List the functionalities and components of Storage Replica
Availability of data is critical for business continuity. Traditionally, increased storage resiliency required expensive, vendor-specific solutions that relied on high-end hardware. Storage Replica eliminates this dependency, providing cost-efficient, hardware-agnostic high availability and disaster recovery capabilities.
What is Storage Replica?
Storage Replica is Windows Server technology that enables unidirectional replication between volumes residing on standalone or clustered servers for high availability or disaster recovery purposes. You can use Storage Replica to create stretch failover clusters that span two distinct physical sites, with all nodes staying in sync.
Storage Replica requires two NTFS file system (NTFS)-formatted or Resilient File System (ReFS)-formatted volumes at the source, and two at the destination, with each pair being used for data and replication logs, respectively. Each pair should have matching size and performance characteristics. The source data volume is referred to as primary, while the destination volume is known as secondary.
The servers hosting these volumes form a replication partnership. Such partnership can include multiple data volumes, but all of them use the same log volume. Each server, together with all its volumes that are part of a replication partnership, constitutes a replication group.
Important
You must never use log volumes for other workloads.
Storage Replica features
The main features of Storage Replica include:
- Block-level replication. With block-level replication, there's no possibility of file locking.
- Simplicity. You can rely on Windows Admin Center to guide you through the process of creating a replication partnership between two servers. To deploy a stretch cluster, you can use a Failover Cluster Manager-based wizard.
- Support for physical servers and virtual machines. All Storage Replica capabilities are available to both virtual guest-based and host-based deployments. This means that guests can replicate their data volumes even if running on non-Windows virtualization platforms or in public clouds.
- Use of Server Message Block (SMB) 3.x. Storage Replica relies on SMB 3.x, which was introduced in Windows Server 2012 and then considerably enhanced in subsequent versions of Windows Server. All of SMB's advanced characteristics, such as SMB Multichannel and SMB Direct, are available to Storage Replica.
- Security. Storage Replica features a wide range of security mechanisms, including packet signing, AES-128-GCM full data encryption, support for third-party encryption acceleration, and pre-authentication integrity man-in-the-middle attack prevention. Storage Replica relies on Kerberos AES256 for all authentication between nodes.
- High performance initial sync. Storage Replica supports seeded initial sync, which involves copying a subset of data from a source volume to the target via backup or removable media. This way, initial replication consists only of the difference between the two volumes, which shortens the duration of the initial sync and limits bandwidth usage.
- Consistency groups. Write ordering provides assurance that writes of applications such as SQL Server take place in the same sequence at the source as on the replicated volumes.
- Delegated administration. You can delegate permissions to manage replication without needing to grant Administrator-level privileges across replicated nodes.
- Network constraints. In cases where there are multiple network paths between replicated volumes, you can configure Storage Replica traffic to use designated network adapters. This minimizes the potential impact of the replication traffic on production workloads.
- Thin provisioning. You have the option of implementing thin provisioning in Storage Spaces Direct, minimizing initial replication times.
Synchronous and asynchronous replication
Storage Replica supports two types of replication:
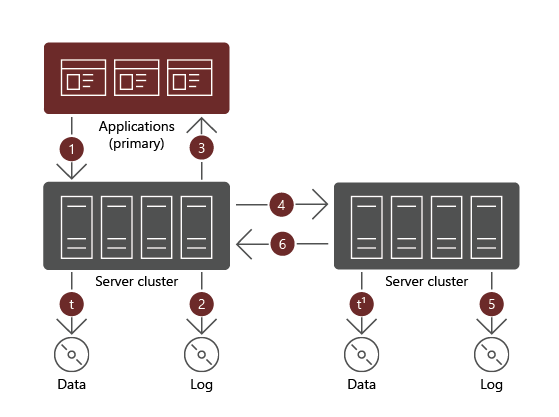
- Synchronous replication replicates volumes between sites that are relatively close to one another. Replication is crash-consistent, which ensures zero data loss at the file system–level during a failover.
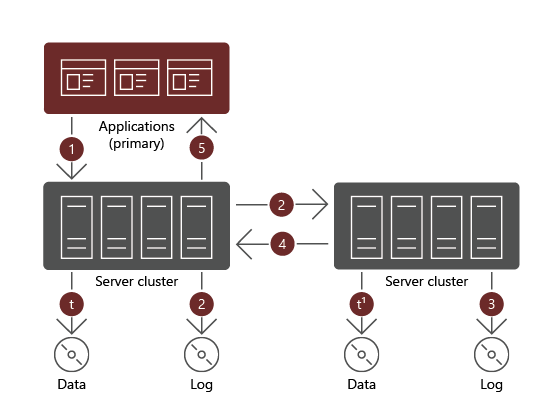
- Asynchronous replication enables replication across longer distances in cases where network round-trip latency exceeds 5 milliseconds (ms), however, it's subject to data loss. The extent of data loss depends on the lag of replication between the source and target volumes.
When using synchronous replication, a data write must complete successfully on both volumes. If that isn't the case, the workload initiating the write must retry the same operation. With synchronous replication, the data on both volumes is identical.
Tip
Use synchronous replication when it's imperative that you avoid data loss.
Synchronous replication requires low network latency to minimize the wait time for the acknowledgment of the remote write. This requirement limits the distance between the servers or clusters hosting each volume.
When using asynchronous replication, after a data write completes successfully on the primary volume, the workload initiating the write receives a confirmation and can proceed with another I/O operation. The corresponding data writes take place afterwards on the secondary volume, without affecting the primary volume.