Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Importante
Azure Data Studio se retira el 28 de febrero de 2026. Se recomienda usar la extensión MSSQL para Visual Studio Code. Para más información sobre la migración a Visual Studio Code, visite ¿Qué sucede con Azure Data Studio?
Se aplica a:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Jupyter Notebook es una aplicación web de código abierto que le permite crear y compartir documentos que contengan código en vivo, ecuaciones, visualizaciones y texto narrativo. En el uso, se incluye la transformación y limpieza de datos, simulación numérica, modelado estadístico, visualización de datos y aprendizaje automático.
En este artículo se explica cómo crear un cuaderno en la última versión de Azure Data Studio y cómo empezar a crear cuadernos propios con kernel distintos.
Vea este vídeo breve de 5 minutos para obtener una introducción a los cuadernos en Azure Data Studio:
Creación de un cuaderno
Hay varias maneras de crear un cuaderno. En cada caso, se abre un nuevo archivo denominado Notebook-1.ipynb.
Vaya al menú Archivo en Azure Data Studio y seleccione Nuevo cuaderno.
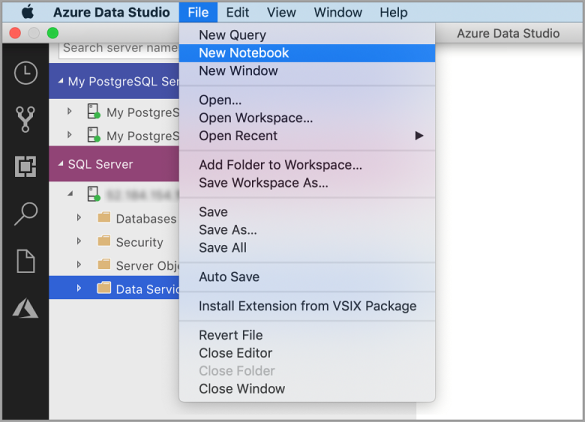
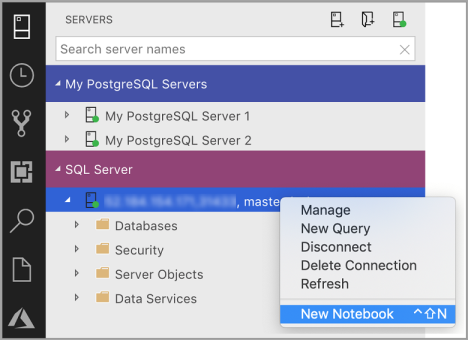
Haga clic con el botón derecho en una conexión de SQL Server y seleccione Nuevo cuaderno.
Abra la paleta de comandos (Ctrl + Mayús + P), escriba "nuevo cuaderno" y seleccione el comando Nuevo cuaderno.

Conexión a un kernel
Los notebooks de Azure Data Studio admiten varios kernels, incluidos SQL Server, Python, PySpark, y otros. Cada kernel admite un lenguaje distinto en las celdas de código del cuaderno. Por ejemplo, cuando se conecta al kernel de SQL Server, puede escribir y ejecutar instrucciones T-SQL en una celda de código del cuaderno.
Adjuntar a proporciona el contexto para el kernel. Por ejemplo, si utiliza SQL Kernel, puede conectar a cualquiera de sus instancias de SQL Server. Si está utilizando el núcleo de Python3, debe conectarse a localhost y puede usar este núcleo para el desarrollo local de Python.
El kernel de SQL también se puede usar para conectarse a instancias de servidor de PostgreSQL. Si es desarrollador de PostgreSQL y quiere conectar los cuadernos al servidor de PostgreSQL, descargue la extensión PostgreSQL en el Marketplace de extensiones de Azure Data Studio para conectarse al servidor de PostgreSQL.
Si está conectado a un clúster de macrodatos de SQL Server 2019, el valor de Adjuntar a predeterminado es el punto final del clúster. Puede enviar código de Python, Scala y R mediante el proceso de Spark del clúster.
| Núcleo | Descripción |
|---|---|
| Núcleo SQL | Escribe código SQL destinado a la base de datos relacional. |
| PySpark3 y Kernel de PySpark | Escribe código en Python utilizando el cómputo de Spark desde el clúster. |
| Kernel de Spark | Escribe código en Scala y R utilizando el entorno de ejecución de Spark del clúster. |
| Python Kernel | Escribe código de Python para el desarrollo local. |
Para obtener más información sobre núcleos específicos, consulte:
- Creación y ejecución de un cuaderno de SQL Server
- Creación y ejecución de un cuaderno de Python
- Extensión de Kqlmagic en Azure Data Studio: extiende las capacidades del kernel de Python.
Adición de una celda de código
Las celdas de código permiten ejecutar código de forma interactiva dentro del cuaderno.
