Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Introduction
This document presents information that will assist font developers in creating fonts for the Tibetan scripts covered by the Unicode Standard 6.0. The Tibetan script is used for writing Tibetan in several countries and regions throughout the Himalayas. It is also used to write Balti, Bumthangkha, Khengkha, and other languages. It has also been used to transliterate Sanskrit and Chinese. The Tibetan writing system was based on a North Indian form of the Brahmi script and is said to have been developed to bring Buddhism from India to Tibet. Two distinctive styles have emerged: a formal style used for books and inscriptions (called dbu can ‘with a head’) and a cursive or calligraphic style (dbu med ‘acephalous’) commonly used in hand-written contexts. Tibetan script is a parent script of Phags-pa, Limbu, and Lepcha, which have separate encodings and shaping requirements.
NOTE: Starting in Windows 10, Tibetan will be supported by the Universal Shaping Engine rather than a stand-alone shaping engine. Moving forward, developers should refer to this new specification.
An example of Tibetan in the dbu-can style:
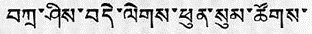
An example of Tibetan in the dbu-med style:

Font developers will learn how to encode complex script features in their fonts, choose character sets, organize font information, and use existing tools to produce Tibetan fonts. Registered features of the Tibetan script are defined and illustrated, encodings are listed, and templates are included for compiling Tibetan layout tables for OpenType fonts.
This document also presents information about the Tibetan OpenType shaping engine of Uniscribe, an operating system component responsible for text layout.
In addition to being a primer and specification for the creation and support of Tibetan fonts, this document is intended to more broadly illustrate the OpenType Layout architecture, feature schemes, and operating system support for shaping and positioning text.
Syllable structure
Tibetan script is written in units which mostly correspond to single syllables. Such units are delimited by a dot or other punctuation mark. For text-rendering purposes Tibetan script is divided into stacks, being the horizontal blocks of such syllables consisting of one or more graphical units. A minimal syllable will consist of a single stack and containing only a base consonant. This would normally be followed by the punctuation dot. For example, pa:

A complex syllable may consist of multiple stacks. For example, bsgrubs:
The topmost consonant (1) in a stack is encoded as a full letter (U+0F40–U+0F6A). All subjoined consonants (4) are encoded as subjoined letters (U+0F90–U+0FBC). In this way, what is from a collation point of view, the main consonant in a syllable may be encoded as a subjoined letter when it takes a head consonant. The encoding sequence stores stacks in logical order from left to right. Within a stack, consonants are encoded first from top to bottom; then vowels, vowel modifiers and finally marks. The encoding for the above example is:
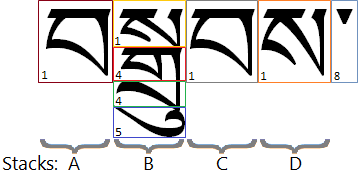
| [Stack A] | U+0F56 TIBETAN LETTER BA |
| [Stack B] | U+0F66 TIBETAN LETTER SA U+0F92 TIBETAN SUBJOINED LETTER GA U+0FB2 TIBETAN SUBJOINED LETTER RA U+0F74 TIBETAN VOWEL SIGN U |
| [Stack C] | U+0F56 TIBETAN LETTER BA |
| [Stack D] | U+0F66 TIBETAN LETTER SA |
| [End of cluster] | U+0F0B TIBETAN MARK INTERSYLLABIC TSHEG |
Terms
The following terms are useful for understanding the layout features and script rules discussed in this document.
Head glyph - (the topmost consonant in a stack) the only consonant or consonant conjunct in a stack that is written in its "full" (nominal) form. Layout operations are defined in terms of a head glyph, not a head character, since the topmost glyph can be a ligature.
Consonant - each represents a single consonant sound. The vowel carrier, Tibetan Letter A (U+0F68), and its subjoined form (U+0FB8) function as consonants. Consonants may exist in different contextual forms. When occurring as the main consonant they have the inherent vowel "a".
Conjunct Consonant – a ligature of two or more consonants.
Sub-joined consonant - a consonant in any position in the stack below a head glyph.
