Describe Azure Synapse Analytics SQL
Azure Synapse SQL enables you to implement data warehouse solutions, or to perform data virtualization.
A data warehouse is a core component of Business Intelligence (BI) solutions that provides a central repository of data stored in relational tables. It facilitates solutions around descriptive analytics. The data is retrieved, cleansed, and transformed from a range of source data system, and is then served in a structured relational format commonly referred to as a star schema.
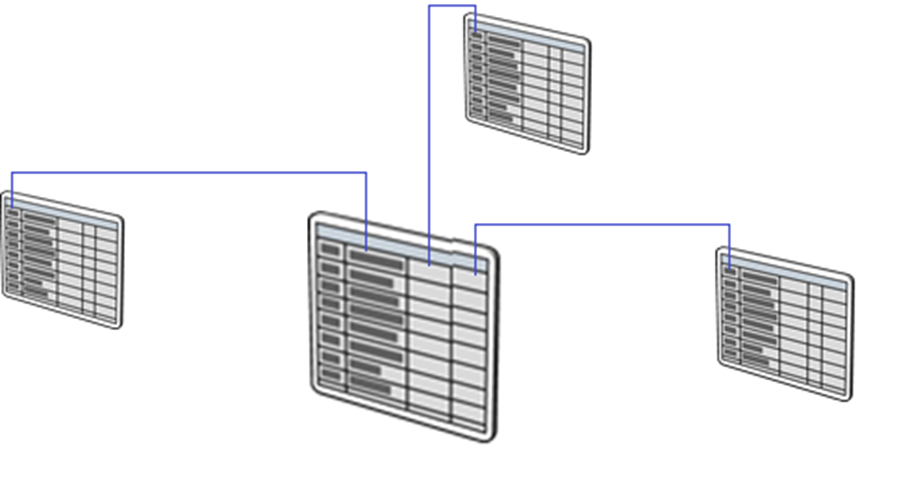
Data in a data warehouse is stored in permanent tables that are populated using an extract, transform, and load (ETL) process by services such as Azure Synapse pipelines, or Azure Data Factory. As a result, you need to understand the data that is stored in the sources systems, how it should arrive within the data warehouse, which in turn dictates how you should cleanse or transform the data.
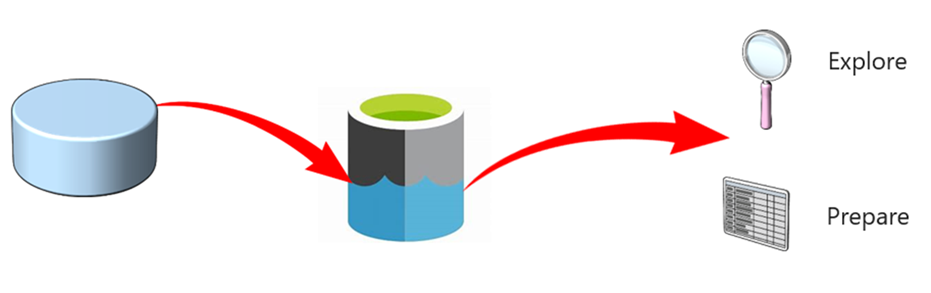
Data virtualization allows you to interact with data without the need to understand how the data is formatted, structured, or what is its data type. It enables you to explore the data without understanding the technical specifications of the source data, which can be very helpful when performing diagnostic analytics where the need to access data in a timely manner to answer a question is more important.
Data virtualization also enables ad hoc data preparation scenarios, where organizations are wanting to unlock insights from their own data stores without going through the formal processes of setting up a data warehouse. You can extract data from a source system in a raw format and load it into a data lake. From here, transformations may be applied to present the data as required. As the most complex part of the extract, load, and transform (ELT) process is at the end, it means that the access to the data is much quicker.
To meet the delivery of these types of solutions, Azure Synapse SQL offers both a dedicated and serverless model of the service to meet the different demands of both solutions.
The dedicated model is referred to as dedicated SQL Pools. It refers to the data warehousing features that are generally available in Azure Synapse Analytics. Dedicated SQL pools represent a collection of analytic resources that are being provisioned when using Synapse SQL. When you need predictable performance and cost, creating dedicated SQL pools to reserve processing power for data permanently stored in SQL tables in a data warehouse is the best approach to take.
The serverless model is ideal for unplanned or ad hoc workloads that the diagnostic analytics approach would generate. Therefore, if you are performing data exploration, are preparing data for data virtualization, then SQL serverless would be the better model to use.