Haga clic en el comando + Celda de la barra de herramientas y seleccione Celda de código para agregar una nueva celda de código. Se agrega una nueva celda de código después de la celda seleccionada actualmente.
Escriba el código en la celda del kernel seleccionado. Por ejemplo, si utiliza el kernel de SQL, puede escribir comandos T-SQL en la celda de código.
La escritura de código con el kernel de SQL es similar a un editor de consultas de SQL. La celda de código admite una experiencia de programación de SQL moderna con características integradas, como un editor enriquecido de SQL, IntelliSense y fragmentos de código integrados. Los fragmentos de código permiten generar la sintaxis SQL adecuada para crear bases de datos, tablas, vistas y procedimientos almacenados y para actualizar los objetos de base de datos existentes. Use fragmentos de código para crear rápidamente copias de la base de datos con fines de desarrollo o prueba y para generar y ejecutar scripts.
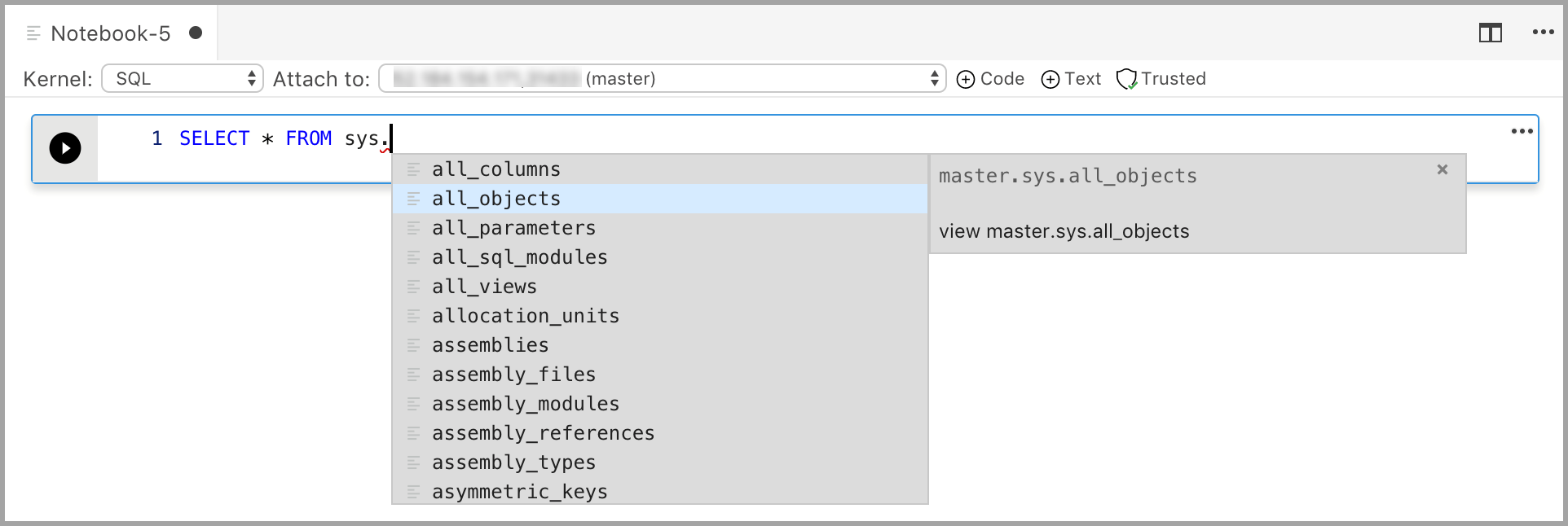
Adición de una celda de texto
Las celdas de texto permiten agregar bloques de texto de Markdown entre las celdas de código para documentar el código.
Haga clic en el comando + Celda de la barra de herramientas y seleccione Celda de texto para agregar una nueva celda de texto.
La celda comienza en modo de edición en el que puede escribir texto en Markdown. A medida que escribe, se muestra una vista previa.