Tibetan syllable - the effective orthographic unit of the Tibetan writing system; composed of consonant letters, vowels, and marks. Transformations discussed in this document do not cross syllable boundaries.
Vowels - used to represent a vowel sound that is not inherent to the consonant. In the Tibetan script there are four basic vowel marks as well as several compound vowels for use in Sanskrit transliteration. Vowel marks are non-spacing and are used above or below a standalone consonant or a stack of consonants. Some of the compound vowels have components that go both above and below the stack. Normally a syllable will only have one vowel sign, but there are special cases when multiple vowel signs are used.
Stack – a single horizontal segment of a Tibetan syllable consisting of one or more sub-components arranged in a vertical column.
Shaping Engine
The Tibetan shaping engine of Uniscribe processes text in stages. The stages are:
- Analyzing the text sequence.
- Map characters to default glyphs.
- Reordering characters.
- Shape glyph sequences with OTLS (OpenType Layout Services; i.e., apply GSUB features).
- Positioning glyphs with OTLS (i.e., apply GPOS features).
The descriptions which follow will help font developers understand the rationale for the Tibetan feature encoding model, and help application developers better understand how layout clients can divide responsibilities with operating system functions.
Analyzing the text
The unit that the shaping engine receives for the purpose of shaping is a string of Unicode characters, in a sequence. These are not necessarily positioned within the sequence as they appear when composed into a syllable for display. The head consonant of the stack is identified. All other elements are classified by their relative positions.
Character classifications
Cluster analysis and shaping are based on the following character classifications:
| Class | Sub-class | Members | Comment |
|---|---|---|---|
| Letters (L) | Head letters (Lh) | 0F40–0F6C, 0F88–0F8C | |
| Subjoined letters (Ls) | 0F8D–0F8F, 0F90–0FBC | ||
| Vowel marks (V) | Above-base (Va) | 0F72, 0F7A–D, 0F80 | |
| Below-base (Vb) | 0F71, 0F74, | ||
| Compound vowels (Vc) | 0F73, 0F75–0F79, 0F81 | Use of these characters is discouraged in favor of their decomposed equivalents. | |
| Tibetan Digits (D) | 0F20–0F33 | ||
| Modifiers (M) | Letter modifiers (Ml) | 0F35, 0F37, 0F39, 0F7E–0F7F, 0F82–0F84, 0F86–0F87, 0FC6 | |
| Digit modifiers (Md) | 0F18–0F19, 0F3E–0F3F | ||
| Syllable delimiter (SD) | 0F0B–0F0C, 0F34, 0FD2 | ||
| Brackets | 0F3C–0F3D | ||
| Generic base character (GB) | 00A0, 00D7, 2012, 2013, 2014, 2022, 25CC, and 25FB–25FE | ||
| ZWJ/ZWNJ (ZJ) | 200C, 200D | ||
| Tibetan Other (O) | 0F00–0F0A, 0F0D–0F17, 0F1A–0F1F, 0F36, 0F38, 0F3A–0F3B, 0FBE–0FC5, 0FC7–0FD1, 0FD3–0FDA | All other chars from the Tibetan block |
Schemas and rules for cluster analysis and syllable analysis use the following additional symbols:
| X* | sequence of zero or more occurrences of X |
| X+ | sequence of one or more occurrences of X |
| < X |Y > | disjunction of elements: X or Y |
| [X] | optional (zero or one) occurrence of X |
| ¬ X | not X (any character not in class defined by X) |
| # | occurrence of a boundary |
| × | no boundary allowed at indicated position |
| ÷ | boundary allowed at indicated position |
Cluster analysis
Cluster analysis is performed on a Tibetan text run to identify valid cluster sequences, which are used to identify valid caret positions. Tibetan clusters are written as vertical stacks. Caret stops exist between stacks, not within them even though a stack may consist of many elements.
A single Tibetan stack is defined as follows:
Letters: Lh [Ls*] <[Va*] | [Vb] | [Vc] > [Ml]
Digits: D [Md]
An invalid cluster results when a combining sign occurs without a base. In such cases the dotted circle glyph (U+25CC) is inserted as a placeholder. A set of generic base characters is be defined so that combining marks may be shown independently from a Tibetan letter or digit. Lookups for these bases need to be defined so that they may combine with either letter marks or digit marks.
