Use data pipelines to load a warehouse
Microsoft Fabric’s Warehouse provides integrated data ingestion tools, enabling users to load and ingest data into warehouses on a large scale through either coding or noncoding experiences.
Data pipeline is the cloud-based service for data integration, which enables the creation of workflows for data movement and data transformation at scale. You can create and schedule data pipelines that can ingest and load data from disparate data stores. You can build complex ETL, or ELT processes that transform data visually with data flows.
Most of the functionality of data pipelines in Microsoft Fabric comes from Azure Data Factory, allowing for seamless integration and utilization of its features within the Microsoft Fabric ecosystem.
Note
All data in a Warehouse is automatically stored in the Delta Parquet format in OneLake.
Create a data pipeline
There are a few ways to launch the data pipeline editor.
From the workspace: Select + New, then select Data pipeline. If it's not visible in the list, select More options, then find Data pipeline under the Data Factory section.

From the warehouse asset - Select Get Data, and then New data pipeline.
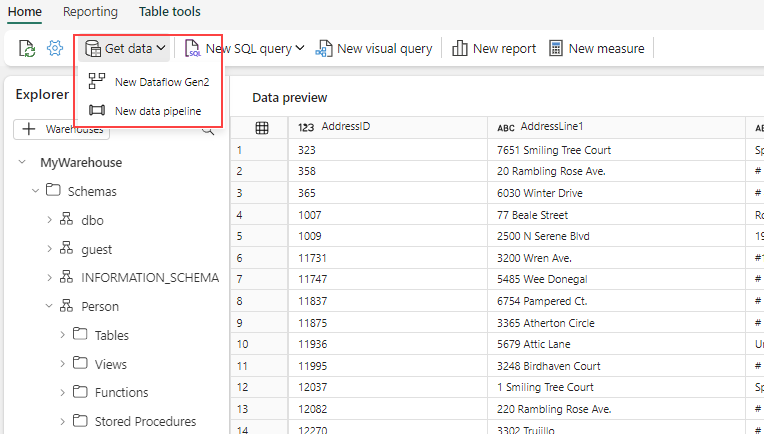
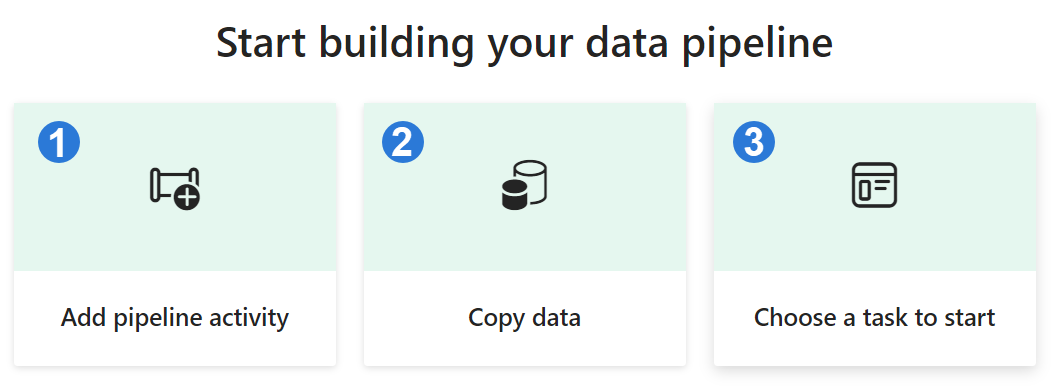
There are three options available when creating a pipeline.
| Option | Description |
|---|---|
| 1. Add pipeline activity | Launches the pipeline editor where you can create your own pipeline. |
| 2. Copy data | Launches an assistant to copy data from various data sources to a data destination. A new pipeline activity is generated at the end with a preconfigured Copy Data task. |
| 3. Choose a task to start | You can choose from a collection of predefined templates to assist you in initiating pipelines based on many scenarios. |
Configure the copy data assistant
The copy data assistant provides a step-by-step interface that facilitates the configuration of a Copy Data task.