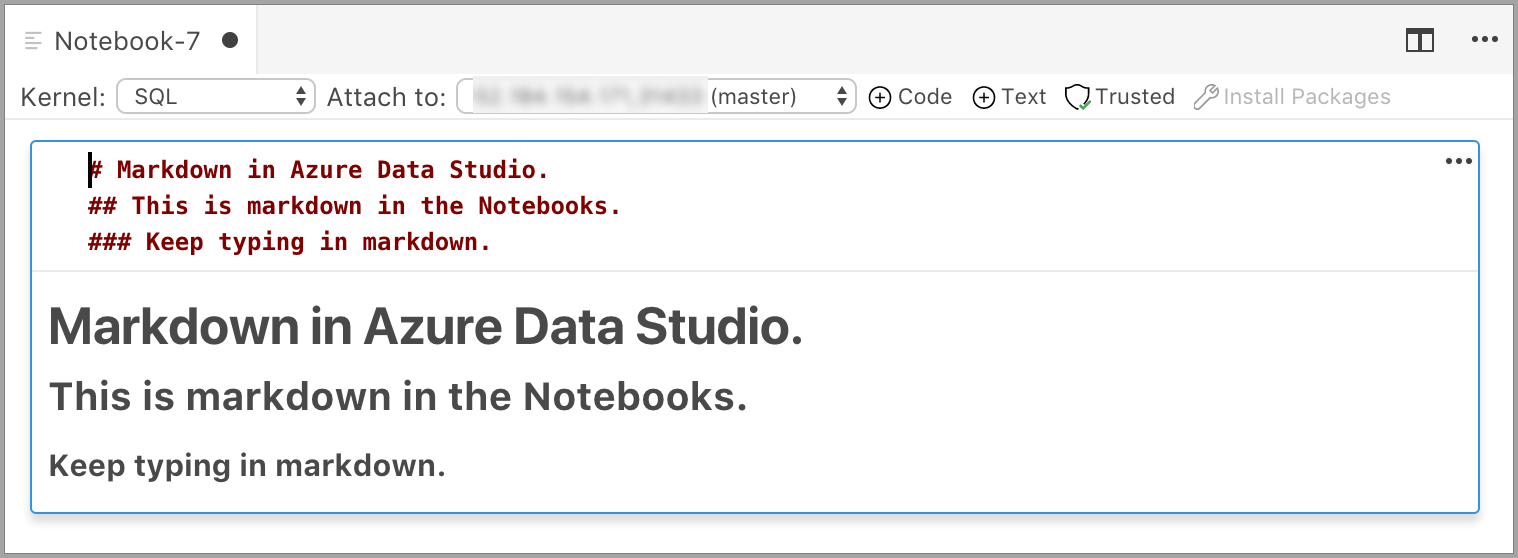
Al hacer clic fuera de la celda de texto, se muestra el texto de Markdown.
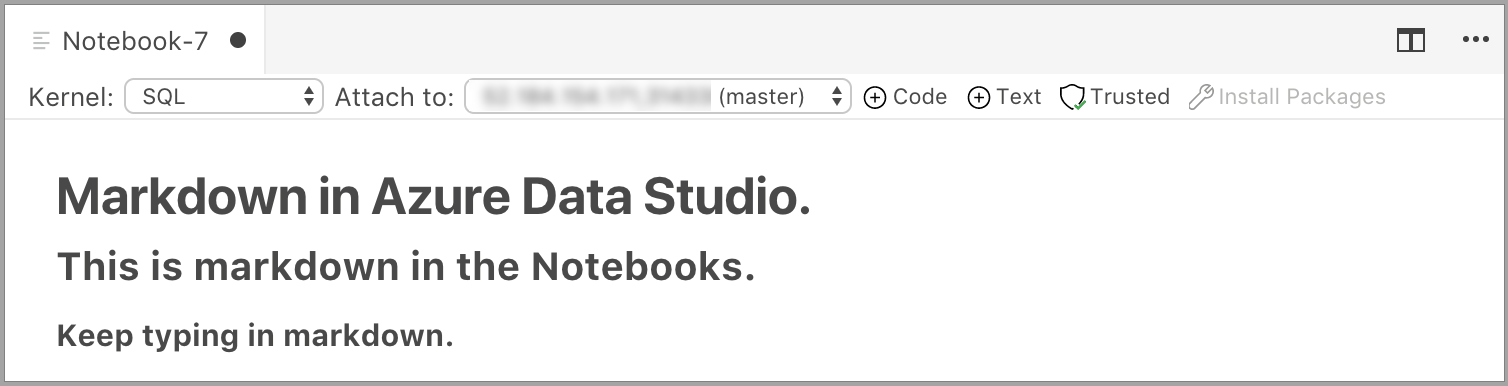
Si vuelve a hacer clic en la celda de texto, cambia al modo de edición.
Ejecución de una celda
Para ejecutar una sola celda, haga clic en Ejecutar celda (la flecha redonda de color negro) a la izquierda de la celda o seleccione la celda y presione F5. Puede hacer clic en Ejecutar todas en la barra de herramientas para ejecutar todas las celdas; estas se ejecutan de una en una y la ejecución se detiene si se produce un error en alguna celda.
Los resultados de la celda se muestran debajo de ella. Si quiere borrar los resultados de todas las celdas ejecutadas del cuaderno,seleccione el botón Borrar resultados de la barra de herramientas.
Guarda un cuaderno
Para guardar un cuaderno, realice una de las siguientes operaciones.
- Presione Ctrl + S.
- Seleccione Guardar en el menú Archivo.
- En el menú Archivo, seleccione Guardar como... .
- Seleccione Guardar todo en el menú Archivo; se guardarán todos los cuadernos abiertos.