Other signs from the Tibetan block do not form clusters, but occur singly as spacing glyphs. They require no special shaping but may be operated on by the locl and ccmp features.
Word analysis
In Tibetan text syllables are written in units delimited by marks called tsheg (U+0F0B). Transliteration of Sanskrit and other foreign words may be written in units longer than one syllable without tsheg. Words comprising more than one syllable may use the non-breaking tsheg (U+0F0C). There are two other forms of tseg having special functions (U+0F34, U+oFD2). Syllable boundaries occur after any tsheg or non-word-forming character (character ∉ L). A syllable boundary is also a word boundary, except in case that the tsheg or other character non-breaking:
- U+00A0 NO-BREAK SPACE
- U+0F0C TIBETAN MARK DELIMITER TSHEG BSTAR
- U+202F NARROW NO-BREAK SPACE
- U+2060 WORD JOINER
- U+FEFF ZERO WIDTH NO-BREAK SPACE
Line Breaks
Line breaks within Tibetan text are determined by tsheg characters. Line breaks should come after a tsheg and are not permitted after letters or after a non-breaking tsheg. Thus, line break opportunities essentially correspond to word-stop positions. Generalizing, Unicode line-breaking properties apply to all characters, and the rules specified in the Unicode line breaking algorithm [UAX14] apply.
Justification
For Tibetan, justification opportunities occur primarily when there is white space within in a line of text. Text without spaces may be justified by adding space after tsheg glyphs. An alternative method for justification that has been used traditionally in Tibetan books and continues in some modern publications is to pad the end of a line with extra tsheg characters to take up the white space.
Reordering characters
Uniscribe creates and manages a buffer of appropriately reordered character codes, delineated as "clusters." Uniscribe reorders character codes within clusters according to several rules (described below). Then, Uniscribe obtains the corresponding glyph string by passing the reordered character string to the glyph substitution function of the OTLS.
Because glyph strings are obtained from reordered character strings, the features in a Tibetan font must be encoded to map reordered characters (and combinations of characters) to their corresponding glyphs.
There are specific rules when determining stacking order in the Tibetan language. In languages other than Tibetan, these rules do not always apply, therefore the shaping engine allows for any consonants to be stacked with any sub-joined consonants.
The correct coding order for a stream of text is as follows:
- head position consonant
- first sub-joined consonant
- ....intermediate sub-joined consonants (if any)
- last sub-joined consonant
- sub-joined vowel (a-chung U+0F71)
- standard or compound vowel sign (including virama U+0F84 in the case of Sanskrit transliteration)
- additional vowel signs (if any)
- vowel modifier signs (rjes su nga ro U+0F7E, rnam bcad U+0F7F)
Shaping with OTLS
The first step Uniscribe takes in shaping the character string is to map all characters to their nominal form glyphs. Then, Uniscribe applies contextual shape features to the glyph string.
Next, Uniscribe calls the OTLS to shape the Tibetan stack. All OTL processing is divided into a set of predefined features (described and illustrated in the Feature section of this document). Each feature is applied, one by one, to the appropriate glyphs in the stack and OTLS processes them. Uniscribe makes as many calls to OTLS as there are features. This ensures that the features are executed in the desired order.
The steps of the shaping process are outlined below.
Shaping features:
- Language forms
- Apply feature ‘locl’ to select language-specific forms.
- Apply feature 'ccmp' to preprocess any glyphs that require composition or decomposition.
- Conjuncts and Typographical forms
- Apply feature 'abvs' to do any above-base substitutions required.
- Apply feature 'blws' to do any below-base substitutions required.
- Apply feature ‘calt’ to invoke any contextual alternates.
- Apply feature ‘liga’ to invoke any standard ligatures.
Positioning Glyphs with OTLS
Uniscribe next applies features concerned with positioning, calling functions of OTLS to position glyphs.
Positioning features:
- Typographical positioning
- Apply feature ‘kern’ to adjust horizontal spacing of items.
