Analyze case content
When the number of collected documents is large, it can be difficult to review them all. Microsoft Purview eDiscovery (Premium) provides the following tools to analyze the documents:
- Near duplicate detection
- Email threading
- Themes
Each of these tools is introduced in this unit. These tools help an organization to:
- reduce the volume of documents to be reviewed without any loss in information.
- help you organize the documents in a coherent manner.
Before an organization uses these document analysis tools, it may want to begin by analyzing the data in the review set.
Analyze data in a review set in eDiscovery (Premium)
Organizations often have large volumes of documents and email messages that must be reviewed. In this situation, they may want to start by quickly analyzing the total body of data to identify trends or key statistics. This process can help the organization develop a review strategy. The eDiscovery (Premium) dashboard for review sets can be used to quickly analyze the content.
Run analytics for a review set
To analyze data in a review set:
- Configure analytics settings for your case. For more information, see Configure search and analytics settings.
- Open the review set you want to analyze.
- Select Analytics on the menu bar. In the drop-down menu that appears, select Run Document & email analytics.
An organization can check the progress of analysis on the Jobs tab of the case. After analysis is completed, it can:
- View the Analytics report.
- Run queries within your review set on outputs of the analysis. For more information, see Query within your review set.
- View the documents that are related to a given document. For more information, see Reviewing data in review set.
Use the For Review filter query
After an organization runs analytics for the review set, it can use an automatically generated filter query that's called For Review. This query filters the review set to exclude immaterial, duplicate, or non-inclusive items. This process leaves the organization with only the items that are representative, unique, and inclusive in the review set.
To apply the For Review filter query to a review set, select Saved filter queries. In the dropdown list that appears, select [AutoGen] For Review.
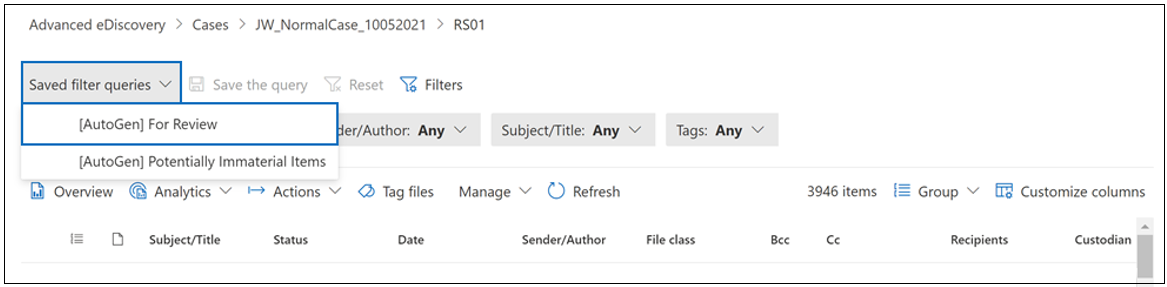
Here's the syntax for the For Review filter query:
(((FileClass="Email") AND (InclusiveType="InclusiveMinus" OR InclusiveType="Inclusive")) OR ((FileClass="Attachment") AND (UniqueInEmailSet="true")) OR ((FileClass="Document") AND (MarkAsRepresentative="Unique")) OR (FileClass="Conversations"))">">
The following list describes the result of the filter query in terms of what content is displayed after you apply it to the review set.
- Email. Displays items that are marked as Inclusive or InclusiveMinus.
- Inclusive. An inclusive item is the final message in an email thread. It contains all previous content in the email thread.
- Inclusive minus. An inclusive minus item contains one or more attachments associated with the specific message in the email thread. A reviewer can use the inclusive minus value to determine which specific messages in the email thread have associated attachments.
- Attachments. Filters out duplicate attachments in the same Email Set. Only attachments that are unique in an email thread are displayed.
- Documents and other. Filters out duplicate documents. Only documents that are unique in the review set are displayed.
- Teams conversations. All Teams (and Viva Engage) conversations in the review set are displayed.
For more information about inclusive types and document uniqueness, see the section on Email threading that appears later in this unit.
Analytics report
To view the Analytics report for a review set:
- Open the review set.
- Select Analytics on the menu bar. In the drop-down menu that appears, select Show reports.
As a result of the analysis, the Analytics report has seven components:
- Target population. The number of email messages, attachments, and loose documents found in the review set.
