Perform node maintenance
Contoso's current standard operating procedures were designed for legacy workloads, running primarily on Windows Server 2012 R2 and older versions of Linux distributions. They do not take into account the considerations that are applicable to Azure Stack HCI virtualization and clustering technologies. As part of your evaluation of Azure Stack HCI, you decide to test and document the common maintenance tasks that involve restarting individual Azure Stack HCI cluster nodes or temporarily taking them offline for maintenance.
Overview of the Azure Stack HCI cluster maintenance tasks
Azure Stack HCI offers built-in resiliency, protecting its workloads from the impact of hardware failures of its individual components, including up to two cluster nodes. However, there are specific guidelines you should follow when intentionally restarting cluster nodes or taking them offline for planned maintenance.
The need for the specific guidelines results from the fact that each node of an Azure Stack HCI cluster not only provides compute resources, but also hosts storage volumes, which are distributed and synchronized across multiple cluster nodes. Shutting down a cluster node disrupts this synchronization. Therefore, any changes to local replicas of clustered volumes that take place while the node is offline must be resynchronized after the node's operating system starts running again.
Another important consideration is the maximum number of cluster nodes that can be offline at the same time without incurring data loss. As described earlier in this module, Storage Spaces Direct tolerates at most two concurrent node failures for four or more nodes with witness, regardless of the cluster size.
To perform a cluster node maintenance in an orderly fashion with minimal impact to overall resiliency and performance, you should use the following sequence of steps:
Verify that all of the cluster storage disks are online and all of the cluster storage volumes are reporting the healthy status.
Pause the node in order to trigger live migration of all VMs running on that node to other cluster nodes.
Note
This process is referred to as draining. After the draining process starts, it is not possible to add roles to the node until that node is resumed.
Shut down the operating system on the cluster node.
Perform the planned maintenance tasks while the operating system is offline.
Start the operating system and wait for the boot process to complete.
Resume the cluster node.
Note
Resuming the cluster node will restart the storage synchronization (frequently referred to as resync. To determine whether the resync has completed, verify that the cluster storage volumes are reporting the healthy status again.
Note
You should wait for resync to complete before taking any other cluster nodes offline.
Performing Azure Stack HCI cluster maintenance tasks by using Windows Admin Center
Windows Admin Center simplifies initiating and completing cluster node maintenance tasks by providing a graphical interface for implementing the required steps:
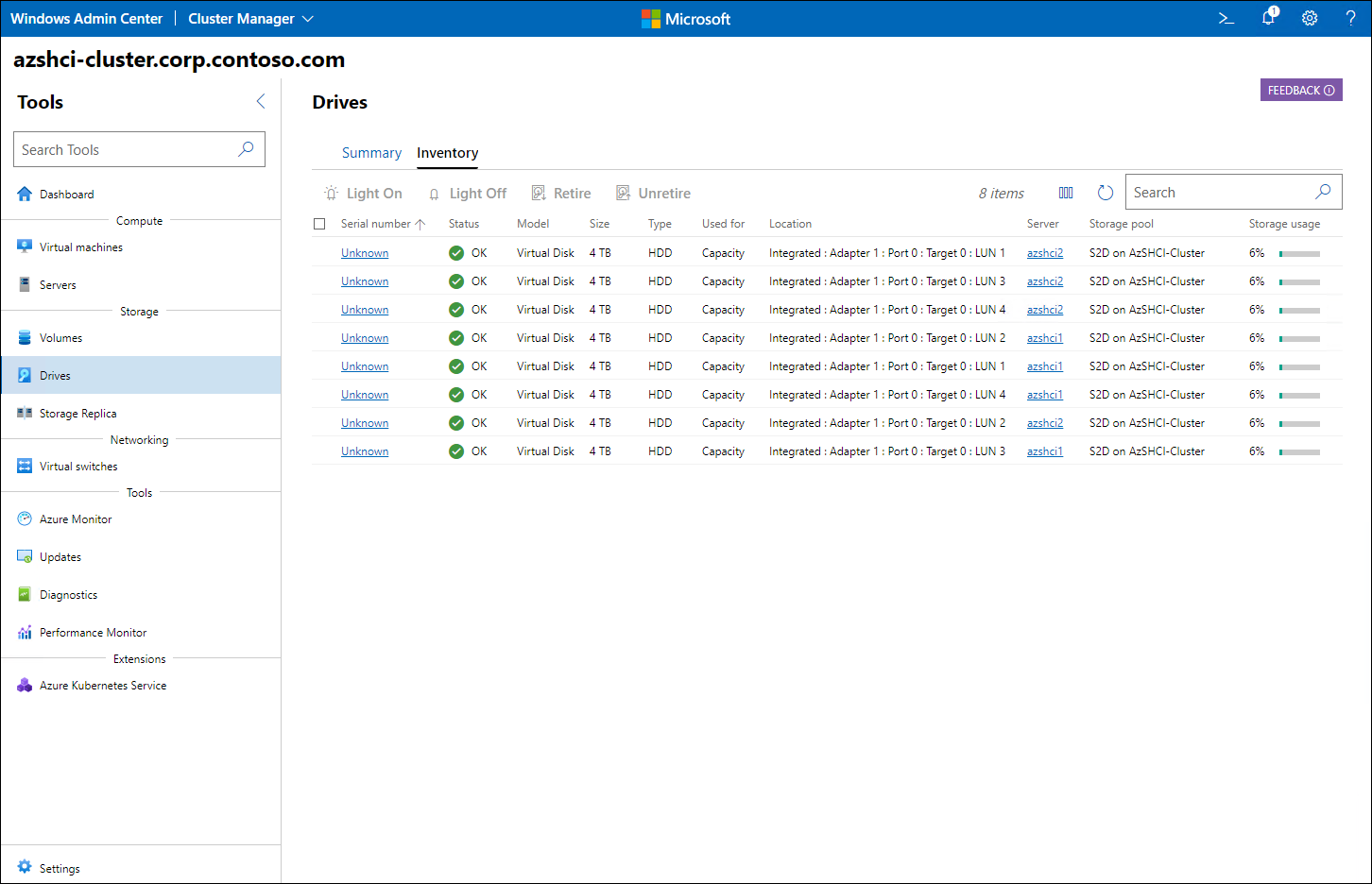
After you connect to the target cluster, to verify that all the disks are listed with the online status (labeled OK), use the Tools menu to browse to the Storage pane to view the inventory of disks.
