, the D2 checkpoint at Q indicates that m2 has been received, while the D2 checkpoint at P does not indicate that m2 has been sent.
In distributed programs, fault tolerance concerns not only surviving faults but also recovering from failures. The basic idea here is to replace a flawed state with a flaw-free state, and one way to achieve this goal is through backward recovery. This strategy requires that the distributed program/system is brought from a current, flawed state to a previously correct state and relies on periodically recording the system's state at each process, which is called obtaining a checkpoint. When a failure occurs, recovery can be started from the last recorded correct state, typically called the recovery line.
Checkpoints of a distributed program at different processes in a distributed system constitute a distributed checkpoint. The process of capturing a distributed checkpoint is not easy because of one main reason. Specifically, a distributed checkpoint must maintain a consistent global state; that is, it should maintain the property that if a process $P$has recorded the receipt of a message, $m$, then there should be another process $Q$ that has recorded the sending of $m$. After all, $m$ must have come from a known process. Figure 16 demonstrates two distributed checkpoints, $D_{1}$, which maintains a consistent global state, and $D_{2}$, which does not. The $D_{1}$ checkpoint at $Q$ indicates that $Q$ has received a message, $m_{1}$, and the the $D_{1}$ checkpoint at $P$ indicates that $P$ has sent $m_{1}$, hence making $D_{1}$ consistent. In contrast, the $D_{2}$ checkpoint at $Q$ indicates that message $m_{2}$ has been received, and the $D_{2}$ checkpoint at $P$ does not indicate that $m_{2}$ has been sent from $P$. Therefore, $D_{2}$ must be considered inconsistent and cannot be used as a recovery line.
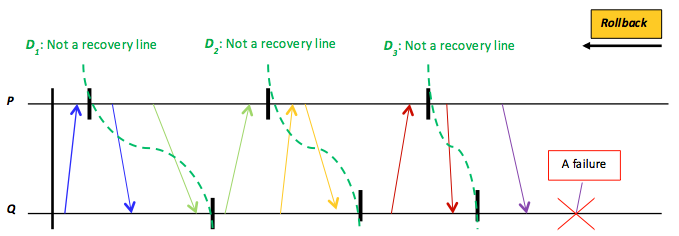
Figure 17: The domino effect that might result from rolling back each process (that is, processes P and Q) to a saved, local checkpoint in order to locate a recovery line. D1, D2, and D3 are not recovery lines because they exhibit inconsistent global states.
By rolling back each process to its most recently saved state, a distributed program/system can inspect a candidate distributed checkpoint to determine its consistency. When local states jointly form a consistent global state, a recovery line is said to be discovered. For instance, after a failure, the system exemplified in Figure 16 will roll back until hitting $D_{1}$. Because $D_{1}$ reflects a global consistent state, we have obtained a recovery line. Unfortunately, the process of cascaded rollbacks is challenging because it can lead to a domino effect. As a specific example, Figure 17 exhibits a case in which a recovery line cannot be found. In particular, every distributed checkpoint in Figure 17 is indeed inconsistent. This pitfall makes distributed checkpointing a costly operation that may not converge to an acceptable recovery solution. Many fault-tolerant distributed systems thus combine checkpointing with message logging, recording each process message before sending and after a checkpoint has been taken. This tactic solves the problem of $D_{2}$ in Figure 16, for example. In particular, after the $D_{2}$ checkpoint at $P$ is taken, the send of $m_{2}$ will be marked in a log message at $P$, which, if merged with the $D_{2}$ checkpoint at $Q$, can form a global consistent state. The Hadoop Distributed File System (HDFS) itself combines distributed checkpointing (the image file) and message logging (the edit file) to recover NameNode failures (see the third learning path in this course). Pregel and GraphLab, discussed in later sections, apply only to distributed checkpointing.