Implement stretch clusters
Traditionally, failover clusters provided high-availability protection from localized failures to one or more cluster nodes residing in the same physical location. You can use stretch clusters when it's necessary to provide the equivalent functionality across multiple physical locations.
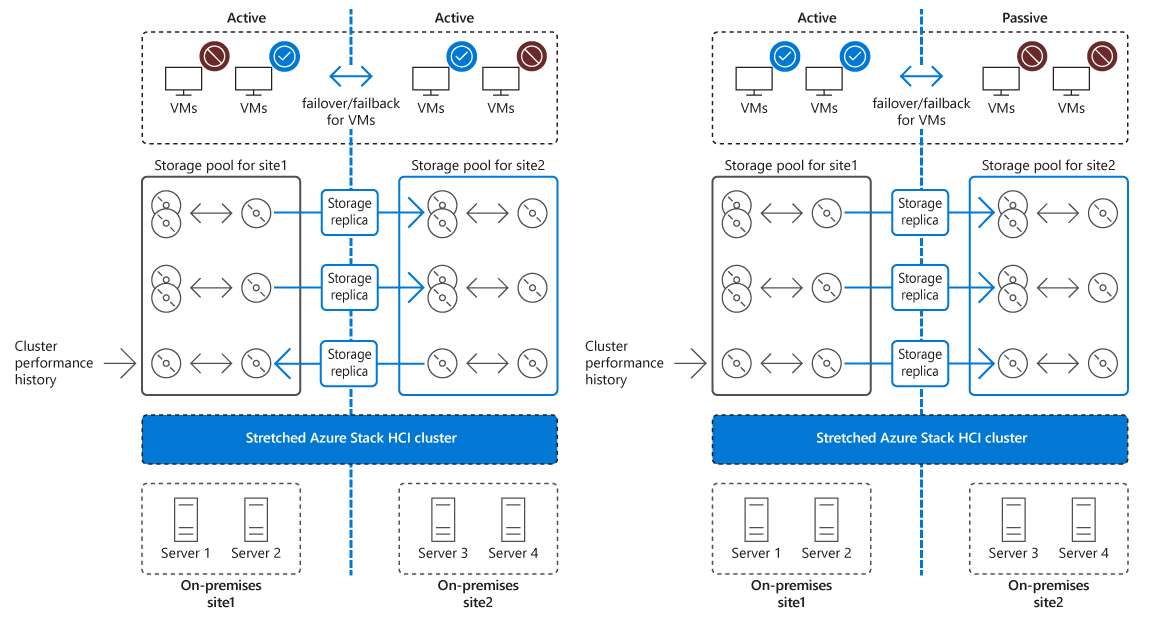
What are stretch clusters?
A stretch cluster implements high availability and disaster recovery across two separate physical locations. Both locations host a separate storage system, with unidirectional, synchronous replication from the primary site to the secondary site. If a failure affects the availability of the primary site, to minimize downtime, the cluster automatically transitions its workloads to nodes in the secondary site. For planned maintenance events at the primary site, you can use Hyper-V Live Migration to seamlessly transition workloads to the other site, which avoids downtime altogether.
Using stretch clusters offers several advantages over manually maintaining a disaster recovery site:
- Automatic replication and automatic failover of clustered workloads.
- Reduce administrative overhead.
- Minimize the possibility of human error, which is inherent to manual processes.
On the other hand, stretch clusters are more complex to design and implement. They also typically require an additional investment in storage and network infrastructure.
Overview of Storage Replica
Stretch clusters leverage Storage Replica, a Windows Server feature that provides replication of volumes between servers or clusters for disaster recovery. By using Storage Replica, stretch clusters can synchronize storage volumes attached to stretch cluster nodes in two separate locations.
Storage Replica supports synchronous and asynchronous replication:
- Synchronous replication replicates data over a low-latency network, within milliseconds of round-trip time, ensuring no data loss at the file system–level during a failover.
- Asynchronous replication replicates data over longer distances that are subject to higher latencies, but without a guarantee that both sites have identical copies of the data at the time of a failover.
Important
Stretch clusters require synchronous replication. This requirement imposes the limit of 5-ms round-trip network latency between two groups of cluster nodes in the replicated sites. Depending on the physical network connectivity characteristics, this constraint typically translates into a distance of about 20-30 miles.
