How to process content with Syntex
Presumably, like Contoso Electronics, your organization already has numerous documents, and you want to know how to use Syntex to optimize the process of handling them. This unit describes how Syntex will help you with stages 2, 3, and 4 of content lifecycle: classify content, extract metadata, and apply labeling through the lens of Contoso Electronics.
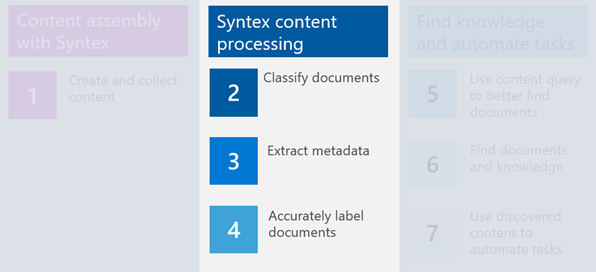
You learn:
- Types of document processing models provided by Syntex
- Features, requirements, and restrictions of each model
- A typical process of analyzing needs, setting up, and training a model
Before we start, we recommend you set up the “SharePoint Contracts management team site template” on your SharePoint site. Using this template, you can practice along with sample files, templates, libraries, and models that come with this template.
Document processing models
Content understanding in Microsoft Syntex starts with document processing models. Document processing models let you identify and classify documents that are uploaded to SharePoint document libraries, and then to extract the information you need from each file. Depending on the features and purposes of the documents, Syntex provides you with different models to process the documents. There are two categories of document processing models: prebuilt models and custom models.
Let’s look at the key facts of models in each category.
Prebuilt models
First, Syntex comes with three prebuilt models – contracts model, invoices model and receipts model, respectively, to analyze and extracts key information from contract documents, to process sales invoices, and sales receipts. These prebuilt models are preconfigured and pretrained. Instead of starting from scratch to build your model, you can start by analyzing a file against the prebuilt model and identify fields that you want to extract. Both models work on files in the following file types: .bmp, .jpeg, .pdf, .png, and .tiff.
Contract processing
Contract processing model analyzes and extracts key information from contract documents. The prebuilt contract processing model recognizes contracts in various formats and extracts key contract information, such as client name and address, contract duration, and renewal date.
Invoice processing
Invoice processing model processes invoices to extract key information. The prebuilt invoice processing model works on PDF documents and image files but supports only English language invoices from the United States.
Receipt processing
Use the receipt processing model to get important info from either printed or handwritten receipts. This prebuilt receipt processing model works on PDF documents and image files, but only supports English sales receipts from Australia, Canada, Great Britain, India, and the United States.
Using prebuilt models
To use prebuilt models, you start by creating the model. Then you upload an example file to compare against the prebuilt model. You need to tell the model which information should be extracted from the document (select extractors). After you've selected extractors, you can then save the model and apply it to the document library. The key data extracted by the extractors show up in the document library.
Custom models
More often, your documents aren't contracts, invoices and receipts. You need to create custom models to process these documents. There are three types of custom models: Structured document processing model, freeform document processing model and unstructured document processing model. Each works best with certain types of documents in terms of information structure, file format, and supported language. The costs, requirements to use each model, and the efforts to set up also vary by the model type.
Structured document processing model
A structured document processing model works best when the information in the document is stored in a table format, such as forms and invoices. This custom model works on PDF documents and image files. It supports a wide range of languages and uses the layout method to classify and extract information.
Freeform document processing model
A freeform document processing model works best on unstructured and freeform documents where the formats might be different, but similar content exists in all the documents. This custom model works on PDF documents and image files, but it currently only supports documents in English. This model uses the freeform selection method to classify and extract information.
Note
Both Structured document processing and freeform document processing models rely on Power Platform. You may want to check the Power Platform availability before deciding to use these two models. Both models require AI Builder credits. Each Microsoft Syntex licensed “seat” comes with 3,500 credits with the option to purchase more if needed.
Unstructured document processing model
If your documents have various content structures but contain similar key information, you want to consider using the unstructured document processing model. Among all three custom models, the unstructured document processing model supports the widest range of document types. This model supports the Latin-based languages, including English, French, German, Italian, and Spanish. It uses the teaching method to train the files. Unstructured document processing model is available in all regions.
