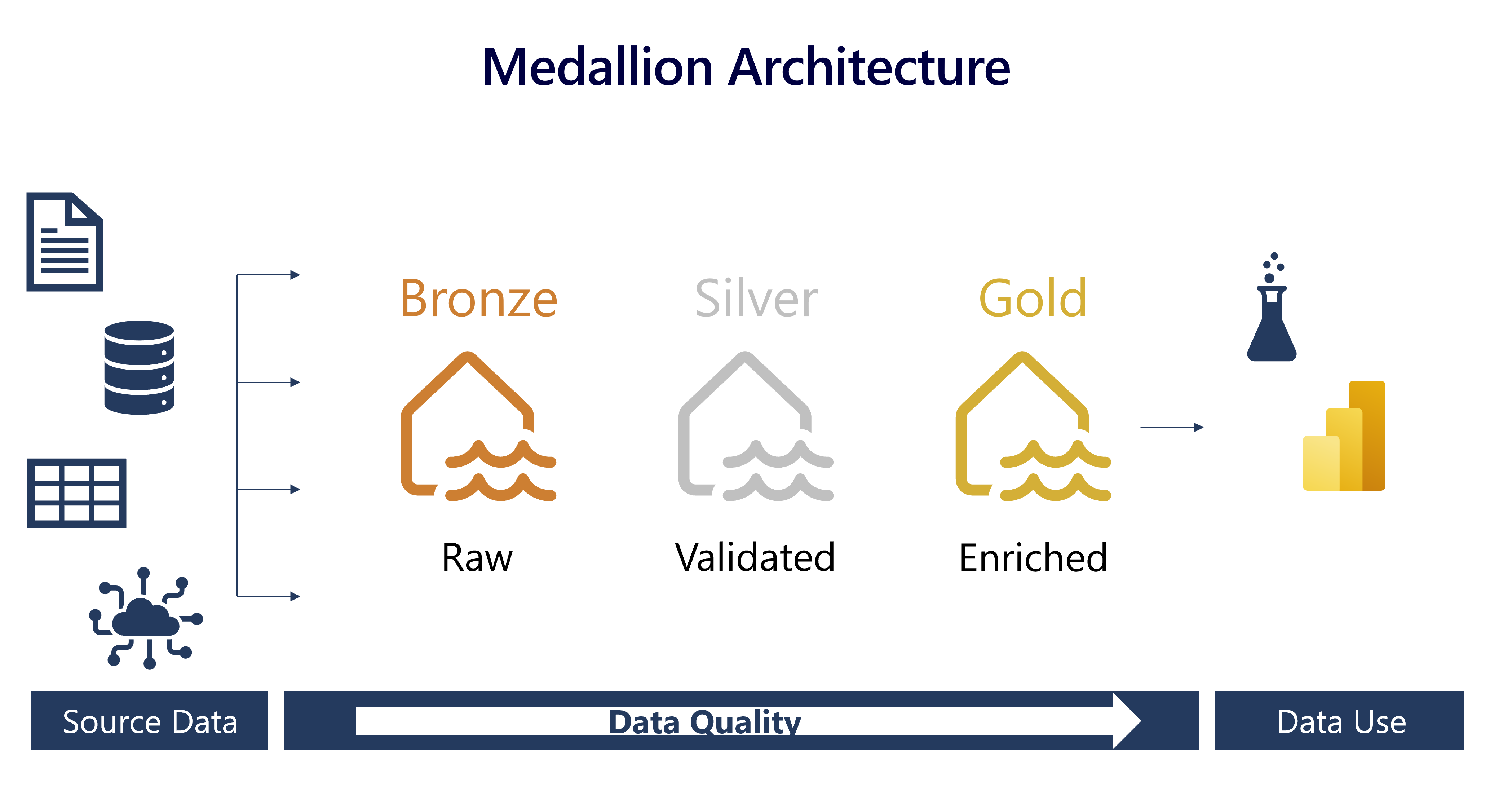
Describe medallion architecture
Data lakehouses in Fabric are built on the Delta Lake format, which natively supports ACID (Atomicity, Consistency, Isolation, Durability) transactions. Within this framework, the medallion architecture is a recommended data design pattern used to organize data in a lakehouse logically. It aims to improve data quality as it moves through different layers. The architecture typically has three layers – bronze (raw), silver (validated), and gold (enriched), each representing higher data quality levels. Some people also call it a "multi-hop" architecture, meaning that data can move between layers as needed.
This architecture ensures that data is reliable and consistent as it goes through various checks and changes. It also guarantees that the data is safely stored in a way that makes it easier and faster to analyze.
The medallion architecture complements other data organization methods, rather than replacing them. You can think of the medallion architecture as the framework for data cleaning, rather than a data architecture or model. It ensures compatibility and flexibility for businesses to adopt its benefits alongside existing data models, allowing you to customize data solutions and preserve expertise while remaining adaptable in the ever-changing data landscape.
Understand the medallion architecture format
Bronze layer
The bronze or raw layer of the medallion architecture is the first layer of the lakehouse. It's the landing zone for all data, whether it's structured, semi-structured, or unstructured. The data is stored in its original format, and no changes are made to it.
Silver layer
The silver or validated layer is the second layer of the lakehouse. It's where you'll validate and refine your data. Typical activities in the silver layer include combining and merging data and enforcing data validation rules like removing nulls and deduplicating. The silver layer can be thought of as a central repository across an organization or team, where data is stored in a consistent format and can be accessed by multiple teams. In the silver layer you're cleaning your data enough so that everything is in one place and ready to be refined and modeled in the gold layer.
Gold layer
The gold or enriched layer is the third layer of the lakehouse. In the gold layer, data undergoes further refinement to align with specific business and analytics needs. This could involve aggregating data to a particular granularity, such as daily or hourly, or enriching it with external information. Once the data reaches the gold stage, it becomes ready for use by downstream teams, including analytics, data science, or MLOps.
Customize your medallion architecture
Depending on your organization's specific use case, you may have a need for more layers. For example, you might have an additional "raw" layer for landing data in a specific format before it's transformed into the bronze layer. Or you might have a "platinum" layer for data that's been further refined and enriched for a specific use case. Regardless of the names and number of layers, the medallion architecture is flexible and can be tailored to meet your organization's particular requirements.
Move data across layers in Fabric
Moving data across medallion layers refines, organizes, and prepares it for downstream data activities. Within Fabric's lakehouse, there's more than one way to move data between layers, ensuring that you can choose the method that works for your team.
There are a few things to consider when deciding how to move and transform data across layers.
- How much data are you working with?
- How complex are the transformations you need to make?
- How often will you need to move data between layers?
- What tools are you most comfortable with?
Understanding the difference between data transformation and data orchestration helps you select the right tools for the job within Fabric.
Data transformation involves altering the structure or content of data to meet specific requirements. Tools for data transformation in Fabric include Dataflows (Gen2) and notebooks. Dataflows are a great option for smaller semantic models and simple transformations. Notebooks are a better option for larger semantic models and more complex transformations. Notebooks also allow you to save your transformed data as a managed Delta table in the lakehouse, ready for reporting.
Data orchestration refers to the coordination and management of multiple data-related processes, ensuring they work together to achieve a desired outcome. The primary tool for data orchestration in Fabric is pipelines. A pipeline is a series of steps that move data from one place to another, in this case, from one layer of the medallion architecture to the next. Pipelines can be automated to run on a schedule or triggered by an event.