Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Se aplica a:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
Los clústeres de macrodatos de Microsoft SQL Server 2019 se retiran. La compatibilidad con clústeres de macrodatos de SQL Server 2019 finalizó a partir del 28 de febrero de 2025. Para obtener más información, consulte la entrada de blog del anuncio y las opciones de macrodatos en la plataforma de Microsoft SQL Server.
En este tutorial se muestra cómo cargar y ejecutar un cuaderno en Azure Data Studio en un clúster de macrodatos de SQL Server 2019. Esto permite a los científicos de datos e ingenieros de datos ejecutar código de Python, S o Scala en el clúster.
Tip
Si lo prefiere, puede descargar y ejecutar un script con los comandos de este tutorial. Para obtener instrucciones, vea los ejemplos de Spark en GitHub.
Prerequisites
-
Herramientas de macrodatos
- kubectl
- Azure Data Studio
- Extensión de SQL Server 2019
- Cargar datos de ejemplo en un clúster de macrodatos
Descargar el archivo de cuaderno de ejemplo
Siga estas instrucciones para cargar el archivo de cuaderno de ejemplo spark-sql.ipynb en Azure Data Studio.
Abra un símbolo del sistema de Bash (Linux) o Windows PowerShell.
Vaya al directorio donde quiera descargar el archivo del cuaderno de ejemplo.
Ejecute el siguiente comando de curl para descargar el archivo del cuaderno desde GitHub:
curl https://raw.githubusercontent.com/Microsoft/sql-server-samples/master/samples/features/sql-big-data-cluster/spark/data-loading/transform-csv-files.ipynb -o transform-csv-files.ipynb
Apertura del cuaderno
En los pasos siguientes, se muestra cómo abrir el archivo del cuaderno en Azure Data Studio:
En Azure Data Studio, conéctese a la instancia maestra del clúster de macrodatos. Para obtener más información, vea Conexión a un clúster de macrodatos.
Haga doble clic en la conexión de la puerta de enlace de HDFS/Spark de la ventana Servidores. Después, seleccione Abrir cuaderno.
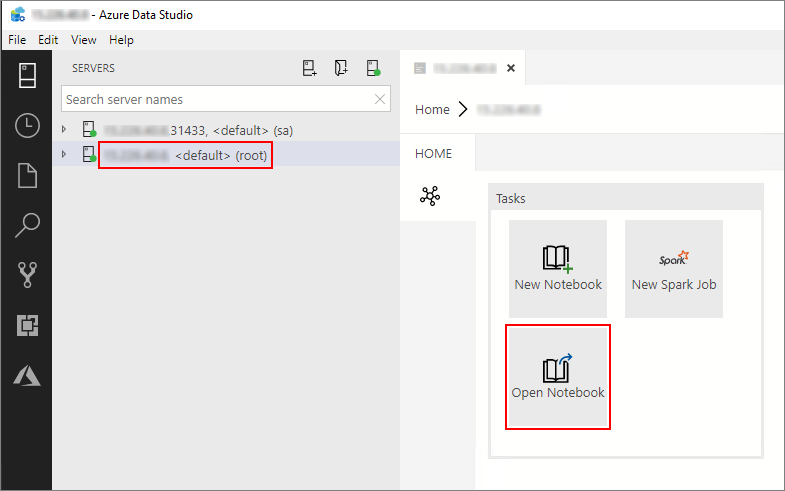
Espere hasta que se rellenen el Kernel y el contexto del destino (Conectar a). Establezca el Kernel en PySpark3 y el valor de Conectar a en la dirección IP del punto de conexión del clúster de macrodatos.
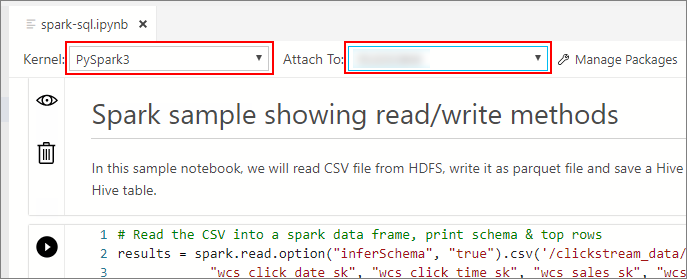
Important
En Azure Data Studio, todos los tipos de cuadernos Spark (Scala Spark, PySpark y SparkR) definen algunas variables importantes relacionadas con la sesión de Spark tras la primera ejecución de la celda. Estas variables son spark, sc y sqlContext. Al copiar la lógica fuera de los cuadernos para el envío por lotes (en un archivo de Python que se va a ejecutar con azdata bdc spark batch create, por ejemplo), asegúrese de definir las variables en consecuencia.
Ejecutar las celdas del cuaderno
Para ejecutar cada celda del cuaderno, pulse el botón Reproducir a la izquierda de la celda. Los resultados se muestran en el cuaderno una vez finalizada la ejecución de la celda.

Ejecute todas las celdas del cuaderno de ejemplo en sucesión. Para obtener más información sobre el uso de cuadernos con Clústeres de macrodatos de SQL Server, vea los siguientes recursos:
Next steps
Obtenga más información sobre los cuadernos: