Understand table distribution design
When data is loaded into Synapse Analytics dedicated SQL pools, the datasets are broken up and dispersed among the compute nodes for processing, and then written to a decoupled and scalable storage layer. This action is termed sharding.
The design decisions around how to split and disperse this data among the nodes and then to the storage is important to querying workloads, as the correct selection minimizes data movement that is a primary cause of performance issues in an Azure Synapse dedicated SQL Pool environment.
There are three main table distributions available in Synapse Analytics SQL Pools that will be described below:
Selecting the correct table distribution can have an impact on the data load and query performance as follows:
Round robin distribution
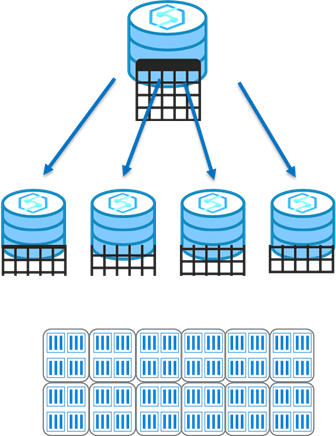
This is the default distribution created for a table and delivers fast performance when used for loading data.
A round-robin distributed table distributes data evenly across the table but without any further optimization. A distribution is first chosen at random and then buffers of rows are assigned to distributions sequentially.
It's quick to load data into a round-robin table, but query performance can often be better with hash distributed tables for larger datasets.
Joins on round-robin tables may negatively affect query workloads, as data that is gathered for processing then has to be reshuffled to other compute nodes, which take additional time and processing.
Hash distribution
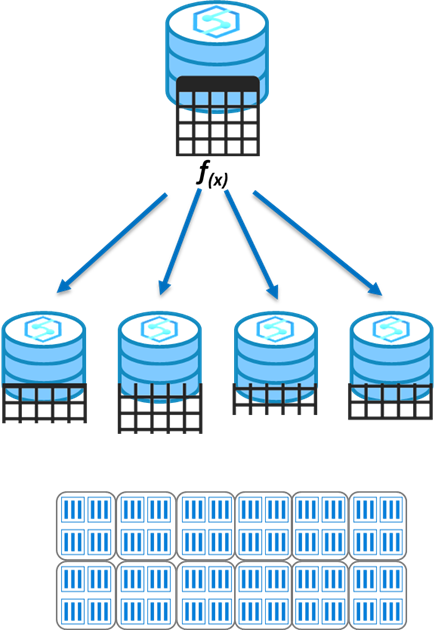
This distribution can deliver the highest query performance for joins and aggregations on large tables.
To shard data, a hash function is used to deterministically assign each row to a distribution. In the table definition, one of the columns is designated as the distribution column.
There are performance considerations for the selection of a distribution column, such as distinctness, data skew, and the types of queries that run on the system.
Performance considerations
When choosing a hash column it's best to choose a column that will evenly distribute the data across all distributions that will allow for approximately the same number of rows within each distribution.
- Choose a column with a high number of unique values, for instance if your organization may operate in all 50 states within the United States, ensure that you have a good distribution of each StateID to prevent skew which impacts the time each query results is returned and impacts performance.
- Choose a column without Null values or very few null values, this can also result in an imbalance of data on a single distribution.
- Don't choose a date column as all data for a specific date will land in the same place and if it's a daily report that line of business users filter using the same date, only 1 of the 60 distributions will bear the bulk of the workload.
Replicated tables
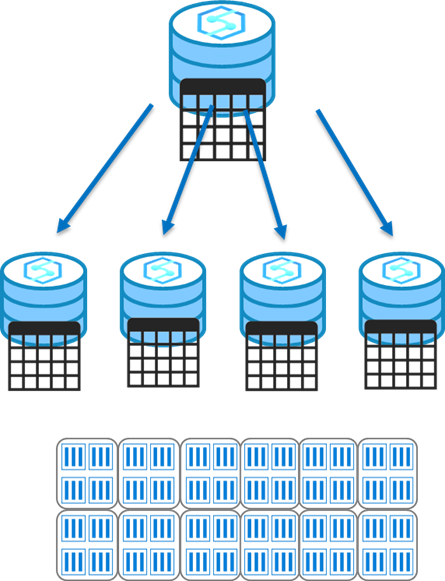
A replicated table provides the fastest query performance for small tables which with compression should be less than 2GB as a starting point, static data can be larger.
A table that is replicated caches a full copy of the table on each compute node. Consequently, replicating a table removes the need to transfer data among compute nodes before a join or aggregation. As such extra storage is required and there is additional overhead that is incurred when writing data, which make large tables impractical.
Data modifications will cause the cached copy to be invalidated, and require the table be recached. You should use sys.pdw_replicated_table_cache_state in a query like the one below to determine which replicated tables have been modified but not rebuilt.
SELECT [ReplicatedTable] = t.[name]
FROM sys.tables t
JOIN sys.pdw_replicated_table_cache_state c
ON c.object_id = t.object_id
JOIN sys.pdw_table_distribution_properties p
ON p.object_id = t.object_id
WHERE c.[state] = 'NotReady'
AND p.[distribution_policy_desc] = 'REPLICATE'
The next step would be to force a rebuild using the results from the code above, such as:
SELECT TOP 1 * FROM [ReplicatedTable]
Additional replicated table performance considerations
Some additional items to consider when looking at creating a replicated table include the following situations which will negatively impact performance:
- The table has frequent insert, update, and delete operations. The data manipulation language (DML) operations require a rebuild of the replicated table. Rebuilding frequently can cause slower performance.
- The SQL pool is scaled frequently. Scaling a SQL pool changes the number of Compute nodes, which incurs rebuilding the replicated table.
- The table has a large number of columns, but data operations typically access only a small number of columns. In this scenario, instead of replicating the entire table, it might be more effective to distribute the table, and then create an index on the frequently accessed columns. When a query requires data movement, SQL pool only moves data for the requested columns.