Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Note
This article refers primarily to consumer experiences delivered in Windows 10 (version 1909 and earlier). For more information, see End of support for Cortana.
Cortana, the Windows speech platform, powers all speech experiences in Windows 10, such as Cortana and dictation. Voice activation is a feature that enables users to invoke a speech recognition engine from various device power states by saying a specific phrase—"Hey Cortana." To create hardware that supports voice activation technology, review the information in this article.
Note
Implementing voice activation is a significant project and is a task completed by SoC vendors. OEMs can contact their SoC vendor for information on their SoC's implementation of voice activation.
Cortana End User Experience
To understand the voice interaction experience available in Windows, review these articles.
| Article | Description |
|---|---|
| What is Cortana? | Provides and overview and usage direction for Cortana |
Introduction to "Hey Cortana" Voice Activation and "Learn my voice"
Hey Cortana" Voice Activation
The "Hey Cortana" Voice Activation (VA) feature allows users to quickly engage the Cortana experience outside of their active context (that is, what is currently on screen) by using their voice. Users often want to be able to instantly access an experience without having to physically interact or touch a device. Phone users might be driving in the car and having their attention and hands engaged with operating the vehicle. An Xbox user might not want to find and connect a controller. PC users might want rapid access to an experience without having to perform multiple mouse, touch, or keyboard actions. For example, a computer in the kitchen being used while cooking.
Voice activation provides always listening speech input via predefined key phrases or activation phrases. Key phrases can be uttered by themselves ("Hey Cortana") as a staged command, or followed by a speech action, for example, "Hey Cortana, where is my next meeting?", a chained command.
The term Keyword Detection describes the detection of the keyword by either hardware or software.
Keyword only activation occurs when only the Cortana keyword is said, Cortana starts and plays the EarCon sound to indicate that it has entered listening mode.
A chained command describes the ability of issuing a command immediately following the keyword (like "Hey Cortana, call John") and have Cortana start (if not already started) and follow the command (starting a phone call with John).
This diagram illustrates chained and keyword only activation.
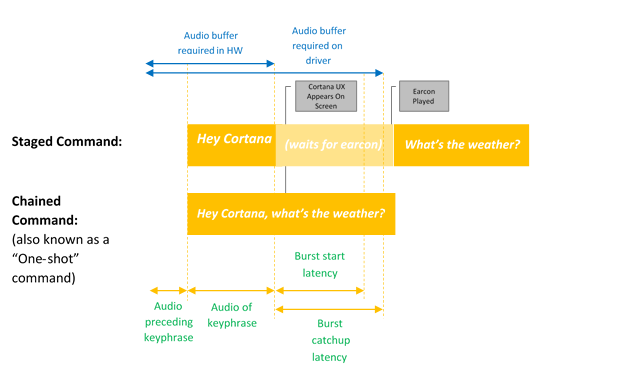
Microsoft provides an OS default keyword spotter (software keyword spotter) that is used to ensure quality of hardware keyword detections and to provide the Hey Cortana experience in cases where hardware keyword detection is absent or unavailable.
The "Learn my voice" feature
The "Learn my voice" feature allows the user to train Cortana to recognize their unique voice. This is accomplished by the user selecting Learn how I say "Hey Cortana" in the Cortana settings screen. The user then repeats six carefully chosen phrases that provide a sufficient variety of phonetic patterns to identify the unique attributes of the user's voice.
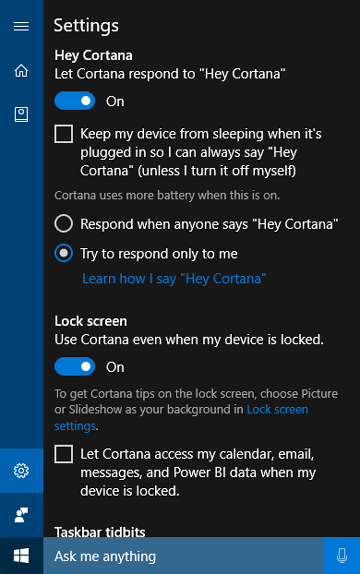
When voice activation is paired with "Learn my voice," the two algorithms work together to reduce false activations. This is especially valuable for the meeting room scenario, where one person says "Hey Cortana" in a room full of devices. This feature is available only for Windows 10 version 1903 and earlier.