- Apply feature 'abvm' to position above-base marks.
- Apply feature 'blwm' to position below-base marks.
- Apply feature ‘mkmk’ to position following marks relative to preceding marks.
Features
The features listed below have been defined to create the basic forms for the scripts and languages that are supported on Tibetan systems. Regardless of the model an application chooses for supporting layout of complex scripts, Uniscribe requires a fixed order for executing features within a run of text to consistently obtain the proper basic form. This is achieved by calling features one-by-one in the standard order listed below.
The order of the lookups within each feature is also very important. For more information on lookups and defining features in OpenType fonts, see Encoding feature information in the OpenType font development section.
The standard order for applying Tibetan features encoded in OpenType fonts:
| Feature | Feature function | Layout operation | Required |
|---|---|---|---|
| Language based forms: | |||
| ccmp | Character composition/decomposition substitution | GSUB | |
| Conjuncts & typographical forms: | |||
| abvs | Above-base substitution | GSUB | X |
| blws | Below-base substitution | GSUB | X |
| calt | Contextual alternates | GSUB | |
| liga | Standard ligatures | GSUB | |
| Positioning features: | |||
| kern | Kerning | GPOS | |
| abvm | Above-base mark positioning | GPOS | X |
| blwm | Below-base mark positioning | GPOS | X |
| mkmk | Mark to mark positioning | GPOS | |
| [GSUB = glyph substitution, GPOS = glyph positioning] | |||
Descriptions and examples of above features
Character composition (and decomposition)
Feature Tag: "ccmp"
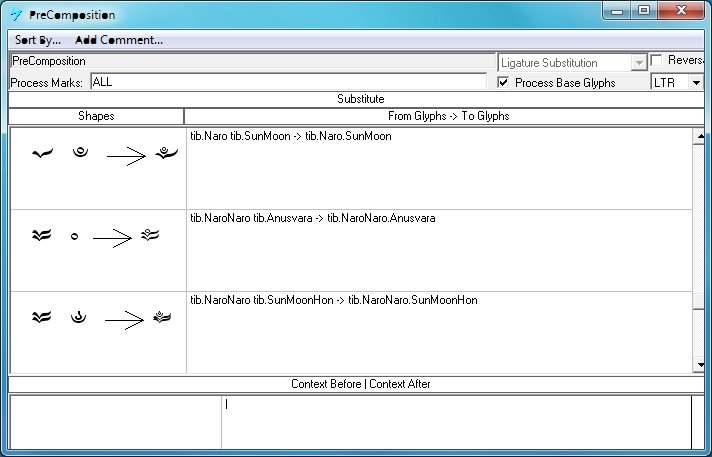
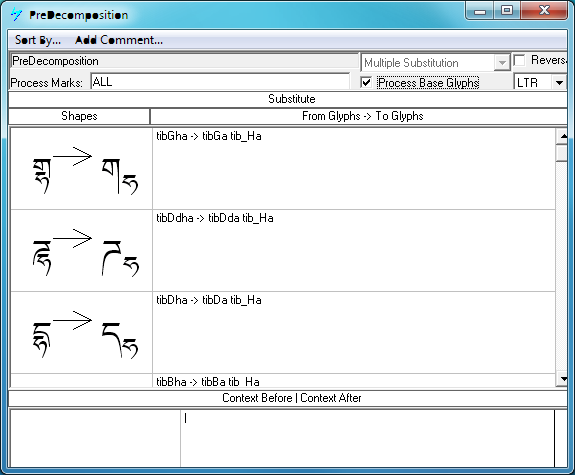
The 'ccmp' feature is used to compose multiple glyphs into one glyph, or decompose one glyph into multiple glyphs. This feature is implemented before any other features because there may be times when a font vender wants to control certain shaping actions. An example of using this table is seen below. The 'ccmp' table maps default alphabetic forms to both a composed form (essentially a ligature, GSUB lookup type 4), and decomposed forms (GSUB lookup type 2).
The 'ccmp' feature applied:
Composing multiple glyphs into a single glyph:
Decomposing a single glyph into multiple glyphs:
Conjuncts and typographical forms
Feature Tag: "abvs", "blws";
All previous features have dealt with language features only, dedicated to forming glyph shapes dictated by the languages. The remaining shaping features cover optional features.
