Synchronous vs. asynchronous computation
The following figure shows the bulk synchronous parallel (BSP) model:
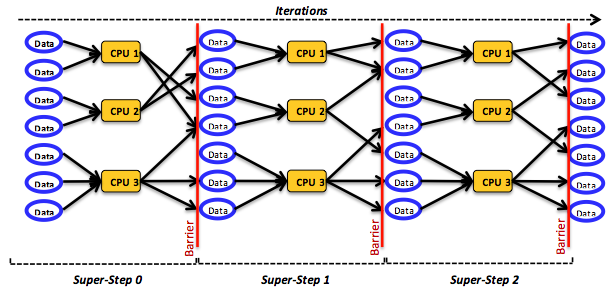
Figure 8: The bulk synchronous parallel model
Independent of the programming model used, a developer can specify distributed computation as either synchronous or asynchronous. This distinction refers to the presence or absence of a (global) coordination mechanism that synchronizes task operations. A distributed program is synchronous if and only if the component tasks operate in lockstep. That is, for some constant $(c \geq 1)$, if and only if any task has taken $(c + 1)$ steps, then every other task must have taken at least $c$ steps.1 Subsequently, if any task has taken $(c + 2)$ steps, then every other task must have taken at least $(c + 1)$ steps. Clearly, this constraint requires a coordination mechanism through which task activities can be synchronized and their timing be accordingly enforced. Such mechanisms usually have an important effect on performance. Typically, in synchronous programs, distributed tasks must wait at predetermined points for the completion of certain computations or for the arrival of certain data.3 A program that is not synchronous is an asynchronous program. Asynchronous programs impose no requirement to wait at predetermined points or for the arrival of certain data. Computational asynchrony obviously has less effect on performance but implies that the correctness/validity of the program must be assessed.
MapReduce and Pregel programs, for example, involve synchronous computation, while those under GraphLab are asynchronous. Pregel employs the bulk synchronous parallel (BSP) model2, which is a synchronous model commonly employed for effectively implementing distributed programs. BSP combines three attributes: components, a router, and a synchronization method. A BSP component comprises a processor and data stored in local memory, but the model does not preclude other arrangements, such as holding data in remote memories. BSP is neutral about the number of processors, be it two or a million. And BSP programs can be written for $v$ virtual distributed processors to run on $p$ physical distributed processors, where $(v > p)$.
BSP builds on the message-passing programming model, sending and receiving messages through a router that, in principle, can only pass messages point-to-point between pairs of components. (The model provides no broadcasting facilities, although developers can implement them using multiple point-to-point communications.) To achieve synchrony, BSP splits every computation into a sequence of steps called super-steps. In every super-step, $S$, each component is assigned a task encompassing (local) computation. Components in $S$ can send messages to $(c + 1)$ components in super-step $(S + 1)$ and are implicitly allowed to receive messages from components in super-step $(S - 1)$. In every super-step, tasks operate simultaneously and do not communicate with each other. Across super-steps, tasks move in a lockstep mode: no task in $(S + 1)$ can start before every task in $S$ commits. To satisfy this condition, BSP applies a global, barrier-style synchronization mechanism, as shown in Figure 8. Because BSP does not provide simultaneous accesses to a single memory location, it does not require any synchronization mechanism beyond barriers.
Another primary concern in a distributed setting lies in allocating data so that computation will not be slowed by nonuniform memory access latencies or uneven loads among individual tasks. BSP promotes uniform access latencies by using local data: data is communicated across super-steps before triggering actual task computations, and the model thus divorces computation and communication. Such separation implies that no particular network topology is favored beyond the requirement to deliver high throughput. Butterfly, hypercube, and optical crossbar topologies are all acceptable.
Across tasks within a super-step, data volumes can still vary, and task loading depends mainly on the distributed program and the responsibilities it imposes on its constituent tasks. Accordingly, the time required to finish a super-step becomes bound by its slowest task. (A super-step cannot commit before its slowest task finishes.) This limit presents a major challenge for the BSP model because it can create load imbalance, which usually degrades performance. Load imbalance can also be caused by heterogeneous clusters, especially on the cloud. Note that although BSP suggests several design choices, it does not make their use obligatory. Indeed, BSP leaves many design choices open (e.g., barrier-based synchronization can be implemented at a finer granularity or completely switched off if unneeded for the given application).
References
- A. S. Tanenbaum and M. V. Steen (October 12, 2006). Distributed Systems: Principles and Paradigms Prentice Hall, Second Edition
- L. G. Valiant (1990). A Bridging Model for Parallel Computation In Communications of the ACM
- D. P. Bertsekas and J. N. Tsitsiklis (January 1, 1997). Parallel and Distributed Computation: Numerical Methods Athena Scientific, First Edition