Voice activation is powered by a keyword spotter (KWS) which reacts if the key phrase is detected. If the KWS is to wake the device from a low powered state, the solution is known as Wake on Voice (WoV). For more information, see Wake on Voice.
Glossary of Terms
This glossary summarizes terms related to voice activation.
| Term | Example/definition |
|---|---|
| Staged Command | Example: Hey Cortana <pause, wait for EarCon sound> What's the weather? This is sometimes referred to as "Two-shot command" or "Keyword-only" |
| Chained Command | Example: Hey Cortana what's the weather? This is sometimes referred to as a "One-shot command" |
| Voice Activation | The scenario of providing keyword detection of a predefined activation key phrase. For example, "Hey Cortana" is the Microsoft Voice Activation scenario. |
| WoV | Wake-on-Voice – Technology that enables Voice Activation from a screen off, lower power state, to a screen on full power state. |
| WoV from Modern Standby | Wake-on-Voice from a Modern Standby (S0ix) screen off state to a screen on full power (S0) state. |
| Modern Standby | Windows Low Power Idle infrastructure - successor to Connected Standby (CS) in Windows 10. The first state of modern standby is when the screen is off. The deepest sleep state is when in DRIPS/Resiliency. For more information, see Modern Standby |
| KWS | Keyword spotter – the algorithm that provides the detection of "Hey Cortana" |
| SW KWS | Software keyword spotter – an implementation of KWS that runs on the host (CPU). For "Hey Cortana," SW KWS is included as part of Windows. |
| HW KWS | Hardware-offloaded keyword spotter – an implementation of KWS that runs offloaded on hardware. |
| Burst Buffer | A circular buffer used to store PCM data that can 'burst up' on a KWS detection, so that all audio that triggered a KWS detection is included. |
| Keyword Detector OEM Adapter | A driver-level shim that enables the WoV-enabled HW to communicate with Windows and the Cortana stack. |
| Model | The acoustic model data file used by the KWS algorithm. The data file is static. Models are localized, one per locale. |
Integrating a Hardware Keyword Spotter
To implement a hardware keyword spotter (HW KWS), complete the following tasks.
- Create a custom keyword detector based on the SYSVAD sample described later in this article. You'll implement these methods in a COM DLL, described in Keyword Detector OEM Adapter Interface.
- Implement WAVE RT enhancements described in WAVERT Enhancements.
- Provide INF file entries to describe any custom APOs used for keyword detection.
- PKEY_FX_KeywordDetector_StreamEffectClsid
- PKEY_FX_KeywordDetector_ModeEffectClsid
- PKEY_FX_KeywordDetector_EndpointEffectClsid
- PKEY_SFX_KeywordDetector_ProcessingModes_Supported_For_Streaming
- PKEY_MFX_KeywordDetector_ProcessingModes_Supported_For_Streaming
- PKEY_EFX_KeywordDetector_ProcessingModes_Supported_For_Streaming
- Review the hardware recommendations and test guidance in Audio Device Recommendation. This article provides guidance and recommendations for the design and development of audio input devices intended for use with Microsoft's Speech Platform.
- Support both staged and chained commands.
- Support "Hey Cortana" for each of the supported Cortana locales.
- The APOs (Audio Processing Objects) must provide the following effects:
- AEC
- AGC
- NS
- Effects for Speech processing mode must be reported by the MFX APO.
- The APO can perform format conversion as MFX.
- The APO must output the following format:
- 16 kHz, mono, FLOAT.
- Optionally design any custom APOs to enhance the audio capture process. For more information, see Windows Audio Processing Objects.
Hardware-offloaded keyword spotter (HW KWS) WoV Requirements
- HW KWS WoV is supported during S0 Working state and S0 sleep state also known as Modern Standby.
- HW KWS WoV isn't supported from S3.
AEC Requirements for HW KWS
For Windows Version 1709
- To support HW KWS WoV for S0 sleep state (Modern Standby) AEC isn't required.
- HW KWS WoV for S0 working state isn't supported in Windows Version 1709.