These optional features range from those that will exist in every font to rare typographical ornaments. It is important to stress that all features operate only within one orthographic syllable.
Since the language features do not limit typographical processing, Uniscribe passes the entire syllable to OTLS. Uniscribe does not strictly specify the format of lookup tables to use or their inputs, allowing for context-dependent processing of any of the conjuncts and forms below.
OTLS processes the syllable "left to right", executing lookups in the order that they are specified in the font. First, above-base substitutions will be handled, then below-base substitutions.
Therefore a font developer should first take care of all ligatures to the left of the head glyph and then working to the right, substitute above-base, then below-base elements. The lookups in the font should be ordered in the same way.
With every new element and feature, the following operations should be considered, as appropriate, in this order:
- Ligatures with the head glyph
- Ligatures with preceding subjoined elements, and
- Contextual forms of the element
At every feature step, one should take into account all results that may be produced by previous steps.
Above-base substitutions
Feature Tag: "abvs"
Above-base substitutions are
This feature substitutes one or more mark glyphs in the context of certain head glyphs. (GSUB lookup type 4)
The 'abvs' feature applied:
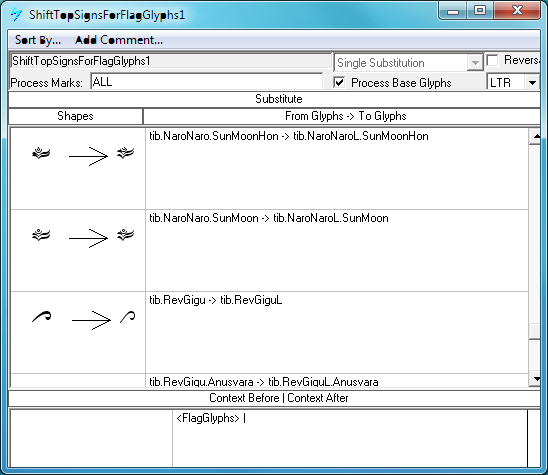
For example, TIBETAN LETTER TSA (U+0F59) belongs to a class of letters that have a flag which extends above the top line <FlagGlyphs>. Without adjustment, the VOWEL SIGN I (U+0F72) would overlap with this flag. Therefore the vowel sign glyph is substituted for a narrower version by the ShiftTopSignsForFlagGlyphs1 lookup that is triggered by the 'abvs' feature.
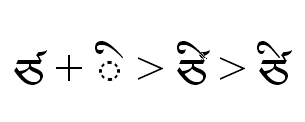
Below-base substitutions
Feature Tag: "blws"
This feature substitutes a ligature for a base glyph and a below base form. (GSUB lookup type 4)
The 'blws' feature applied:
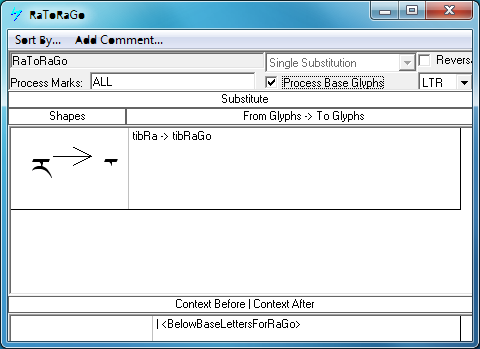
For example, TIBETAN LETTER RA (U+0F62) takes a special reduced form when it is the topmost member in a stack of consonants. To accomplish this, the full form (tibRa) is substituted for the reduced form (tibRaGo) when it precedes one of the base letters which invoke this form, which may be referred to as a group <BelowBaseLettersForRaGo>.
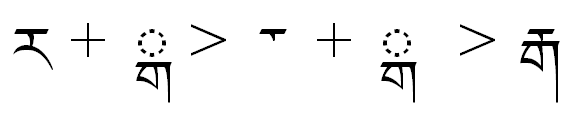
Above-base marks
Feature Tag: "abvm"
This feature positions all above-base marks on the base glyph.
