Explore an MLOps architecture
As a data scientist, you want to train the best machine learning model. To implement the model, you want to deploy it to an endpoint and integrate it with an application.
Over time, you may want to retrain the model. For example, you can retrain the model when you have more training data.
In general, once you've trained a machine learning model, you want to get the model ready for enterprise-scale. To prepare the model and operationalize it, you want to:
- Convert the model training to a robust and reproducible pipeline.
- Test the code and the model in a development environment.
- Deploy the model in a production environment.
- Automate the end-to-end process.
Set up environments for development and production
Within MLOps, similarly to DevOps, an environment refers to a collection of resources. These resources are used to deploy an application, or with machine learning projects, to deploy a model.
Note
In this module, we refer to the DevOps interpretation of environments. Note that Azure Machine Learning also uses the term environments to describe a collection of Python packages needed to run a script. These two concepts of environments are independent from each other.
How many environments you work with, depends on your organization. Commonly, there are at least two environments: development or dev and production or prod. Plus, you can add environments in between like a staging or pre-production (pre-prod) environment.
A typical approach is to:
- Experiment with model training in the development environment.
- Move the best model to the staging or pre-prod environment to deploy and test the model.
- Finally release the model to the production environment to deploy the model so that end-users can consume it.
Organize Azure Machine Learning environments
When you implement MLOps, and work with machine learning models at a large scale, it's a best practice to work with separate environments for different stages.
Imagine your team uses a dev, pre-prod, and prod environment. Not everyone on your team should get access to all environments. Data scientists may only work within the dev environment with non-production data, while machine learning engineers work on deploying the model in the pre-prod and prod environment with production data.
Having separate environments makes it easier to control access to resources. Each environment can then be associated with a separate Azure Machine Learning workspace.
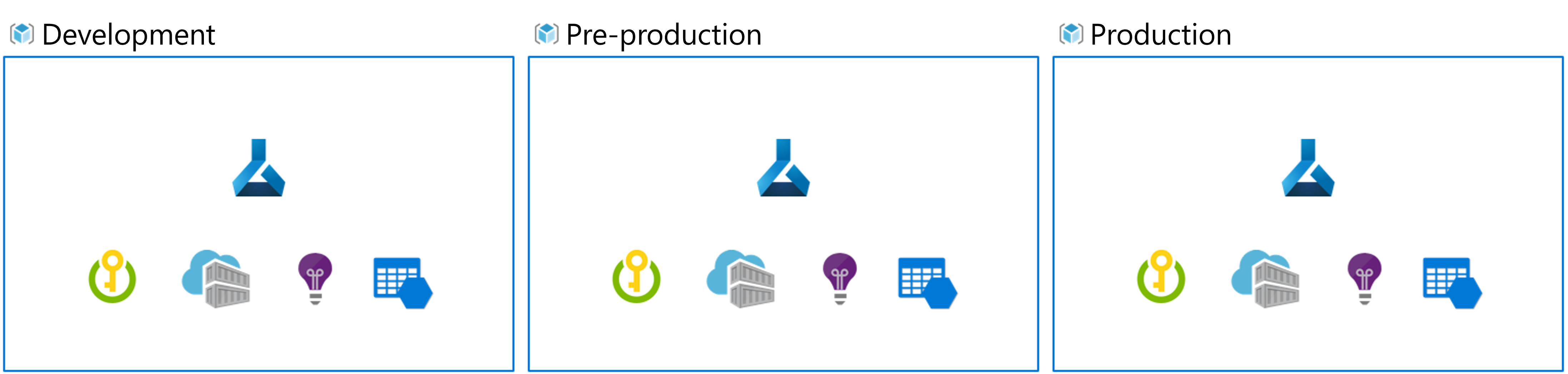
Within Azure, you use role-based access control (RBAC) to give colleagues the right level of access to the subset of resources they need to work with.
Alternatively, you can use only one Azure Machine Learning workspace. When you use one workspace for development and production, you have a smaller Azure footprint and less management overhead. However, RBAC applies to both dev and prod environments, which may mean that you're giving people too little or too much access to resources.
Tip
Learn more about best practices to organize Azure Machine Learning resources.