For Windows Version 1803
- HW KWS WoV for S0 working state is supported.
- To enable HW KWS WoV for S0 working state, the APO must support AEC.
Sample Code Overview
There's sample code for an audio driver that implements voice activation on GitHub as part of the SYSVAD virtual audio adapter sample. It's recommended to use this code as a starting point. The code is available at this location.
https://github.com/Microsoft/Windows-driver-samples/tree/main/audio/sysvad/
For more information about the SYSVAD sample audio driver, see Sample Audio Drivers.
Keyword Recognition System Information
Voice Activation Audio Stack Support
The audio stack external interfaces for enabling Voice Activation serves as the communication pipeline for the speech platform and the audio drivers. The external interfaces are divided into three parts.
- Keyword detector Device Driver Interface (DDI). The Keyword detector Device Driver Interface is responsible for configuring and arming the HW Keyword Spotter (KWS). It's also used by the driver to notify the system of a detection event.
- Keyword Detector OEM Adapter DLL. This DLL implements a COM interface to adapt the driver specific opaque data for use by the OS to assist with keyword detection.
- WaveRT streaming enhancements. The enhancements enable the audio driver to burst stream the buffered audio data from the keyword detection.
Audio Endpoint Properties
Audio endpoint graph building occurs normally. The graph is prepared to handle faster than real time capture. Timestamps on captured buffers remain true. Specifically, the timestamps correctly reflect data that was captured in the past and buffered, and is now bursting.
Theory of Bluetooth bypass audio streaming
The driver exposes a KS filter for its capture device as usual. This filter supports several KS properties and a KS event to configure, enable, and signal a detection event. The filter also includes another pin factory identified as a keyword spotter (KWS) pin. This pin is used to stream audio from the keyword spotter.
The properties are:
- Supported keyword types - KSPROPERTY_SOUNDDETECTOR_PATTERNS. The operating system sets this property to configure the keywords to be detected.
- List of keyword patterns GUIDs - KSPROPERTY_SOUNDDETECTOR_SUPPORTEDPATTERNS. This property is used to get a list of GUIDs that identify the types of supported patterns.
- Armed - KSPROPERTY_SOUNDDETECTOR_ARMED. This read/write property is a boolean status indicating whether the detector is armed. The OS sets this to engage the keyword detector. The OS can clear this to disengage. The driver automatically clears this when keyword patterns are set and also after a keyword is detected. (The OS must rearm.)
- Match result - KSPROPERTY_SOUNDDETECTOR_MATCHRESULT. This read property holds the result data after detection has occurred.
The event that is fired when a keyword is detected is a KSEVENT_SOUNDDETECTOR_MATCHDETECTED event.
Sequence of Operation
System Startup
- The OS reads the supported keyword types to verify it has keywords in that format.
- The OS registers for the detector status change event.
- The OS sets the keyword patterns.
- The OS arms the detector.
On Receiving the KS Event
- The driver disarms the detector.
- The OS reads the keyword detector status, parses the returned data, and determines which pattern was detected.
- The OS rearms the detector.
Internal Driver and Hardware Operation
While the detector is armed, the hardware can be continuously capturing and buffering audio data in a small FIFO buffer. (The size of this FIFO buffer is determined by requirements outside of this document, but might typically be hundreds of milliseconds to several seconds.) The detection algorithm operates on the data streaming through this buffer. The design of the driver and hardware are such that while armed there's no interaction between the driver and hardware and no interrupts to the "application" processors until a keyword is detected. This allows the system to reach a lower power state if there's no other activity.
When the hardware detects a keyword, it generates an interrupt. While waiting for the driver to service the interrupt, the hardware continues to capture audio into the buffer, ensuring no data after the keyword is lost, within buffering limits.
Keyword Timestamps
After detecting a keyword, all voice activation solutions must buffer all of the spoken keyword, including 250ms before the start of the keyword. The audio driver must provide timestamps identifying the start and end of the key phrase in the stream.