"Above-base marks" feature applied:
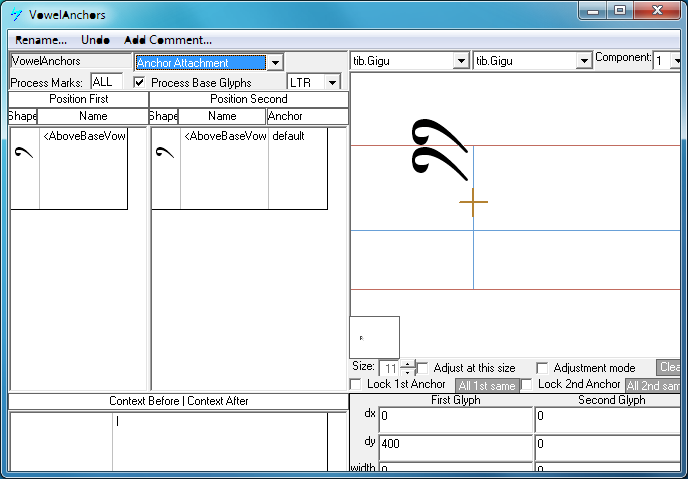
This feature is needed for special cases in which more than one above-base vowel mark is applied to a single stack. Such forms typically occur as abbreviations in the dbu-med form of the script but should also be supported in dbu-can fonts. For example:
In dbu-med style  corresponds to
corresponds to  in dbu-can, and is an abbreviation for Rinpoche
in dbu-can, and is an abbreviation for Rinpoche  . The VowelAnchors feature positions any above-base vowel on top of any other above-base vowel. A sequence of such vowels can be positioned using this feature. This feature could equally be applied with the Mark to Mark Positioning feature 'mkmk'.
. The VowelAnchors feature positions any above-base vowel on top of any other above-base vowel. A sequence of such vowels can be positioned using this feature. This feature could equally be applied with the Mark to Mark Positioning feature 'mkmk'.
Below-base marks
Feature Tag: "blwm"
This feature positions all below-base marks on the base glyph.
"Below-base marks" feature applied:
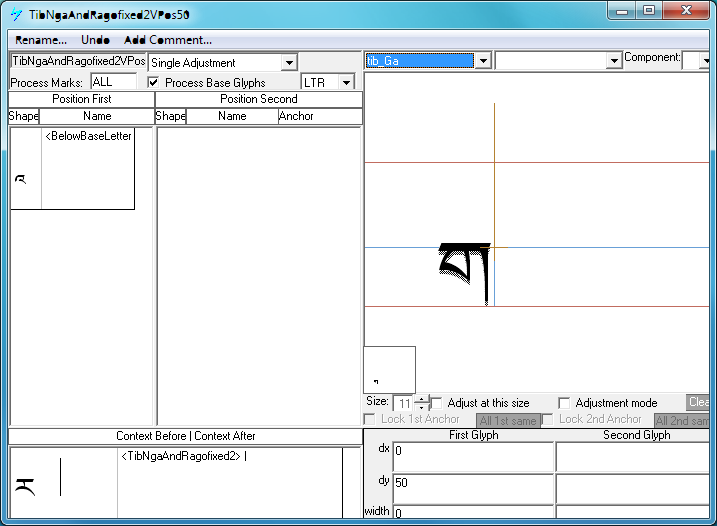
For example, when TIBETAN LETTER NGA (U+0FFF) combines with a subjoined letter, the position of the subjoined letters needs to be raised very slightly so that it touches the base of NGA.
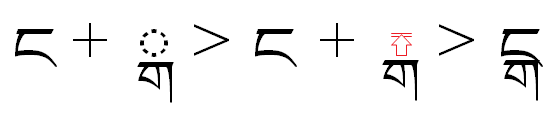
Interaction between below-base, post-base and above-base elements
Commonly, a feature is required for dealing with the base glyph and one of the post-base, pre-base or above-base elements. Since it is not possible to reorder ALL of these elements next to the base glyph, we need to skip over the elements "in the middle" (reordering-wise).
