Scaling options in Azure Kubernetes Services
When running applications in Azure Kubernetes Service (AKS), you may need to increase or decrease the amount of compute resources. As you change the number of application instances you have, you may need to change the number of underlying Kubernetes nodes. You also may need to provision a larger number of application instances.
This module summarizes the core AKS application scaling concepts, including:
- Scaling pods or nodes
- Horizontal pod autoscaler
- Cluster autoscaler
- Azure Container Instances (ACI)
Manually scale pods or nodes
You can manually scale replicas, or pods, and nodes to test how your application responds to a change in available resources and state. Manually scaling resources lets you define a set amount of resources to use to maintain a fixed cost, such as the number of nodes. To manually scale, you define the replica or node count. The Kubernetes API then schedules the creation of more pods or the draining of nodes based on that replica or node count.
When scaling down nodes, the Kubernetes API calls the relevant Azure Compute API tied to the compute type used by your cluster. For example, for clusters built on Virtual Machine Scale Sets, the logic for selecting which nodes to remove determined by the Virtual Machine Scale Sets API.
Horizontal pod autoscaler
Kubernetes uses the horizontal pod autoscaler (HPA) to monitor the resource demand and automatically scale the number of pods. By default, the HPA checks the Metrics API every 15 seconds for any required changes in replica count, and the Metrics API retrieves data from the Kubelet every 60 seconds. So, the HPA is updated every 60 seconds. When changes are required, the number of replicas is increased or decreased accordingly.
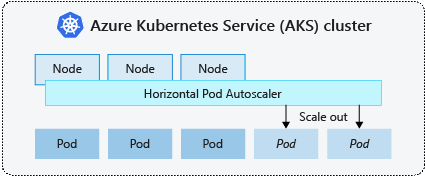
When you configure the HPA for a given deployment, you define the minimum and maximum number of replicas that can run. You also define the metric to monitor and base any scaling decisions on, such as CPU usage.
Horizontal scaling is a reaction to an increased load that results in deploying more Pods. Horizontal scaling differs from vertical scaling where there's more resources assigned to the Pods that are already running a workload.
If the load decreases, and the number of Pods is above the minimum, horizontal scaling adjusts the workload to scale back down.
Cooldown of scaling events
As the HPA is effectively updated every 60 seconds, previous scale events may not have successfully completed before another check is made. This behavior could cause the HPA to change the number of replicas before the previous scale event could receive application workload and the resource demands to adjust accordingly.
To minimize race events, a delay value is set. This value defines how long the HPA must wait after a scale event before another scale event can be triggered. This behavior allows the new replica count to take effect and the Metrics API to reflect the distributed workload. There's no delay for scale-up events as of Kubernetes 1.12, however, the default delay on scale down events is 5 minutes.