In order to support the keyword start/end timestamps, DSP software may need to internally timestamp events based on a DSP clock. Once a keyword is detected, the DSP software interacts with the driver to prepare a KS event. The driver and DSP software need to map the DSP timestamps to a Windows performance counter value. The method of doing this is specific to the hardware design. One possible solution is for the driver to read current performance counter, query the current DSP timestamp, read current performance counter again, and then estimate a correlation between performance counter and DSP time. Then given the correlation, the driver can map the keyword DSP timestamps to Windows performance counter timestamps.
Keyword Detector OEM Adapter Interface
The OEM supplies a COM object implementation that acts as an intermediary between the OS and the driver, helping to compute or parse the opaque data that is written and read to the audio driver through KSPROPERTY_SOUNDDETECTOR_PATTERNS and KSPROPERTY_SOUNDDETECTOR_MATCHRESULT.
The CLSID of the COM object is a detector pattern type GUID returned by the KSPROPERTY_SOUNDDETECTOR_SUPPORTEDPATTERNS. The OS calls CoCreateInstance passing the pattern type GUID to instantiate the appropriate COM object that's compatible with keyword pattern type and calls methods on the object's IKeywordDetectorOemAdapter interface.
COM Threading Model requirements
The OEM's implementation may choose any of the COM threading models.
IKeywordDetectorOemAdapter
The interface design attempts to keep the object implementation stateless. In other words, the implementation should require no state to be stored between method calls. In fact, internal C++ classes likely don't need any member variables beyond those required to implement a COM object in general.
Methods
Implement the following methods.
- IKeywordDetectorOemAdapter::BuildArmingPatternData
- IKeywordDetectorOemAdapter::ComputeAndAddUserModelData
- IKeywordDetectorOemAdapter::GetCapabilities
- IKeywordDetectorOemAdapter::ParseDetectionResultData
- IKeywordDetectorOemAdapter::VerifyUserKeyword
KEYWORDID
The KEYWORDID enumeration identifies the phrase text/function of a keyword and is also used in the Windows Biometric Service adapters. For more information, see Biometric Framework Overview - Core Platform Components
typedef enum {
KwInvalid = 0,
KwHeyCortana = 1,
KwSelect = 2
} KEYWORDID;
KEYWORDSELECTOR
The KEYWORDSELECTOR struct is a set of IDs that uniquely select a particular keyword and language.
typedef struct
{
KEYWORDID KeywordId;
LANGID LangId;
} KEYWORDSELECTOR;
Handling Model Data
Static user independent model - The OEM DLL would typically include some static user independent model data either built into the DLL or in a separate data file included with the DLL. The set of supported keyword IDs returned by the GetCapabilities routine would depend on this data. For example, if the list of supported keyword IDs returned by GetCapabilities includes KwHeyCortana, the static user independent model data would include data for "Hey Cortana" (or its translation) for all the supported languages.
Dynamic user dependent model - IStream provides a random access storage model. The OS passes an IStream interface pointer to many of the methods on the IKeywordDetectorOemAdapter interface. The OS backs the IStream implementation with appropriate storage for up to 1MB of data.
The content and structure of the data within this storage is defined by the OEM. The intended purpose is for persistent storage of user dependent model data computed or retrieved by the OEM DLL.
The OS may call the interface methods with an empty IStream, particularly if the user has never trained a keyword. The OS creates a separate IStream storage for each user. In other words, a given IStream stores model data for one and only one user.
The OEM DLL developer decides how to manage the user independent and user dependent data. However, it shall never store user data anywhere outside the IStream. One possible OEM DLL design would internally switch between accessing the IStream and the static user independent data depending on the parameters of the current method. An alternate design might check the IStream at the start of each method call and add the static user independent data to the IStream if not already present, allowing the rest of the method to access only the IStream for all model data.
