Configure early termination
Hyperparameter tuning helps you fine-tune your model and select the hyperparameter values that will make your model perform best.
For you to find the best model, however, can be a never-ending conquest. You always have to consider whether it's worth the time and expense of testing new hyperparameter values to find a model that may perform better.
Each trial in a sweep job, a new model is trained with a new combination of hyperparameter values. If training a new model doesn't result in a significantly better model, you may want to stop the sweep job and use the model that performed best so far.
When you configure a sweep job in Azure Machine Learning, you can also set a maximum number of trials. A more sophisticated approach may be to stop a sweep job when newer models don't produce significantly better results. To stop a sweep job based on the performance of the models, you can use an early termination policy.
When to use an early termination policy
Whether you want to use an early termination policy may depend on the search space and sampling method you're working with.
For example, you may choose to use a grid sampling method over a discrete search space that results in a maximum of six trials. With six trials, a maximum of six models will be trained and an early termination policy may be unnecessary.
An early termination policy can be especially beneficial when working with continuous hyperparameters in your search space. Continuous hyperparameters present an unlimited number of possible values to choose from. You'll most likely want to use an early termination policy when working with continuous hyperparameters and a random or Bayesian sampling method.
Configure an early termination policy
There are two main parameters when you choose to use an early termination policy:
evaluation_interval: Specifies at which interval you want the policy to be evaluated. Every time the primary metric is logged for a trial counts as an interval.delay_evaluation: Specifies when to start evaluating the policy. This parameter allows for at least a minimum of trials to complete without an early termination policy affecting them.
New models may continue to perform only slightly better than previous models. To determine the extent to which a model should perform better than previous trials, there are three options for early termination:
- Bandit policy: Uses a
slack_factor(relative) orslack_amount(absolute). Any new model must perform within the slack range of the best performing model. - Median stopping policy: Uses the median of the averages of the primary metric. Any new model must perform better than the median.
- Truncation selection policy: Uses a
truncation_percentage, which is the percentage of lowest performing trials. Any new model must perform better than the lowest performing trials.
Bandit policy
You can use a bandit policy to stop a trial if the target performance metric underperforms the best trial so far by a specified margin.
For example, the following code applies a bandit policy with a delay of five trials, evaluates the policy at every interval, and allows an absolute slack amount of 0.2.
from azure.ai.ml.sweep import BanditPolicy
sweep_job.early_termination = BanditPolicy(
slack_amount = 0.2,
delay_evaluation = 5,
evaluation_interval = 1
)
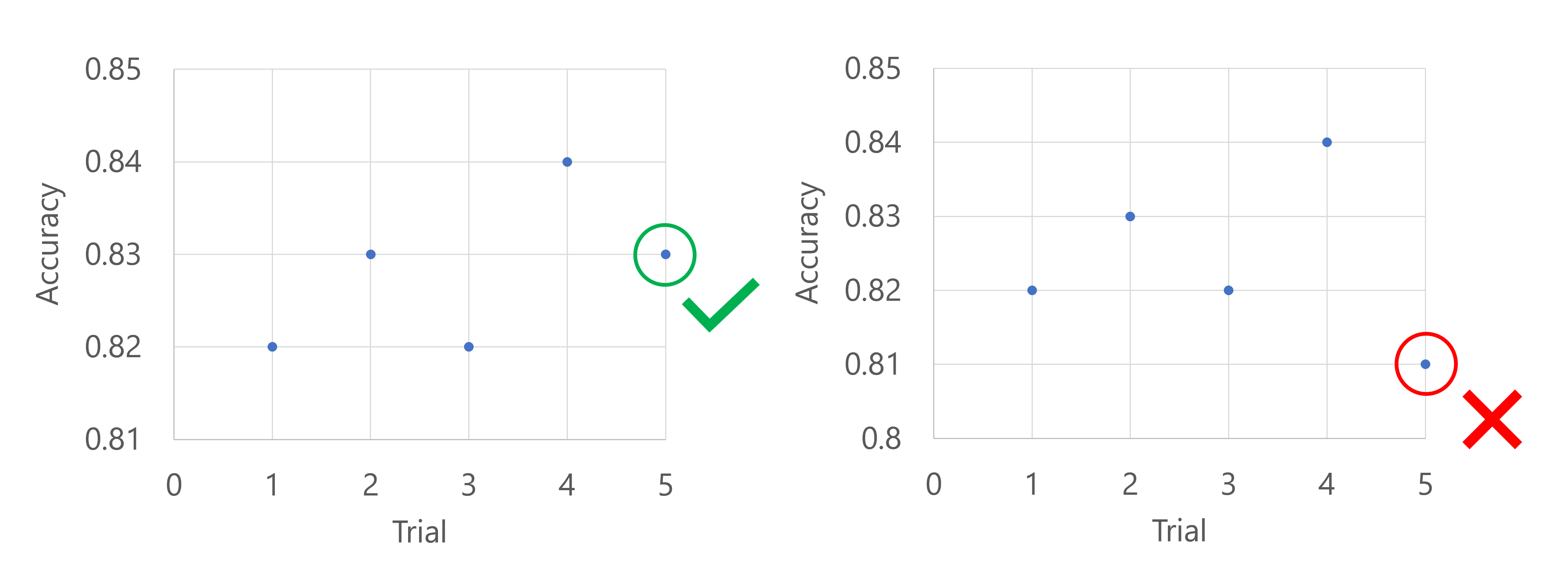
Imagine the primary metric is the accuracy of the model. When after the first five trials, the best performing model has an accuracy of 0.9, any new model needs to perform better than (0.9-0.2) or 0.7. If the new model's accuracy is higher than 0.7, the sweep job will continue. If the new model has an accuracy score lower than 0.7, the policy will terminate the sweep job.
You can also apply a bandit policy using a slack factor, which compares the performance metric as a ratio rather than an absolute value.
Median stopping policy
A median stopping policy abandons trials where the target performance metric is worse than the median of the running averages for all trials.
For example, the following code applies a median stopping policy with a delay of five trials and evaluates the policy at every interval.
from azure.ai.ml.sweep import MedianStoppingPolicy
sweep_job.early_termination = MedianStoppingPolicy(
delay_evaluation = 5,
evaluation_interval = 1
)
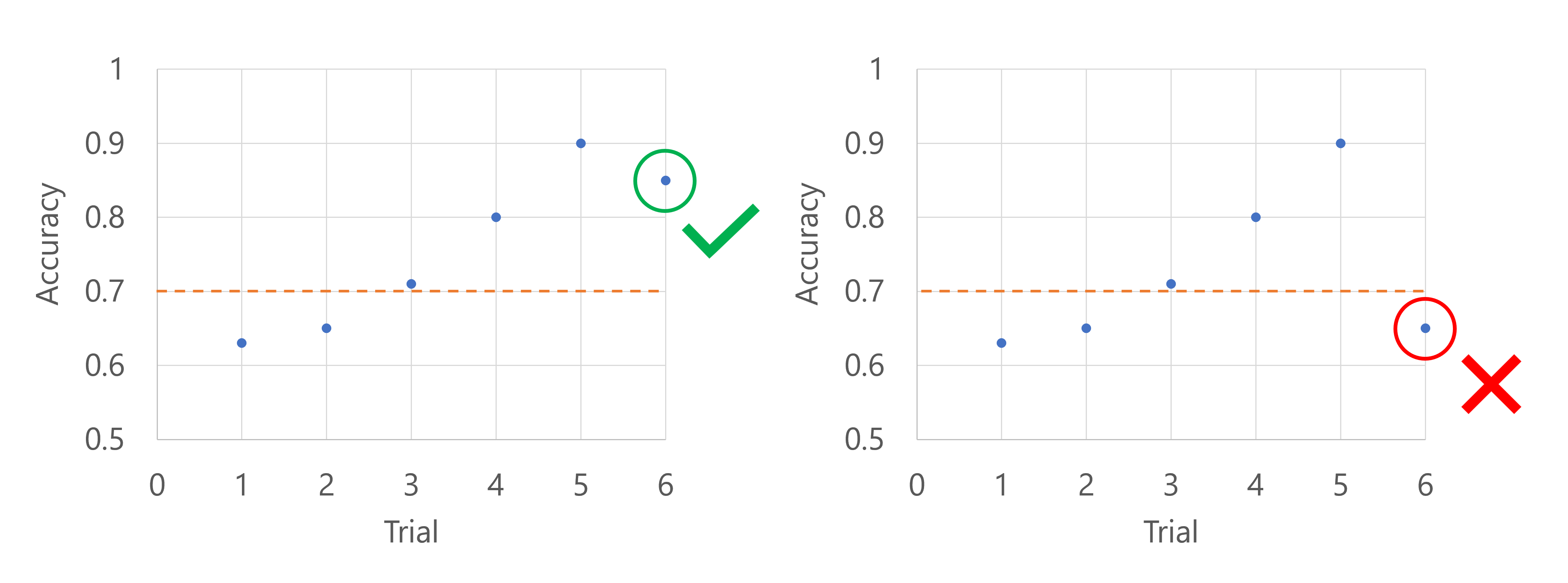
Imagine the primary metric is the accuracy of the model. When the accuracy is logged for the sixth trial, the metric needs to be higher than the median of the accuracy scores so far. Suppose the median of the accuracy scores so far is 0.82. If the new model's accuracy is higher than 0.82, the sweep job will continue. If the new model has an accuracy score lower than 0.82, the policy will stop the sweep job, and no new models will be trained.
Truncation selection policy
A truncation selection policy cancels the lowest performing X% of trials at each evaluation interval based on the truncation_percentage value you specify for X.
For example, the following code applies a truncation selection policy with a delay of four trials, evaluates the policy at every interval, and uses a truncation percentage of 20%.
from azure.ai.ml.sweep import TruncationSelectionPolicy
sweep_job.early_termination = TruncationSelectionPolicy(
evaluation_interval=1,
truncation_percentage=20,
delay_evaluation=4
)
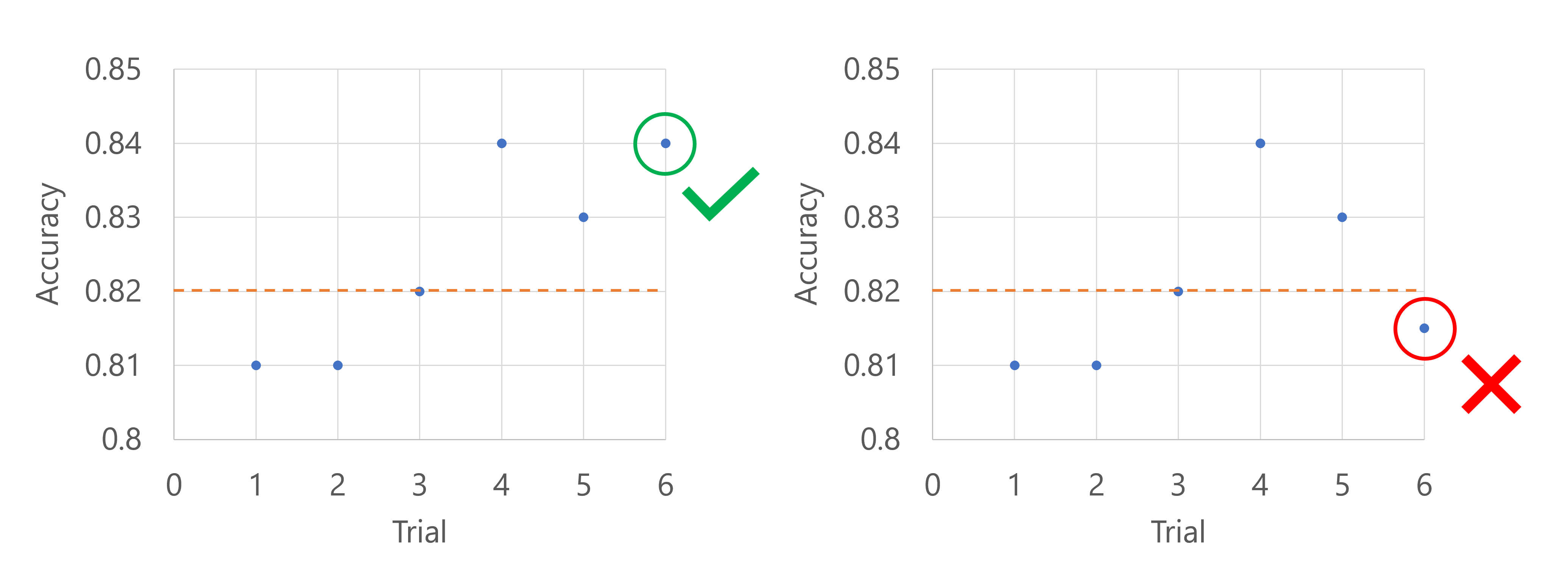
Imagine the primary metric is the accuracy of the model. When the accuracy is logged for the fifth trial, the metric should not be in the worst 20% of the trials so far. In this case, 20% translates to one trial. In other words, if the fifth trial is not the worst performing model so far, the sweep job will continue. If the fifth trial has the lowest accuracy score of all trials so far, the sweep job will stop.