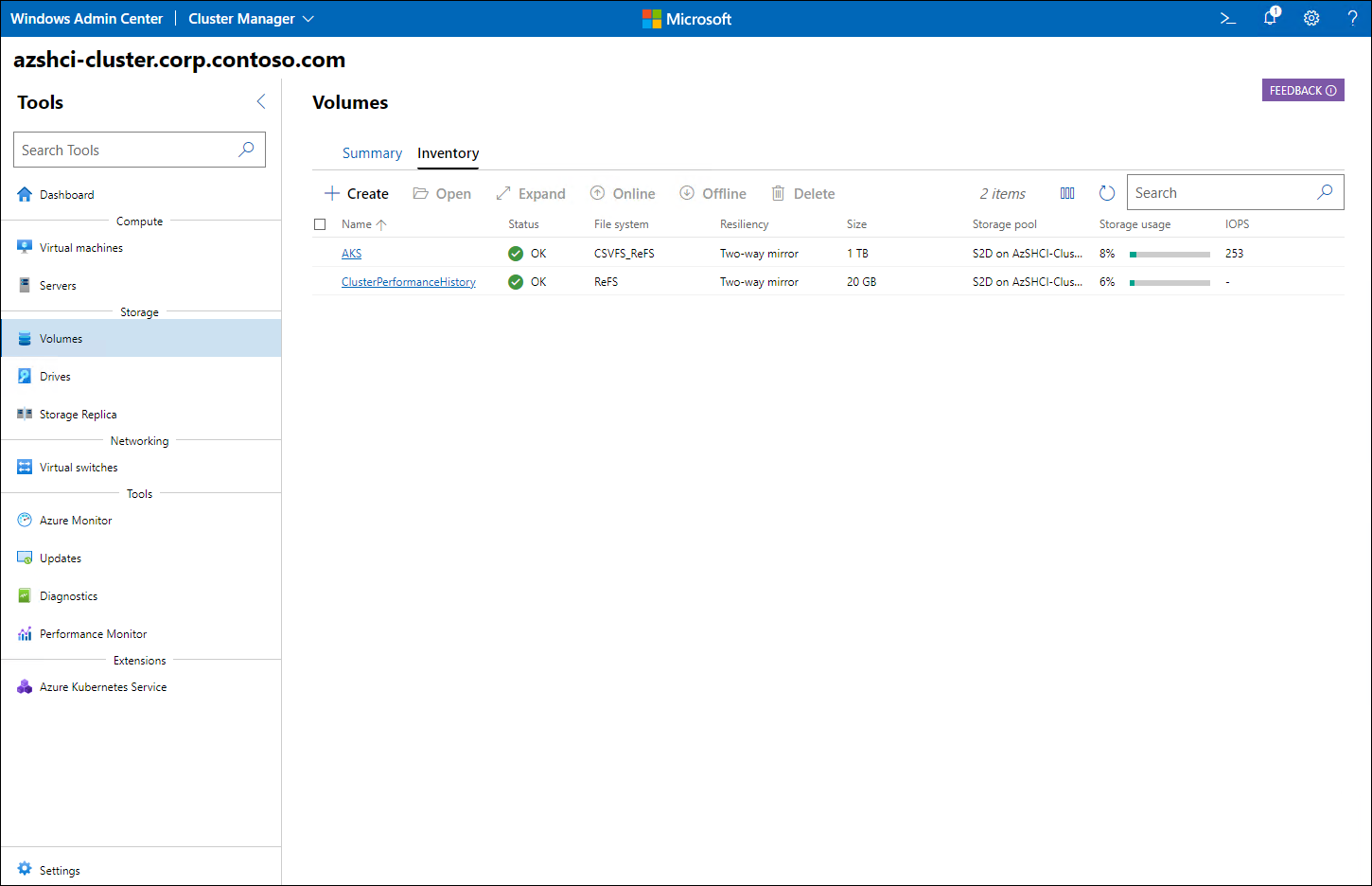
From the Storage pane, you can access the list of volumes to verify that each volume is listed with the healthy status (labeled OK).