Training and Operation Audio Processing
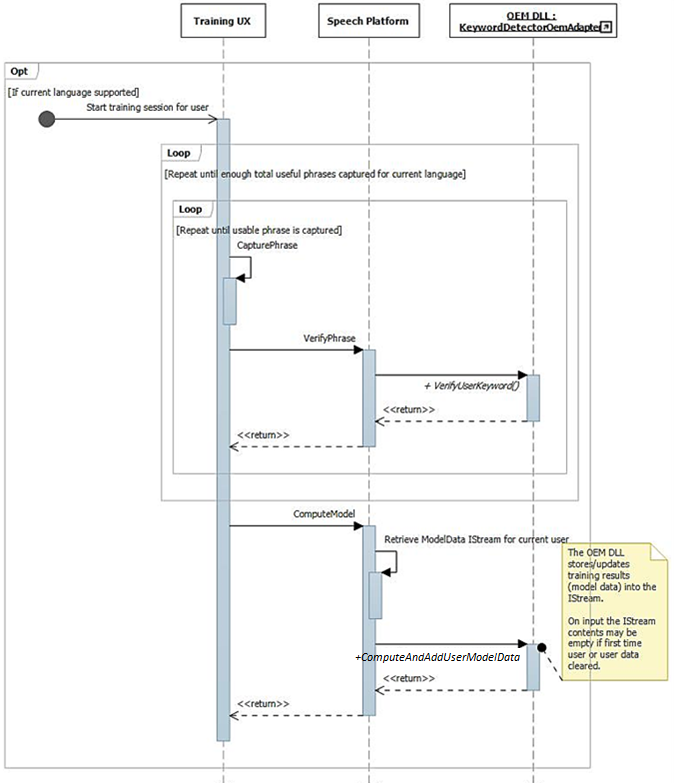
As described previously, the training UI flow results in full phonetically rich sentences being available in the audio stream. Each sentence is individually passed to IKeywordDetectorOemAdapter::VerifyUserKeyword to verify it contains the expected keyword and has acceptable quality. After all sentences are gathered and verified by the UI, they're all passed in one call to IKeywordDetectorOemAdapter::ComputeAndAddUserModelData.
Audio is processed in a unique way for voice activation training. The following table summarizes the differences between voice activation training and the regular voice recognition usage.
| Voice Training | Voice Recognition | |
|---|---|---|
| Mode | Raw | Raw or Speech |
| Pin | Normal | KWS |
| Audio Format | 32-bit float (Type = Audio, Subtype = IEEE_FLOAT, Sampling Rate = 16 kHz, bits = 32) | Managed by OS audio stack |
| Mic | Mic 0 | All mics in array, or mono |
Keyword Recognition System Overview
This diagram provides an overview of the keyword recognition system.
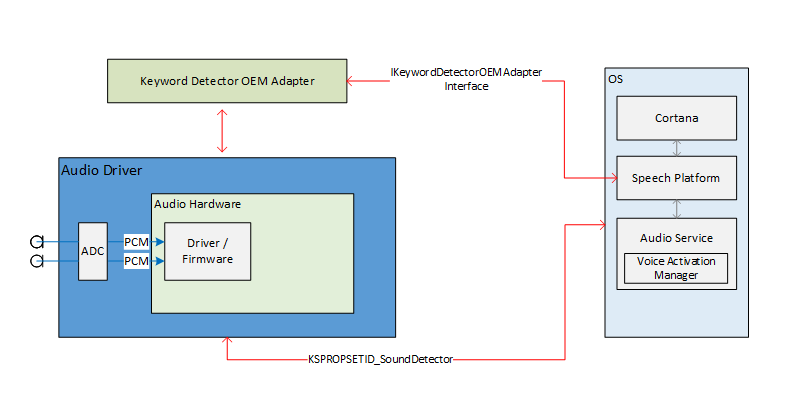
Keyword Recognition Sequence Diagrams
In these diagrams, the speech runtime module is shown as the speech platform. As mentioned previously, the Windows speech platform is used to power all of the speech experiences in Windows 10 such as Cortana and dictation.
During startup, capabilities are gathered using IKeywordDetectorOemAdapter::GetCapabilities.
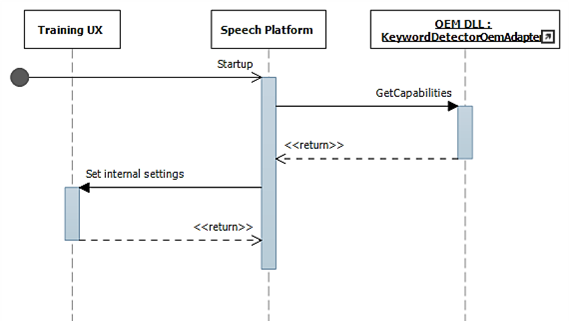
Later when the user selects to "Learn my voice", the training flow is invoked.
