Build resilient application services
Your organization needs you to meet recovery requirements, while keeping down costs and complexity as much as possible.
In this unit, you learn how geo-redundancy and availability clusters can help you build resilience into your applications. You learn what's involved in failovers and failbacks for your applications. By the end of this unit, you'll understand why and how you should implement a monitoring and notification strategy.
Add geo-redundancy for your applications
You must be able to keep your applications running, regardless of what happens to the infrastructure that hosts them. Natural disasters and other problems could cause an entire geographic area to lose power or internet access. To respond to these problems gracefully and keep your applications running, you should make sure that geo-redundancy is in place. But geo-redundancy can be costly if it isn't done right.
You can use Azure to make your on-premises applications geo-redundant. The benefit of running a redundant infrastructure for your applications in Azure is that you're not responsible for maintaining and securing a physical location (along with the associated costs).
With Azure, you can add redundancy to your applications with regions that might be on the other side of the world, and there's no maintenance for you to handle. When maintenance is done for you, you can achieve geo-redundancy more easily and cost-effectively.
You can extend the on-premises network to a virtual network that's running a replica of your infrastructure in a different region inside Azure by using a VPN site-to-site connection. Azure Traffic Manager can help you monitor the health of your on-premises network. If something happens to the on-premises location, you could use the replica infrastructure in Azure that's located in a different region.
Similarly, you could set up geo-redundancy for your applications running inside Azure. For example, if your applications run on a group of Azure virtual machines in a virtual network, you can replicate the same setup in another region for geo-redundancy.
Through virtual network peering, you connect two separate virtual networks that are treated as one. Traffic for these two networks doesn't go through the public internet or a gateway. Resources can directly connect to other resources as though they're in the same network.
In this case, Traffic Manager looks at both regions for you by monitoring the health of each endpoint. If something happens to your primary region, Traffic Manager routes demand to your secondary region.
Add high-availability clusters
High-availability clusters help ensure that your workloads remain available and running with minimal downtime. You can use high-availability clusters in either of the following architecture types:
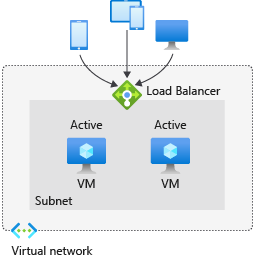
Active-active architecture: You distribute and load-balance demand between multiple nodes, such as two identical Azure virtual machines. You can have these Azure virtual machines running together and sharing the demand. You can also distribute demand to these nodes based on different routing methods.
The following diagram is a high-level example of an active-active cluster.
Active-passive architecture: You run Azure virtual machines where one node is active and in use, and the other node is passive and not in use. You use the passive node only when the active node has a failure.

In an active-active scenario, your nodes are running simultaneously. You have more running costs on a day-to-day basis in this scenario, if the machines have the same specifications as machines in an active-passive cluster.
Active-passive clusters can be more cost-effective than active-active clusters. Because the passive node isn't actively servicing user requests, you might have lower software licensing costs and lower resource costs. However, because you run only the active node in an active-passive cluster, you aren't as flexible to meet fluctuating demand as you are with an active-active cluster.
Resources like Azure availability sets help you achieve high availability through multiple nodes. If something affects one machine, like hardware failures or network outages, another machine can be available to keep things running.
You could also use Azure Virtual Machine Scale Sets to create an active-active cluster, and run machines that work to scale up and down in direct response to demand. Azure Load Balancer, through its rules for high-availability ports, can also help you use active-active or active-passive clusters for your machines.
Fail over and fail back your applications
Your organization has an infrastructure for its applications running on-premises. You must help ensure that your organization meets compliance requirements and achieves business continuity goals. By using Azure Site Recovery and Traffic Manager together, you can fail over to Azure and then fail back to keep the applications running.
If there's a failure, you can smoothly redirect client traffic to an infrastructure created for you in Azure. Use Traffic Manager to create a profile and set a priority routing method. Then, create two endpoints: one for your on-premises environment and another for the environment that you want to set up in Azure.
Because you normally run an on-premises environment and want another one in Azure only to fail over to, you can set the following two priorities:
- Priority 1 for the on-premises environment
- Priority 2 for your environment in Azure
These priorities are how Traffic Manager knows how to route the traffic between the two environments. Traffic Manager keeps routing traffic to your on-premises environment until it notices that the endpoint isn't healthy anymore. If that's the case, Traffic Manager routes traffic to your second environment, in Azure.
Azure Site Recovery starts running your virtual machines in Azure only if a failover is triggered. If a disaster occurs, you can use Azure Site Recovery to start a failover from the on-premises environment to the Azure environment.
Traffic Manager enables you to set the probing frequency to monitor your endpoints. You configure Traffic Manager to monitor the health of your endpoints every 30 seconds for regular probes, down to 10-second intervals for faster probes.
After a failover finishes, the clients are directed transparently to the new endpoint in Azure. When you've addressed the problem that caused the failover, you can use Azure Site Recovery to fail back again to your on-premises environment. Traffic Manager continues to probe for the health of your on-premises endpoint. When Traffic Manager identifies that the endpoint is healthy again, it directs traffic back to your on-premises environment.
