Explore an IaaS high availability and disaster recovery solution
There are many different combinations of features that could be deployed in Azure for IaaS. This section will cover five common examples of SQL Server high availability and disaster recovery (HADR) architectures in Azure.
Single Region High Availability Example 1 – Always On availability groups
If you only need high availability and not disaster recovery, configuring an (availability group) AG is one of the most ubiquitous methods no matter where you are using SQL Server. The image below is an example of what one possible AG in a single region could look like.
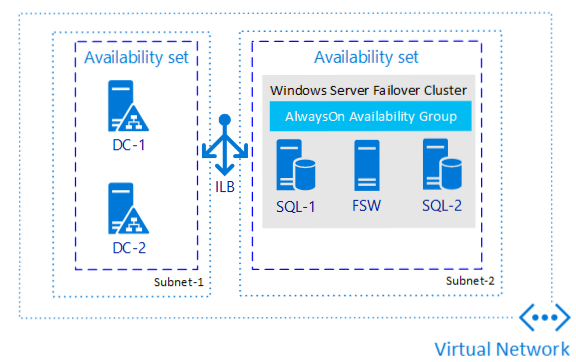
Why is this architecture worth considering?
This architecture protects data by having more than one copy on different virtual machines (VMs).
This architecture allows you to meet recovery time objective (RTO) and recovery point objective (RPO) with minimal-to-no data loss if implemented properly.
This architecture provides an easy, standardized method for applications to access both primary and secondary replicas (if things like read-only replicas will be used).
This architecture provides enhanced availability during patching scenarios.
This architecture needs no shared storage, so there is less complication than when using a failover cluster instance (FCI).
Single Region High Availability Example 2 – Always On Failover Cluster Instance
Until AGs were introduced, FCIs were the most popular way to implement SQL Server high availability. FCIs, however, were designed when physical deployments were dominant. In a virtualized world, FCIs do not provide many of the same protections in the way they would on physical hardware because it is rare for a VM to have a problem. FCIs were designed to protect against things like network card failure or disk failure, both of which would likely not happen in Azure.
Having said that, FCIs do have a place in Azure. They work, and as long as you have the right expectations about what is and is not provided, an FCI is a perfectly acceptable solution. The image below, from the Microsoft documentation, shows a high-level view of what an FCI deployment looks like when using Storage Spaces Direct.
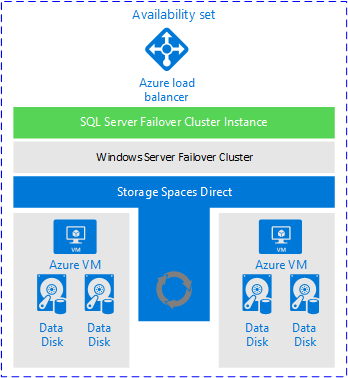
Why is this architecture worth considering?
FCIs are still a popular availability solution.
The shared storage story is improving with feature like Azure Shared Disk.
This architecture meets most RTO and RPO for HA (although DR is not handled).
This architecture provides an easy, standardized method for applications to access the clustered instance of SQL Server.
This architecture provides enhanced availability during patching scenarios.
Disaster Recovery Example 1 – Multi-Region or Hybrid Always On availability group
If you are using AGs, one option is to configure the AG across multiple Azure regions or potentially as a hybrid architecture. This means that all nodes which contain the replicas participate in the same WSFC. This assumes good network connectivity, especially if this is a hybrid configuration. One of the biggest considerations would be the witness resource for the WSFC. This architecture would require AD DS and DNS to be available in every region and potentially on premises as well if this is a hybrid solution. The image below shows what a single AG configured over two locations looks like using Windows Server.

Why is this architecture worth considering?
This architecture is a proven solution; it is no different than having two data centers today in an AG topology.
This architecture works with Standard and Enterprise editions of SQL Server.
AGs naturally provide redundancy with additional copies of data.
This architecture makes use of one feature that provides both HA and D/R
Disaster Recovery Example 2 –Distributed availability group
A distributed AG is an Enterprise Edition only feature introduced in SQL Server 2016. It is different than a traditional AG. Instead of having one underlying WSFC where all of nodes contain replicas participating in one AG as described in the previous example, a distributed AG is made up of multiple AGs. The primary replica containing the read write database is known as the global primary. The primary of the second AG is known as a forwarder and keeps the secondary replica(s) of that AG in sync. In essence, this is an AG of AGs.
This architecture makes it easier to deal with things like quorum since each cluster would maintain its own quorum, meaning it also has its own witness. A distributed AG would work whether you are using Azure for all resources, or if you are using a hybrid architecture.
The image below shows an example distributed AG configuration. There are two WSFCs. Imagine each is in a different Azure region or one is on premises and the other is in Azure. Each WSFC has an AG with two replicas. The global primary in AG 1 is keeping the secondary of replica of AG 1 synchronized as well as the forwarder, which also is the primary of AG 2. That replica keeps the secondary replica of AG 2 synchronized.
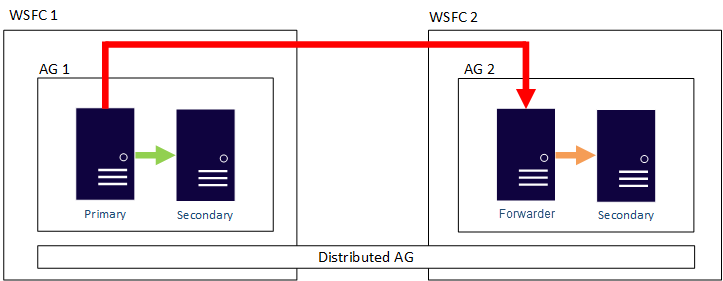
Why is this architecture worth considering?
This architecture separates out the WSFC as a single point of failure if all nodes lose communication
In this architecture, one primary is not synchronizing all secondary replicas.
This architecture can provide failing back from one location to another.
Disaster Recovery Example 3 – Log shipping
Log shipping is one of the oldest HADR methods for configuring disaster recovery for SQL Server. As described above, the unit of measurement is the transaction log backup. Unless the switch to a warm standby is planned to ensure no data loss, data loss will most likely occur. When it comes to disaster recovery, it is always best to assume some data loss even if minimal. The image below, from the Microsoft documentation, shows an example log shipping topology.
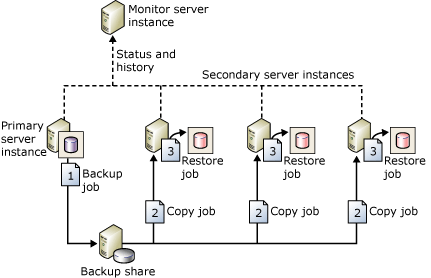
Why is this architecture worth considering?
Log shipping is a tried-and-true feature that has been around for over 20 years
Log shipping is easy to deploy and administer since it is based on backup and restore.
Log shipping is tolerant of networks that are not robust.
Log shipping meets most RTO and RPO goals for DR.
Log shipping is a good way to protect FCIs.
Disaster Recovery Example 4 – Azure Site Recovery
For those who do not want to implement a SQL Server-based disaster solution, Azure Site Recovery is a potential option. However, most data professionals prefer a database-centric approach as it will generally have a lower RPO.
The image below, from the Microsoft documentation. shows where in the Azure portal you would configure replication for Azure Site Recovery.
Why is this architecture worth considering?
Azure Site Recovery will work with more than just SQL Server.
Azure Site Recovery may meet RTO and possibly RPO.
Azure Site Recovery is provided as part of the Azure platform.