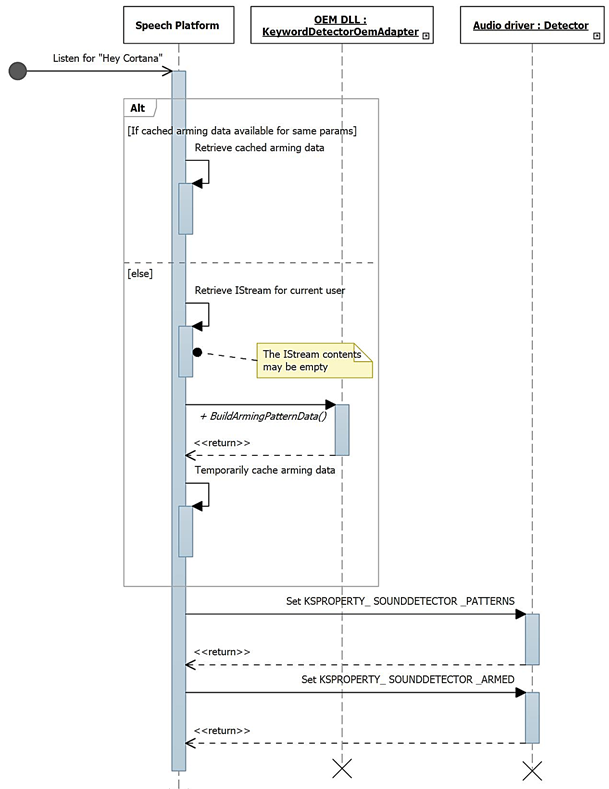
This diagram describes the process of arming for keyword detection.
WAVERT Enhancements
Miniport interfaces are defined to be implemented by WaveRT miniport drivers. These interfaces provide methods to either simplify the audio driver, improve OS audio pipeline performance and reliability, or support new scenarios. A new PnP device interface property is defined allowing the driver to provide a static expressions of its buffer size constraints to the OS.
Buffer Sizes
A driver operates under various constraints when moving audio data between the OS, the driver, and the hardware. These constraints might be due to the physical hardware transport that moves data between memory and hardware, and/or due to the signal processing modules within the hardware or associated DSP.
HW-KWS solutions must support audio capture sizes of at least 100ms and up to 200ms.
The driver expresses the buffer size constraints by setting the DEVPKEY_KsAudio_PacketSize_Constraints device property on the KSCATEGORY_AUDIO PnP device interface of the KS filter that has the KS streaming pins. This property should remain valid and stable while the KS filter interface is enabled. The OS can read this value at any time without having to open a handle to the driver and call on the driver.
DEVPKEY_KsAudio_PacketSize_Constraints
The DEVPKEY_KsAudio_PacketSize_Constraints property value contains a KSAUDIO_PACKETSIZE_CONSTRAINTS structure describing the physical hardware constraints (that is, due to the mechanics of transferring data from the WaveRT buffer to the audio hardware). The structure includes an array of 0 or more KSAUDIO_PACKETSIZE_PROCESSINGMODE_CONSTRAINT structures describing constraints specific to any signal processing modes. The driver sets this property before calling PcRegisterSubdevice or otherwise enabling its KS filter interface for its streaming pins.
IMiniportWaveRTInputStream
A driver implements this interface for better coordination of audio dataflow from the driver to OS. If this interface is available on a capture stream, the OS uses methods on this interface to access data in the WaveRT buffer. For more information, see IMiniportWaveRTInputStream::GetReadPacket
IMiniportWaveRTOutputStream
A WaveRT miniport optionally implements this interface to be advised of write progress from the OS and to return precise stream position. For more information see IMiniportWaveRTOutputStream::SetWritePacket, IMiniportWaveRTOutputStream::GetOutputStreamPresentationPosition and IMiniportWaveRTOutputStream::GetPacketCount.
Performance counter timestamps
Several of the driver routines return Windows performance counter timestamps reflecting the time at which samples are captured or presented by the device.
