Design a data integration and analytic solution with Azure Synapse Analytics
Azure Synapse Analytics combines features of big data analytics, enterprise data storage, and data integration. The service lets you run queries on serverless data or data at scale. Azure Synapse supports data ingestion, exploration, transformation, and management, and supports analysis for all your BI and machine learning needs.
Things to know about Azure Synapse Analytics
Azure Synapse Analytics implements a massively parallel processing (MPP) architecture and has the following characteristics.
The Azure Synapse Analytics architecture includes a control node and a pool of compute nodes.
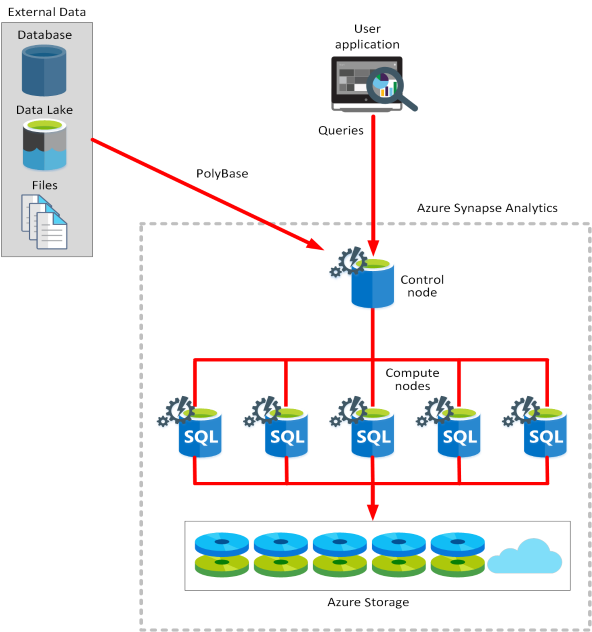
The control node is the brain of the architecture. It's the front end that interacts with all applications. The compute nodes provide the computational power. The data to be processed is distributed evenly across the nodes.
You submit queries in the form of Transact-SQL statements, and Azure Synapse Analytics runs them.
Azure Synapse uses a technology named PolyBase that enables you to retrieve and query data from relational and nonrelational sources. You can save the data read in as SQL tables within the Azure Synapse service.

Components of Azure Synapse Analytics
Azure Synapse Analytics is composed of the five elements:
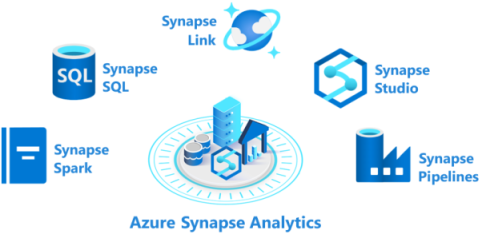
- Azure Synapse SQL pool: Synapse SQL offers both serverless and dedicated resource models to work with a node-based architecture. For predictable performance and cost, you can create dedicated SQL pools. For irregular or unplanned workloads, you can use the always-available, serverless SQL endpoint.
- Azure Synapse Spark pool: This pool is a cluster of servers that run Apache Spark to process data. You write your data processing logic by using one of the four supported languages: Python, Scala, SQL, and C# (via .NET for Apache Spark). Apache Spark for Azure Synapse integrates Apache Spark (the open source big data engine used for data preparation, data engineering, ETL, and machine learning).
- Azure Synapse Pipelines: Azure Synapse Pipelines applies the capabilities of Azure Data Factory. Pipelines are the cloud-based ETL and data integration service that allows you to create data-driven workflows for orchestrating data movement and transforming data at scale. You can include activities that transform the data as it's transferred, or you can combine data from multiple sources together.
- Azure Synapse Link: This component allows you to connect to Azure Cosmos DB. You can use it to perform near real-time analytics over the operational data stored in an Azure Cosmos DB database.
- Azure Synapse Studio: This element is a web-based IDE that can be used centrally to work with all capabilities of Azure Synapse Analytics. You can use Azure Synapse Studio to create SQL and Spark pools, define and run pipelines, and configure links to external data sources.
Analytical options
Azure Synapse Analytics supports a range of analytical scenarios. As you review the table, consider how the scenarios apply to the Tailwind Traders organization.
| Analysis | Scenario | Description |
|---|---|---|
| Descriptive | What is happening? | Azure Synapse applies the dedicated SQL pool capability that enables you to create a persisted data warehouse to analyze what now questions. You can make use of the serverless SQL pool to prepare data from files stored in a data lake to create a data warehouse interactively. |
| Diagnostic | Why is it happening? | You can use the serverless SQL pool capability within Azure Synapse to interactively explore data within a data lake. Serverless SQL pools can quickly enable a user to search for other data that might help them to understand why questions. |
| Predictive | What is likely to happen? | Azure Synapse Analytics uses its integrated Apache Spark engine and Azure Synapse Spark pools for predictive analytics. It combines this action with other services, such as Azure Machine Learning Services and Azure Databricks to help you answer what future questions. |
| Prescriptive | What needs to be done? | You can use prescriptive analytics real-time or near real-time data to help you identify solutions for your what action questions. Azure Synapse Analytics provides this capability through Apache Spark and Azure Synapse Link, and by integrating streaming technologies like Azure Stream Analytics. |
Business scenario
Let's examine a scenario where the company is serving clients with stock market information. You need to provide a combination of batch and stream processing to support the Tailwind Traders infrastructure. The up-to-the-second data might be used to help monitor real time, where an instant decision is required to make informed split-second buy or sell decisions. Historical data is equally important for a view of trends in performance. What kind of data warehouse and data integration solution would you recommend to provide access to the streams of raw data, and the prepared business information derived from this data? With Azure Synapse Analytics, you can ingest data from external sources and then transform and aggregate this data into a format suitable for analytics processing.
Things to consider when choosing Azure Data Factory or Azure Synapse Analytics
The following table compares storage solution criteria for using Azure Data Factory versus Azure Synapse Analytics. Review the criteria and consider which solution is optimal for Tailwind Traders.
| Compare | Azure Data Factory | Azure Synapse Analytics |
|---|---|---|
| Data sharing | Data can be shared across different data factories | Not supported |
| Solution templates | Solution templates are provided with the Azure Data Factory template gallery | Solution templates are provided in the Synapse Workspace Knowledge center |
| Integration runtime cross region flows | Cross region data flows are supported | Not supported |
| Monitor data | Data monitoring is integrated with Azure Monitor | Diagnostic logs are available in Azure Monitor |
| Monitor Spark Jobs for data flow | Not supported | Spark Jobs can be monitored for data flow by using Synapse Spark pools |
Azure Synapse Analytics is an ideal solution for many other scenarios. Consider the following options:
- Consider variety of data sources. When you have various data sources that use Azure Synapse Analytics for code-free ETL and data flow activities.
- Consider Machine Learning. When you need to implement Machine Learning solutions by using Apache Spark, you can use Azure Synapse Analytics for built-in support for Azure Machine Learning.
- Consider data lake integration. When you have existing data stored on a data lake and need integration with Azure Data Lake and other input sources, Azure Synapse Analytics provides seamless integration between the two components.
- Consider real-time analytics. When you require real-time analytics, you can use features like Azure Synapse Link to analyze data in real-time and offer insights.