Storage Replica features
The main features of Storage Replica are listed in the following table.
| Feature | Description |
|---|---|
| Block-level replication | With block-level replication, there's no possibility of file locking. |
| Simplicity | You can rely on Windows Admin Center to guide you through the process of creating a replication partnership between two servers. To deploy a stretch cluster, you can use a Failover Cluster Manager-based wizard. |
| Use of Server Message Block (SMB) 3.0 | Storage Replica relies on SMB 3.x, introduced in Windows Server 2012 and considerably enhanced in subsequent versions of Windows Server. All of SMB's advanced characteristics, such as SMB Multichannel and SMB Direct, are available to Storage Replica. |
| Security | Storage Replica features a wide range of security mechanisms, including packet signing, AES-128-GCM full data encryption, support for third-party encryption acceleration, and pre-authentication integrity man-in-the-middle attack prevention. Storage Replica also relies on Kerberos AES256 for all authentication between nodes. |
| Network constraints | In cases where there are multiple network paths between replicated volumes, you can configure Storage Replica traffic to use designated network adapters. This allows you to minimize potential impact of the replication traffic on production workloads. |
| Thin provisioning | You have the option of implementing thin provisioning in Storage Spaces Direct, minimizing initial replication times. |
Prerequisites for deploying stretch clusters
The prerequisites for implementing stretched clusters include:
Cluster nodes must be members of the same or trusted AD DS forest.
Each cluster node should have at least 2 GB of RAM and two CPU cores per server.
Each cluster node should be running Windows Server 2025 Datacenter or Windows Server 2016 Datacenter edition. It's possible to use Windows Server 2025 Standard edition, but such configuration supports replication of a single volume of up to 2 terabytes (TB) in size only.
Each cluster node should have at minimum 1 Gigabit Ethernet adapter for synchronous replication, although Remote Direct Memory Access (RDMA) is preferable.
Two sets of volumes (one for data and the other for logs) at the primary and the secondary site, with the following settings:
Disks must be initialized as GUID Partition Table (GPT), rather than master boot record (MBR).
- Volumes should be formatted with ReFS or NTFS.
- The data volumes sizes and sector sizes must match.
- The log volumes sizes and sector sizes must match.
- The log volumes should use faster storage than data volumes.
- The log volumes shouldn't be used for any other workloads.
Bi-directional connectivity via Internet Control Message Protocol (ICMP), SMB (port 445, plus port 5445 for SMB Direct) and Web Services-Management (WS-MAN) (port 5985) between the two sites.
A network between servers with enough bandwidth to match I/O writes of the clustered workloads and less than 5-ms round-trip latency.
Considerations for deploying a stretch cluster
Stretch clusters aren't suitable for every workload and every scenario. When you design a stretch cluster solution, clearly identify the organizational requirements and expectations. In addition, keep in mind that stretch clusters impose more management overhead than traditional clusters where all nodes reside within the same physical location. You should also carefully consider the optimal choice of the quorum witness to maximize its availability in the event of a disaster affecting an entire physical site.
Important
Stateful applications and services such as Microsoft SQL Server, Hyper-V, Microsoft Exchange Server, and AD DS should use their own, native resiliency mechanisms rather than rely on stretch clusters for high availability.
Considerations for failover and failback in a stretch cluster
As part of the planning for deployment of a stretch cluster, you need to define its failover and failback configuration, taking into account the following considerations:
- Infrastructure dependencies. You should clearly define the critical services, such as AD DS, DNS, and DHCP, that should remain available following a failover to the secondary site.
- Quorum model. It's important to choose the quorum model that preserves cluster functionality following a failover.
- Service publishing and name resolution. If you have services that are published to your internal or external users, such as email and webpages, be aware that in some cases, failover to another site requires name or IP address changes. If that's the case, you should have a procedure for changing DNS records in the internal or public DNS. To reduce downtime, we recommended that you reduce the Time to Live (TTL) value of critical DNS records.
- Client connectivity. In case of a disaster, a failover plan must accommodate connectivity from client applications to clustered workloads. This includes both internal and external clients.
- The failback procedure. You should plan and implement a failback process to perform after the primary site comes back online. Failback is just as important as a failover because if you perform it incorrectly, you can cause data loss and service downtime.
Create a stretch cluster
You can create a stretch cluster by using Windows Admin Center, Failover Cluster Manager or Windows PowerShell. Windows Admin Center simplifies implementation of stretch clusters by guiding you through the provisioning process and automating most configuration tasks. This includes support for:
- Hyperconverged clusters (Failover Clustering, Hyper-V, and Storage Spaces Direct).
- Storage clusters (Failover Clustering and Storage Spaces Direct).
Note
Creating a stretch cluster by using Failover Cluster Manager or Windows PowerShell is more complex. Both methods require performing each of the intermediate implementation steps. In the simplest terms, this starts with creating a traditional, non-stretched failover cluster consisting of all nodes in the primary and the secondary site. After you create the cluster and complete its validation, in each site, you create a separate set of storage volumes. Finally, you configure Storage Replica to replicate storage volumes between the two sites.