Why use distributed programming?
Various analytic techniques at the algorithm and code levels can identify potential parallelism in sequential programs1 and, in principle, every sequential program can be parallelized. A program can then be split into serial and parallel parts, as shown in Figure 3. Parallel parts can run concurrently on a single machine or be distributed across machines. Programmers typically transform sequential programs into parallel versions mainly to achieve higher computational speed, or throughput. In an ideal world, parallelizing a sequential program into an n-way distributed program would yield an n-fold decrease in execution time. Using distributed programs as opposed to sequential programs is crucial for multiple domains, especially science. For instance, simulating the folding of a single protein can take years if performed sequentially but only days if executed in parallel. The pace of scientific discovery in some domains depends on how fast certain scientific problems can be solved. Furthermore, some programs have real-time constraints such that if computation is not performed fast enough, the whole program may be rendered pointless. For example, predicting the direction of hurricanes and tornados using weather modeling must be done in a timely manner, or else the prediction will be wasted. In actuality, scientists and engineers have relied on distributed programs for decades to solve important and complex scientific problems, such as quantum mechanics, physical simulations, weather forecasting, oil and gas exploration, and molecular modeling, to mention a few. This trend will probably continue, at least in the foreseeable future.
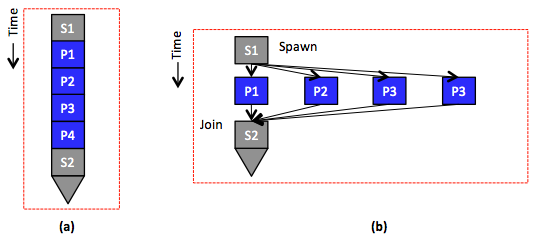
Figure 3: (a) A sequential program with serial (S1) and parallel (P1) parts. (b) A parallel/distributed program that corresponds to the sequential program in (a), whereby the parallel parts can be either distributed across machines or run concurrently on a single machine.
Distributed programs have also found broad applications beyond science, such as search engines, web servers, and databases. One example is the Folding@Home project2 which uses distributed computing on all kinds of systems, from super computers, to personal PCs to perform molecular dynamics simulations of protein dynamics. Without parallelization, Folding@Home wouldn't be able to access nearly as many computational resources. For example, running a Hadoop MapReduce3 program on a single VM instance is not as effective as running it on a large-scale cluster of VM instances. Of course, committing jobs earlier on the cloud leads to a reduction in cost, which is a key objective for cloud users.
Distributed programs also help alleviate subsystem bottlenecks. For instance, I/O devices, such as disks and network interface cards, typically represent major bottlenecks in terms of bandwidth, performance, and/or throughput. By distributing work across machines, data can be served from multiple disks simultaneously, offering an increased aggregate I/O bandwidth, improving performance, and maximizing throughput. In summary, distributed programs play a critical role in rapidly solving various computing problems and effectively mitigating resource bottlenecks. This action improves performance, increases throughput, and reduces cost, especially in the cloud.
References
- Y. Solihin (2009). Fundamentals of Parallel Computer Architecture Solihin Books
- Stefan M. Larson, Christopher D. Snow, Michael Shirts, Vijay S. Pande (2002). Folding@Home and Genome@Home: Using distributed computing to tackle previously intractable problems in computational biology
- Apache Hadoop