- Documents (excluding attachments). The number of loose documents that are:
- Pivots
- Unique near duplicates of a pivot
- An exact duplicate of another document
- Emails. The number of email messages that are marked as:
- Inclusive
- Inclusive copy
- Inclusive minus
- None of the above
- Attachments. The number of email attachments that are:
- Unique
- Duplicates of another email attachment in the review set
- Number documents by file type. The number of files, identified by file extension.
- Documents by source. A summary of content by its original data source.
- Documents aggregated by process. A summary of content by review set processes.
Document analysis tool: Near duplicate detection in eDiscovery (Premium)
Consider a set of documents to be reviewed in which a subset is based on the same template and has mostly the same boilerplate language, with a few differences here and there. If a reviewer could identify this subset, review one of the documents thoroughly, and review the differences for the rest, they wouldn't have missed any unique information. It also would have taken the reviewer just a fraction of the time that it would have taken to read all documents cover to cover.
Note
Near duplicate detection groups textually similar documents together to help an organization make its review process more efficient.
How does duplicate detection work?
When near duplicate detection is run, the system parses every document with text. Then, it compares every document against each other to determine whether their similarity is greater than the set threshold. If it is, the documents are grouped together.
Once all documents have been compared and grouped, a document from each group is marked as the Pivot. When an organization reviews its documents, it can review a Pivot document first. It can then review the other documents in the same near duplicate set. The organization can focus on the difference between the pivot and the document that's in review.
Document analysis tool: Email threading in eDiscovery (Premium)
Consider an email conversation that has been going on for a while. In most cases, the last message in the email thread will include the contents of all the preceding messages. Therefore, reviewing the last message provides a complete context of the conversation that happened in the thread.
Note
Email threading identifies such messages so that reviewers can review a fraction of collected documents without losing any context.
How does email threading work?
Email threading parses each email thread. It then deconstructs it to individual messages. Each email thread is a chain of individual messages.
Microsoft Purview eDiscovery (Premium) analyzes all email messages in the review set to determine whether an email message has unique content. It can also determine if the chain (parent messages) is wholly contained in the final message in the email thread. At the end of the process, email messages are divided into four categories:
- Inclusive. An Inclusive email is the final email message in an email thread. It contains all the previous content of that email thread.
- Inclusive minus. An email message is designated as Inclusive minus if there are one or more attachments associated with the specific message within the email thread. A reviewer can use the Inclusive minus value to determine which specific email message within the thread has associated attachments.
- Inclusive copy. An email message is considered an Inclusive copy if it's an exact copy of an Inclusive or Inclusive minus message.
- None. The None value indicates the content of the message is wholly contained in at least one other email message that's marked as Inclusive or Inclusive minus.
How is it different from conversations in Outlook?
At a glance, email threading sounds similar to conversation groupings in Outlook. However, there are some important distinctions. Consider an email conversation that got forked into two conversations. For example, someone responded to an email that isn't the latest in the conversation. As a result, the last two emails in the conversation both have unique content.
Outlook still groups the emails into a single conversation. Why? Because reading only the last email could result in missing the context of the second-to-last email, which also contains unique content.
Because email threading parses out each email into individual components and compares them, email threading would mark both of the last two emails as inclusive. This process ensures that you won't miss any context as long as you read all emails marked as inclusive.
Document analysis tool: Themes in eDiscovery (Premium)
How does a person write a document? They generally start with one or more ideas they want to convey in the document. They then compose the document using words that align with the ideas. The more prevalent an idea is, the more frequent the words that are related to that idea tend to be.
This process informs how people consume documents as well. The important things to understand from reading a document are:
- the ideas the document is trying to convey.
- where ideas appear.
- what the relationships are between the ideas.
These items can be extended to how a person wants to consume a set of documents. They want to see:
- which ideas are present in the sets.
- which documents are talking about those ideas.
- see documents that discuss similar ideas if they find a particular document of interest.
Note
The Themes functionality in eDiscovery (Premium) attempts to mimic how humans reason about documents. It does so by analyzing the themes that are discussed in a review set and assigning a theme to documents in the review set.
In eDiscovery (Premium), Themes goes one step further and identifies the dominant theme in each document. The dominant theme is the one that appears the most often in a document.
How does Themes work?
The Themes functionality analyzes documents with text in a review set. It does so to parse out common themes that appear across all the documents in the review set.
eDiscovery (Premium) assigns those themes to the documents in which they appear. It also labels each theme with the words used in the documents that are representative of the theme. Because a document can contain various types of subject matter, eDiscovery (Premium) often assigns multiple themes to documents. The theme that appears most prominently in a document is designated as its dominant theme.
Knowledge check
Choose the best response for the following question. Then select “Check your answers.”