The following video provides a quick overview on what is an unstructured document processing model:
All models
For all models, you need to first upload one or multiple sample files to train the model. However, different models use different training methods and support different sets of document types and languages. In addition, for some models, you need to consider that they might not work in certain regions, if Power Platform and AI Builder aren't available in the region. See more details on requirements and limitations on each document processing model.
Remember:
- Centrally created models are known as enterprise models, and locally as local models.
- You can apply enterprise models to multiple libraries, whereas you can only apply local models to a single library.
- If a model has a low confidence score, upload extra sample files, and retrain the model.
Before you start creating models
- Think about what information you need to extract.
- If you update a Syntex freeform or structured model, don't forget to publish these changes to make them live. In the model details page, select the last trained version, then select Publish.
- If you're updating a Syntex model such as adding or removing extractors, remember to sync the model to the library where it's assigned. The action to sync updates the content type and columns accordingly.
Document tagging
In addition to document processing models, Syntex gives you the ability to automatically tag documents with AI. For images, image tagging stores descriptive keywords extracted by AI in the Image Tags column, making it easier to search, sort, filter and manage images. For other supported documents, taxonomy tagging stores terms configured in your term store in the taxonomy column, making it easier to search, sort, filter and manage these documents.
Optical character recognition (OCR)
The OCR service in Syntex extracts printed or handwritten text from images and documents and then index them in search. This service helps you to quickly and accurately find the keywords and phrases that you're looking for.
Contoso Electronics optimizes document quality check with the structured document processing model
Now, let’s look at how Contoso Electronics identifies their approach to optimize their document quality check process.
Identify the scenario
Contoso Electronics, being a large company that operates in multiple countries/regions, wants to make sure all their paperwork is in line with what customers expect in each specific area. This includes looking over things like technical designs, processes, and making sure customer orders are accurate. Basically, it's all about making sure they're following the rules and everything is in order.
In the past, document processors at Contoso Electronics did quality checks manually, costing valuable time and resources. Now with Syntex, document processors hope that key information can be automatically captured from each document associated with the project making the quality checks quicker and easier.
Decide the approach
To implement Syntex for Contoso’s document quality checking, the first step is to identify which document processing model to use. The leadership asks the IT departments to work with document processors from various projects and satellite locations to make the decision. The team first analyzes the types of Contoso documents for quality checking, their formats, content structure, and languages.
The team soon discovers that documents at Contoso Electronics come in lots of formats, such as PDF documents, images, Microsoft Word documents, emails, and html pages. However, the main types of documents subjected to quality checking are PDFs and scanned images in .jpeg formats. Because Contoso Electronics is a multinational company with projects from all over the world, many documents are in either Latin alphabet languages or nonalphabet languages. Also, most of these documents have similar structures and layouts. According to the list of features at the comparison table of each custom model, the team finds that the structured document processing model is the suitable model to use.
Set up Syntex
Next, the IT department needs to confirm that Power Platform and AI Builder are available at each Contoso Electronics satellite location. After confirming that all satellite locations have Power Platform and AI Builder, the IT department starts setting up Syntex. Contoso Electronics has set up Microsoft 365 Multi-Geo environment. That means they need to contact Microsoft support because they want to use the structured document processing model in all its satellite locations. Based on the needs of document processing from each satellite location and headquarter, the team also decides on an initial number of Syntex licenses that they need to get.
The team also looks at the cost of running the model. Structured document processing uses AI Builder credits. Each Syntex license can use 3,500 credits per month with a maximum allocation of 1 million credits per month per organization. An allocation of 1 million credits allows processing of 2,000 file pages. Although unused credits don't roll over from month to month, after calculating the estimated monthly credits with the AI Builder calculator, the team decides that the default credits should be sufficient. The IT department then creates a content center, and adds document processors as other admins to the content center site.
Create and train the model
At Contoso Electronics, document processors now can create their own local structured document processing models. They train these models to analyze structured documents, such as engineering contracts, and extract key identifiers like customer names, project numbers, document numbers, status, and approvers. To ensure documents remain compliant and consistent, document processors can train the model to automatically tag documents with retention and sensitivity labels (coming later in 2023).
After training the model and using it on documents, new columns will be generated for vendor name, project number, and document number per the information that was extracted from documents. The model will also automatically label documents with retention and sensitivity labels as it is applied.
In the next unit, we'll look at how a contract manager at Contoso Electronics uses content query, rules, and other tools to find information from the generated columns. We'll also look at how to combine Syntex with other tools to automate workflow.