The solution is to assign different mark attachment classes to different elements of the syllable and positional forms, and in any given lookup work with one mark type only. For example, in above-base substitutions we need only consider above-base elements most of the time.
Generally, it is good practice to label as "mark" glyphs that are denoted as marks in the Unicode Standard as well as below-base/above-base forms of consonants. Then, different attachment classes should be assigned to different marks depending on their position with respect to the base.
Handling invalid combining marks
Combining marks and signs that appear in text not in conjunction with a valid consonant base are considered invalid. Uniscribe displays these marks using the fallback rendering mechanism defined in the Unicode Standard (section 5.12, 'Rendering Non-Spacing Marks' of the Unicode Standard 3.1), i.e., positioned on a dotted circle.
Please note that to render a sign standalone (in apparent isolation from any base) one should apply it on a space (see section 2.5 'Combining Marks' of the Unicode Standard). Uniscribe requires a ZWJ to be placed between the space and a mark for them to combine into a standalone sign. (i.e., to get a shape of I-matra without the dotted circle one should type + ZWJ + I-matra).
For the fallback mechanism to work properly, a Tibetan OTL font should contain a glyph for the dotted circle (U+25CC). In case this glyph is missing from the font, the invalid signs will be displayed on the missing glyph shape (white box).
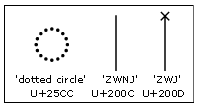
In addition to the 'dotted circle' other Unicode code points that are recommended for inclusion in any Tibetan font are the ZWJ (zero width joiner; U+200C), the ZWNJ (zero width non-joiner; U+200D) and the ZWSP (zero width space; U+200B).
Examples of Tibetan
The following examples show how Tibetan runs are formed using OpenType features.
|
A sequence of Tibetan code points is entered: |
 |
|
Before shaping, below-base signs overlap: |
 |
|
The blws lookup LeadingGlyphsFollowedByThreeMarks replaces the topmost letter in the stack with a shortened form in the context of a stack consisting of three or more below-base marks. |
 |
|
The blws lookup MarksToOneFourthLower replaces the below base marks with shortened forms in the context of the shortened top letter. |
 |
|
The blws lookup StackLigatures replaces the entire stack with a single ligature glyph. |
 |
|
A sequence is entered for a Tibetan abbreviation: |
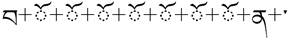 |
|
Before shaping, above-base vowel marks overlap: |
 |
|
The ccmp lookup DrengboAndNaroPreComposition substitutes sequences of two identical above-base vowels with a corresponding ligature. Note that the odd-number of vowels leaves one single vowel after the substitution. |
 |
|
The abvm lookup VowelAnchors stacks the sequence of vowels one on top of another. |
 |
Appendix
Appendix: Writing system and language tags
Features are encoded according to both a designated script and language system. Currently, the Uniscribe engine only supports the "default" language for each script. However, font developers may want to build language specific features which are supported in other applications and will be supported in future Microsoft OpenType implementations.
- NOTE: It is strongly recommended to include the "dflt" language tag in all OpenType fonts because it defines the basic script handling for a font. The "dflt" language system is used as the default if no other language specific features are defined or if the application does not support that particular language. If the "dflt" tag is not present for the script being used, the font may not work in some applications.
The following tables list the registered tag names for scripts and language systems.
| Registered tags for the Tibetan script | Registered tags for Tibetan language systems | ||
|---|---|---|---|
| Script tag | Script | Language system tag | Language |
|
"tibt" |
Tibetan |
"dflt" |
*default script handling |
|
"TIB " |
Tibetan |
||
|
"SAN " |
Sanskrit |
||
|
"TSJ " |
Tshangla |
||
|
"XKF " |
Khengkha |
||
|
"KJZ " |
Bumthangkha |
||
|
"BLT " |
Balti |
||
|
"DZN" |
Bhutanese |
||
Note: both the script and language tags are case sensitive (script tags should be lowercase, language tags are all caps) and must contain four characters (ie. you must add a space to the three character language tags).
Collaborate with us on GitHub
The source for this content can be found on GitHub, where you can also create and review issues and pull requests. For more information, see our contributor guide.
Script development specifications