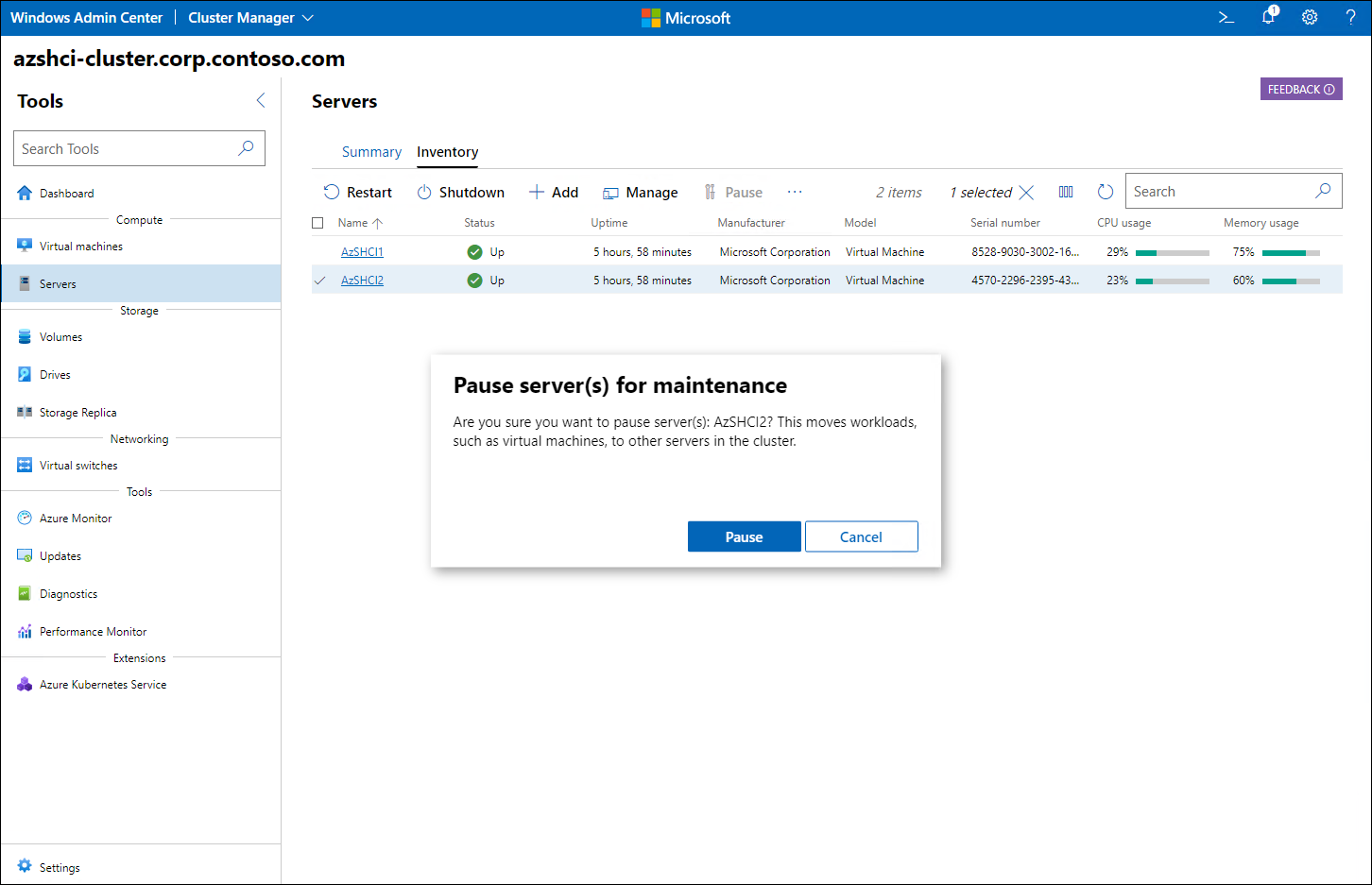
From the Cluster Manager interface in Windows Admin Center, you can browse to the Compute pane, display the server inventory, and pause any of the cluster nodes to initiate the draining process.
Note
During the process of pausing of a cluster node, the node status will transition from In maintenance, Draining to In maintenance, Drain completed.
Note
Azure Stack HCI will generate an alert and stop the draining process if the status of any of the cluster storage volumes changes to unhealthy.
You can resume the cluster node from the same interface that you used to pause it.