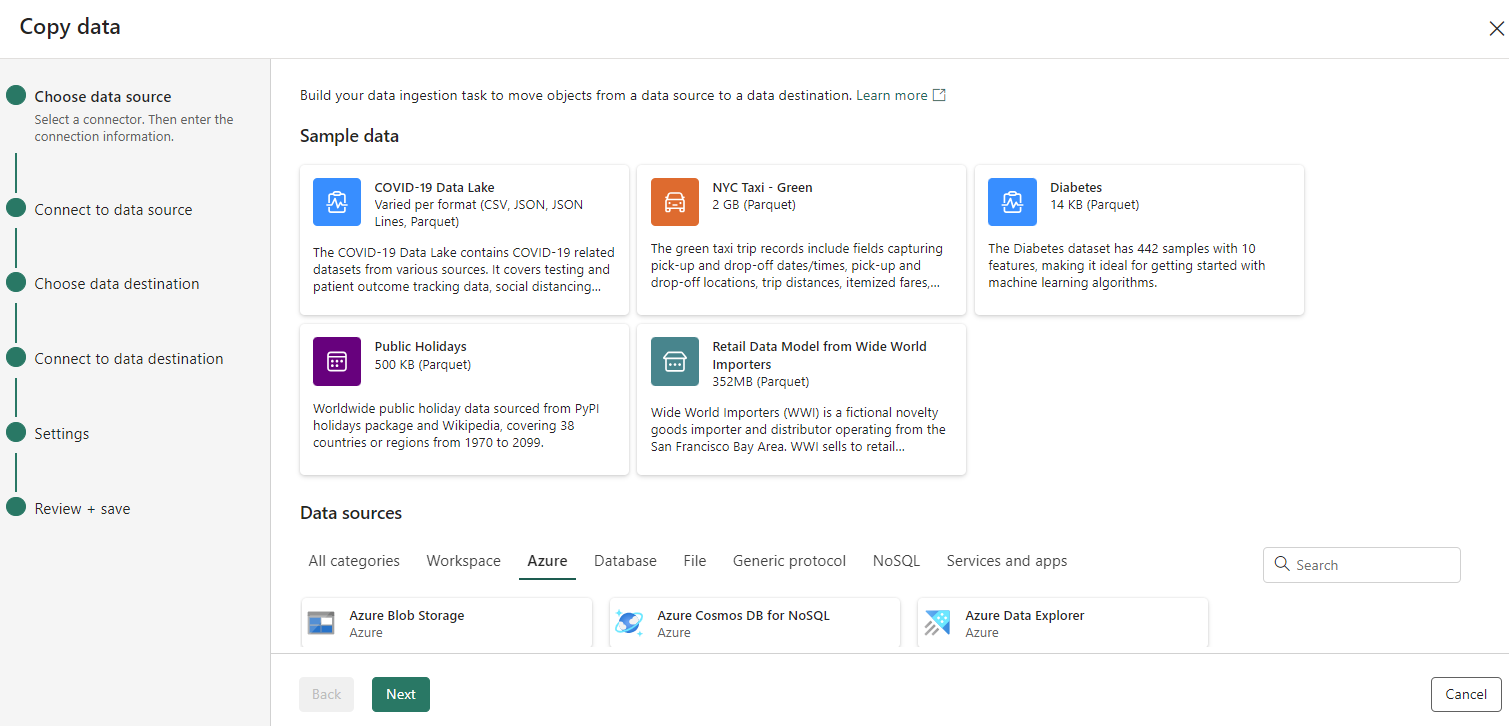
- Choose data source: Select a connector, and provide the connection information.
- Connect to a data source: Select, preview, and choose the data. This can be done from tables or views, or you can customize your selection by providing your own query.
- Choose data destination: Select the data store as the destination.
- Connect to data destination: Select and map columns from source to destination. You can load to a new or existing table.
- Settings: Configure other settings like staging, and default values.
After you copy the data, you can use other tasks to further transform and analyze it. You can also use the Copy Data task to publish transformation and analysis results for business intelligence (BI) and application consumption.
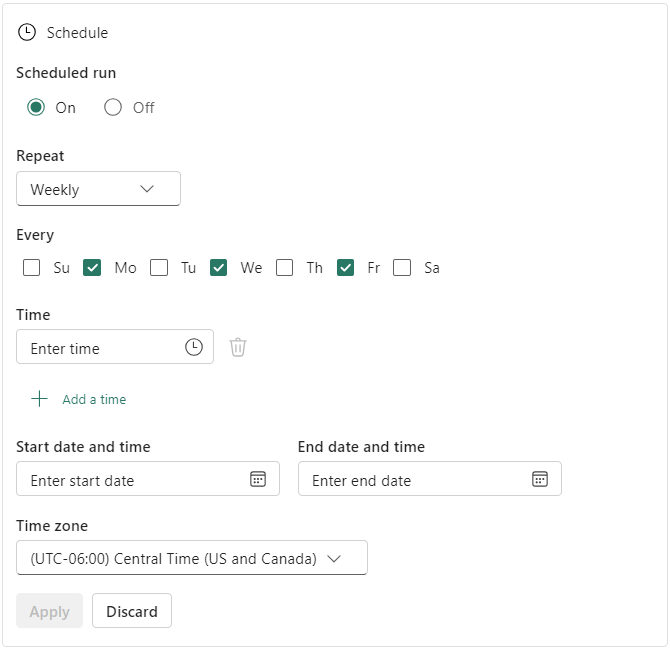
Schedule a data pipeline
You can schedule your data pipeline by selecting Schedule from the data pipeline editor.
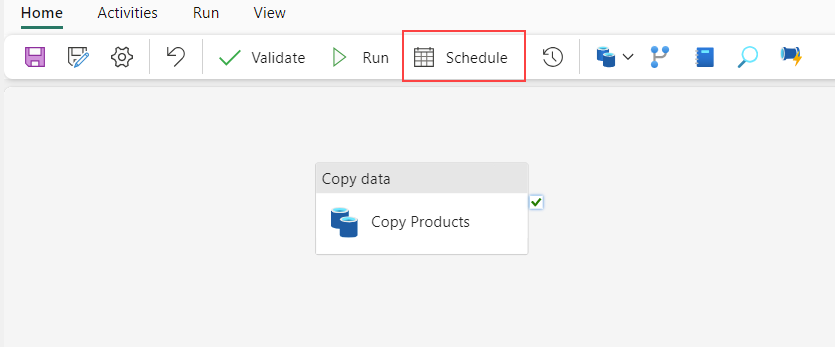
You can also configure the schedule by selecting Settings in the Home menu in the data pipeline editor.
We recommend data pipelines for a code-free or low-code experience due to the graphical user interface. They're ideal for data workflows that run at a schedule, or that connects to different data sources.
To learn more about data pipelines, see Ingest data into your Warehouse using data pipelines.