- En la paleta de comandos, escriba Archivo: Guardar.
Los cuadernos se guardan como archivos .ipynb.
De confianza y No de confianza
El valor predeterminado de los cuadernos abiertos en Azure Data Studio es De confianza.
Si abre un cuaderno desde otro origen, se abre en modo No confiable y luego puede marcarlo como Confiable.
Ejemplos
En los siguientes ejemplos se muestra el uso de diferentes kernels para ejecutar un sencillo comando "Hola mundo". Seleccione el kernel, escriba el código de ejemplo en una celda y haga clic en Ejecutar celda.
Pyspark
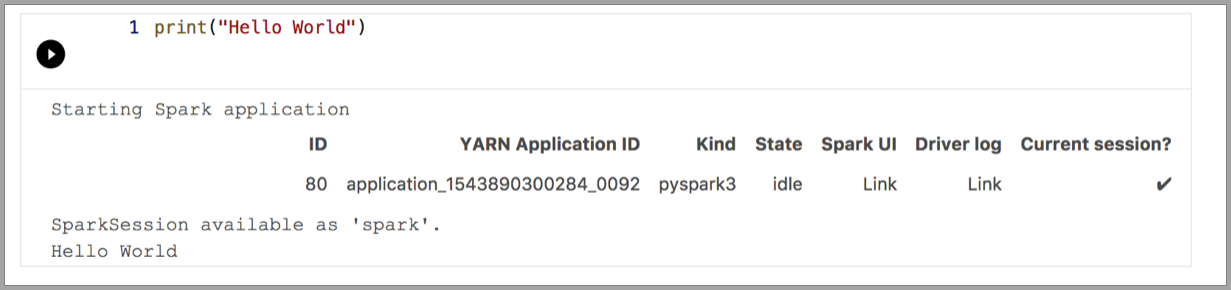
Spark | Lenguaje Scala
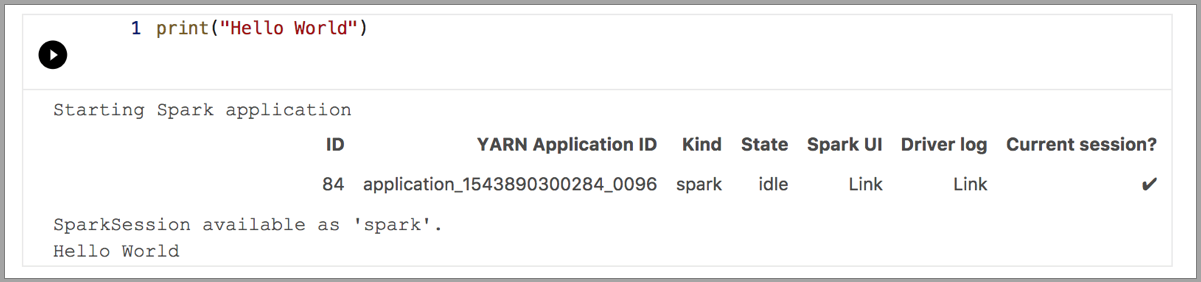
Spark | Lenguaje R
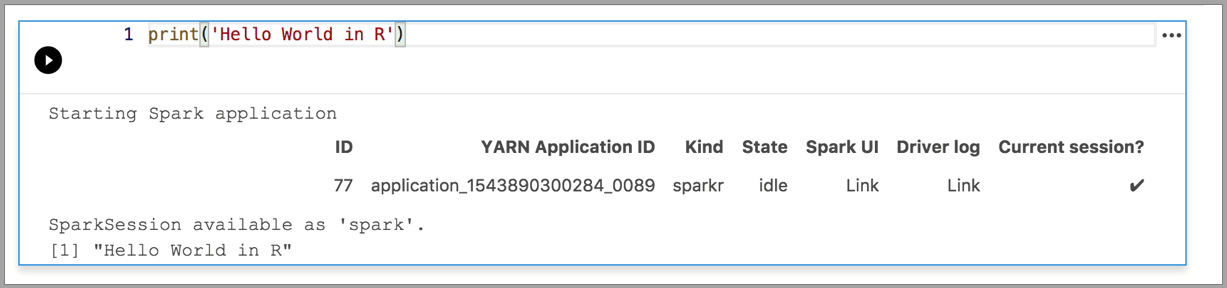
Python 3

Pasos siguientes
- Creación y ejecución de un cuaderno de SQL Server.
- Creación y ejecución de un cuaderno de Python
- Ejecución de scripts de Python y R en cuadernos de Azure Data Studio con Machine Learning Services de SQL Server.
- Implementación de clústeres de macrodatos de SQL Server con un cuaderno de Azure Data Studio.
- Administración de clústeres de macrodatos de SQL Server con cuadernos de Azure Data Studio.
- Ejecución de un cuaderno de ejemplo con Spark.