Deploy the Azure Arc data controller
Because you selected the directly connected mode for implementing Azure Arc-enabled SQL managed instances for overseas datacenters and the indirectly connected mode for the US government contract-related data, you have a few deployment options to consider. You have the option to use user-friendly graphical interfaces of the Azure portal and Azure Data Studio and the command-line tools that facilitate scripting and automation. These options offer flexibility and allow you to choose the deployment methodology best suited to your operational model.
However, regardless of the choice you make, provisioning of Azure Arc-enabled data services consists of several main steps, as the following diagram illustrates:
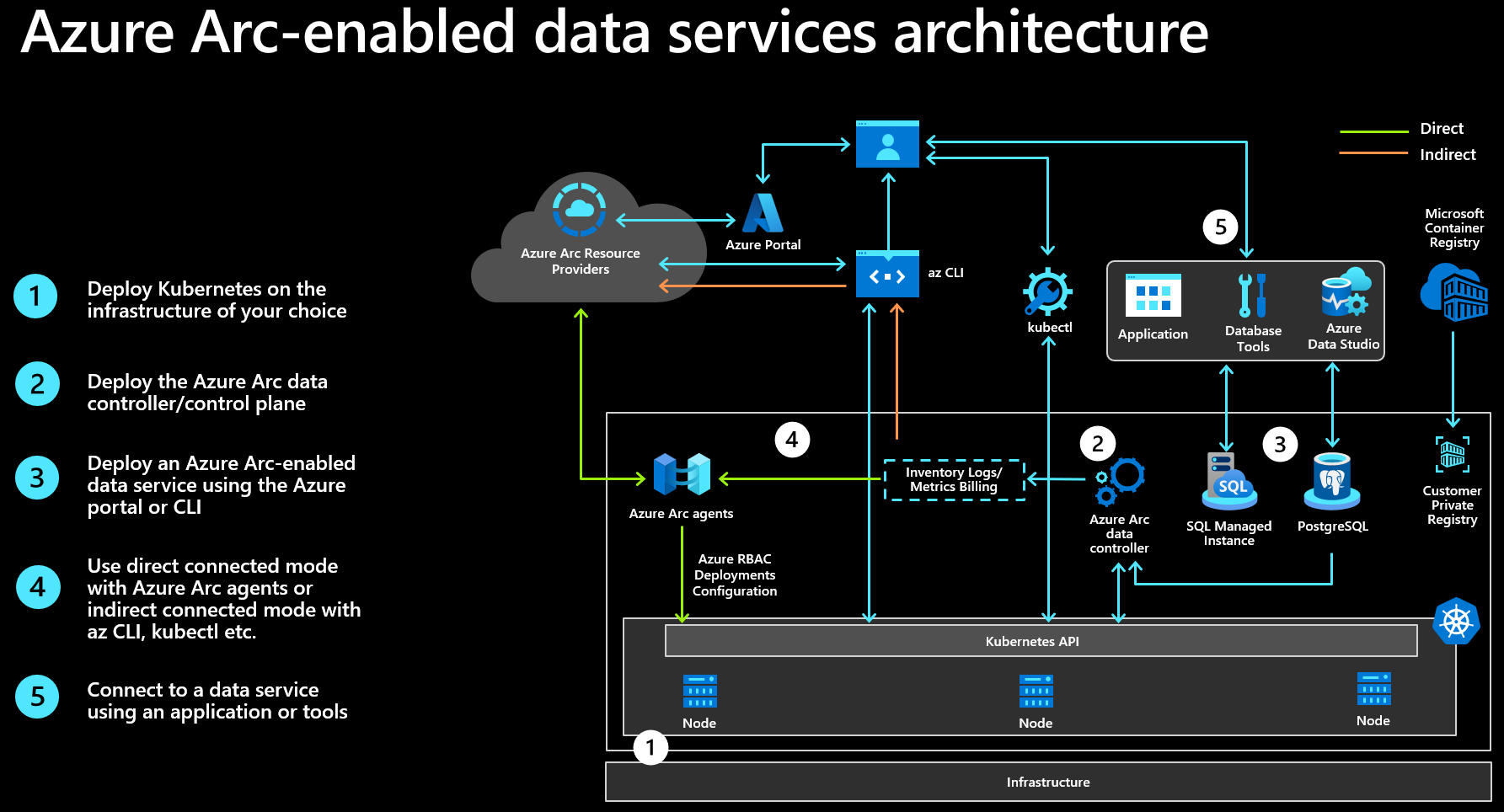
Step 1 - Deploy Kubernetes on the infrastructure of your choice provides the container orchestration platform for your Azure Arc-enabled data services.
Step 2 - Deploy the Arc-enabled data controller/control plane starts with connecting the Kubernetes cluster to Azure, creating an Azure Arc data controller extension, and defining a custom location. It concludes with deploying a set of data controller pods into the Arc-enabled Kubernetes infrastructure.