Design an MLOps architecture
Bringing a model to production means you need to scale your solution and work together with other teams. Together with other data scientists, data engineers and an infrastructure team, you may decide on using the following approach:
- Store all data in an Azure Blob storage, managed by the data engineer.
- The infrastructure team creates all necessary Azure resources, like the Azure Machine Learning workspace.
- Data scientists focus on what they do best: developing and training the model (inner loop).
- Machine learning engineers deploy the trained models (outer loop).
As a result, your MLOps architecture includes the following parts:
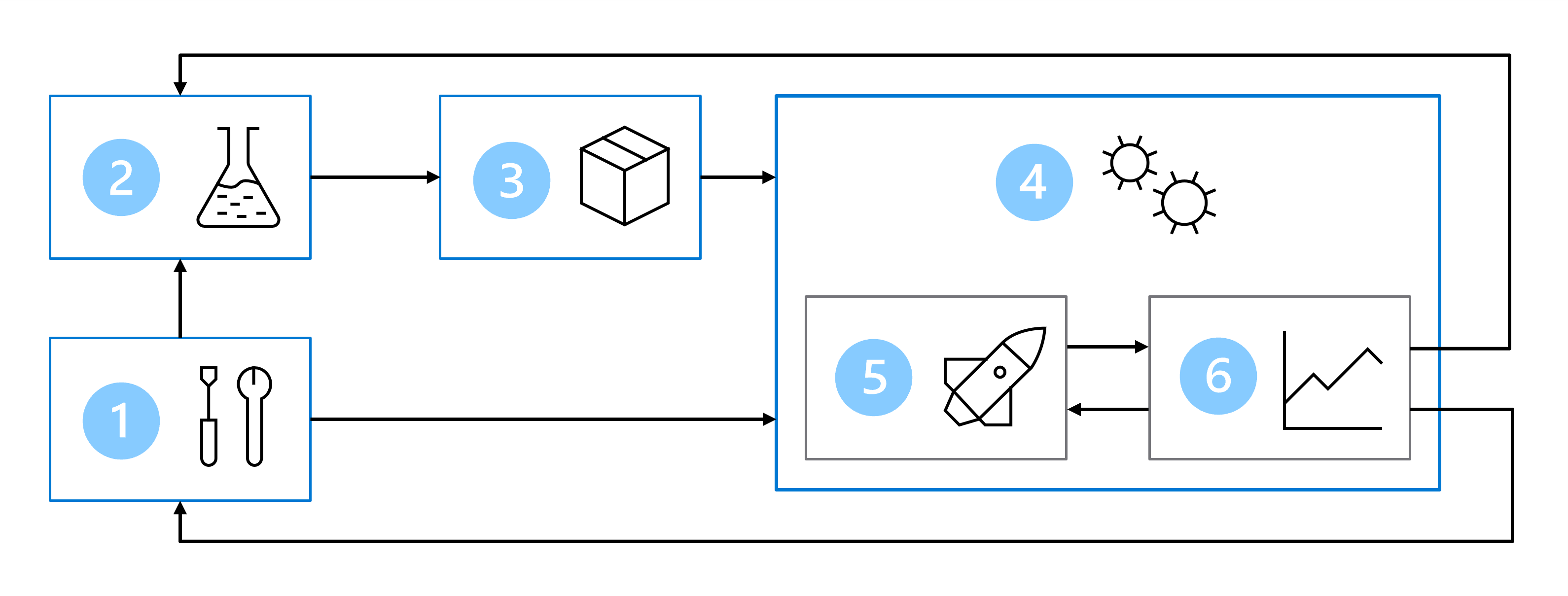
- Setup: Create all necessary Azure resources for the solution.
- Model development (inner loop): Explore and process the data to train and evaluate the model.
- Continuous integration: Package and register the model.
- Model deployment (outer loop): Deploy the model.
- Continuous deployment: Test the model and promote to production environment.
- Monitoring: Monitor model and endpoint performance.
When you're working with larger teams, you're not expected to be responsible of all parts of the MLOps architecture as a data scientist. To prepare your model for MLOps however, you should think about how to design for monitoring and retraining.