In devices that have complex DSP pipelines and signal processing, calculating an accurate timestamp can be challenging and should be done thoughtfully. The timestamps shouldn't reflect the time at which samples were transferred to or from the OS to the DSP.
- Within the DSP, track sample timestamps using some internal DSP wall clock.
- Between the driver and DSP, calculate a correlation between the Windows performance counter and the DSP wall clock. Procedures for this can range from simple (but less precise) to fairly complex or novel (but more precise).
- Factor in any constant delays due to signal processing algorithms or pipeline or hardware transports, unless these delays are otherwise accounted for.
Burst Read Operation
This section describes the OS and driver interaction for burst reads. Burst read can happen outside of the voice activation scenario as long as the driver supports the packet based streaming WaveRT model, including the IMiniportWaveRTInputStream::GetReadPacket function.
Two burst example read scenarios are discussed. In one scenario, if the miniport supports a pin having pin category KSNODETYPE_AUDIO_KEYWORDDETECTOR then the driver begins capturing and internally buffering data when a keyword is detected. In another scenario, the driver can internally buffer data outside of the WaveRT buffer if the OS isn't reading data quickly enough by calling IMiniportWaveRTInputStream::GetReadPacket.
To burst data that has been captured before transition to KSSTATE_RUN, the driver must retain accurate sample timestamp information along with the buffered capture data. The timestamps identify the sampling instant of the captured samples.
After the stream transitions to KSSTATE_RUN, the driver immediately sets the buffer notification event because it already has data available.
On this event, the OS calls GetReadPacket() to get information about the available data.
The driver returns the packet number of the valid captured data (0 for the first packet after the transition from KSSTATE_STOP to KSSTATE_RUN), from which the OS can derive the packet position within the WaveRT buffer and the packet position relative to start of stream.
The driver also returns the performance counter value that corresponds to the sampling instant of the first sample in the packet. This performance counter value might be relatively old, depending on how much capture data has been buffered within the hardware or driver (outside of the WaveRT buffer).
If there's more unread buffered data available the driver either:
- Immediately transfers that data into the available space of WaveRT buffer (that is, space not used by the packet returned from GetReadPacket), returns true for MoreData, and sets the buffer notification event before returning from this routine. Or,
- Programs hardware to burst the next packet into the available space of the WaveRT buffer, returns false for MoreData, and later sets the buffer event when the transfer completes.
The OS reads data from the WaveRT buffer using the information returned by GetReadPacket().
The OS waits for the next buffer notification event. The wait might terminate immediately if the driver set the buffer notification in step (2c).
If the driver didn't immediately set the event in step (2c), the driver sets the event after it transfers more captured data into the WaveRT buffer and makes it available for the OS to read
Go to (2). For KSNODETYPE_AUDIO_KEYWORDDETECTOR keyword detector pins, drivers should allocate enough internal burst buffering for at least 5000ms of audio data. If the OS fails to create a stream on the pin before the buffer overflows then the driver can end the internal buffering activity and free associated resources.
Wake on Voice
Wake On Voice (WoV) enables the user to activate and query a speech recognition engine from a screen off, lower power state, to a screen on, full power state by saying a certain keyword, such as "Hey Cortana."
This feature allows for the device to be always listening for the user's voice while the device is in a low power state, including when the screen is off and the device is idle. It does this by using a listening mode, which is lower power when compared to the higher power usage seen during normal microphone recording. The low power speech recognition allows a user to say a predefined key phrase like "Hey Cortana," followed by a chained speech phrase like "when's my next appointment" to invoke speech in a hands-free manner. This works regardless of whether the device is in use or idle with the screen off.
The audio stack is responsible for communicating the wake data (speaker ID, keyword trigger, confidence level) and notifying interested clients that the keyword is detected.
Validation on Modern Standby Systems
WoV from a system idle state can be validated on Modern Standby systems using the Modern Standby Wake on Voice Basic Test on AC-power Source and the Modern Standby Wake on Voice Basic Test on DC-power Source in the HLK. These tests check that the system has a hardware keyword spotter (HW-KWS), is able to enter the Deepest Runtime Idle Platform State (DRIPS) and is able to wake from Modern Standby on voice command with system resume latency of less than or equal to one second.