Step 3 - Deploy an Azure Arc-enabled data service results in an Azure Arc-enabled SQL Managed Instance running in your datacenter.
Step 4 - Upload of inventory, logs, metrics, and billing data offers a centralized view of your Azure and Azure Arc-enabled data services. Implementing the upload functionality depends on the connectivity mode you choose.
Step 5 - Connect to your data services allows you to manage your Azure and Azure Arc-enabled data services in a consistent manner by using a common set of tools. This consistency extends to application access, minimizing software development and maintenance efforts.
This module focuses on the first two steps. Subsequent modules of this learning path cover the remaining steps.
Start by deploying an Azure Arc-supported Kubernetes cluster or identifying an existing one and connecting to it with credentials that provide administrative access. The method you use to establish such a connection depends on the platform on which the cluster is running and the deployment methodology you choose. However, in general, it involves using the kubeconfig file pointing to the target Kubernetes cluster. The same two criteria also determine the client tools you'll need to install to perform the deployment. For Azure Data Studio-based deployments, be sure to add the Azure Arc extension for Azure Data Studio. When using Azure CLI, you need to install several extensions, including arcdata, k8s-extension, connectedk8s, k8s-configuration, and customlocation. The use of Azure PowerShell requires the Az.ConnectedKubernetes module. To manage the cluster, use Kubernetes CLI (kubectl).
Note
For a comprehensive coverage of client tools, refer to the Microsoft Learn article Install client tools for deploying and managing Azure Arc-enabled data services.
Another deployment consideration is the choice of a configuration template. Configuration templates, referred to as profiles during data controller provisioning, contain a variety of data controller configuration options, such as container registry and repository settings, storage classes and sizes for data and logs, and the service type. You can choose one of the predefined templates that most closely matches your planned deployment or create a custom one, if needed.
After you've all prerequisites in place, you're ready to proceed with the deployment of the data controller.
Deploy data controller in the directly connected mode
To deploying a data controller in the directly connected mode, start by authenticating to the Azure subscription that will host resources representing the controller's metadata, and then connect your Kubernetes cluster to Azure by using Azure Arc-enabled Kubernetes. You might first have to register providers for Azure Arc-enabled Kubernetes in your Azure subscription if this is your first deployment.
The process of connecting the Kubernetes cluster to Azure results in the creation of the Azure Arc-enabled Kubernetes shadow resource in the resource group you designate. It also deploys a number of pods hosting Azure Arc agents for Kubernetes into the azure-arc namespace of the target cluster. Note that after this process completes, it might take a few minutes before the cluster metadata (including such information as the cluster version, agent version, and number of nodes) appears on the overview page of the Azure Arc-enabled Kubernetes shadow resource in the Azure portal.
You can initiate provisioning of the data controller directly from the marketplace gallery in the Azure portal. As part of the provisioning process, you create an Azure Arc data controller extension, define a custom location that designates the Azure Arc-enabled Kubernetes cluster as the viable target for deployment of data services, and provide a number of other configuration details, including the data controller name, the configuration template, Kubernetes service type, in addition to credentials for metrics and logs dashboards. The provisioning deploys pods hosting the data controller components into the namespace you designate. Alternatively, you can use Azure CLI or PowerShell to create an Azure Arc-enabled data services extension, a custom location, and a data controller either separately or in a unified experience by running a single command.
When you deploy the Azure Arc-enabled data controller, you can enable automatic upload of metrics and logs during setup. To accomplish this, you need to have an existing Log Analytics workspace and provide its Workspace ID and the corresponding access key. You can also enable automatic upload of metrics and logs at any point after the deployment.
Deploy data controller in the indirectly connected mode
The steps to deploy a data controller in the indirectly connected mode vary significantly depending on the deployment tool you choose. Azure Data Studio simplifies the provisioning process through its Azure Arc Data Controller deployment wizard. The wizard guides you through deployment steps, verifying the prerequisites, ensuring connectivity to the target Kubernetes cluster, prompting for the configuration template, the target Azure region, and the resource group to host the controller-related resources. You can deploy the resulting configuration directly or save it as a notebook to accommodate any additional edits and subsequent runs. Alternatively, you can use the Azure portal to generate a notebook to download and run in Azure Data Studio against your Kubernetes cluster.
When using Azure CLI or PowerShell, the steps to create the data controller depend on the Kubernetes platform. For details, refer to the Learn article Create Azure Arc data controller using the CLI
You can also deploy a data controller in the indirectly connected mode by using Kubernetes tools. At a high level, the process involves creating the target namespace and the bootstrapper service, which is followed by provisioning the data controller. The namespace hosts the data controller pods and the bootstrapper service handles incoming requests for creating, editing, and deleting custom resources such as a data controller. Note that in this case, Azure Arc associated resources are created in the Azure subscription following an upload of usage data.