Ejecución de una aplicación de n niveles en varias regiones de Azure Stack Hub para lograr alta disponibilidad
Esta arquitectura de referencia muestra un conjunto de procedimientos de demostrada eficacia para la ejecución de una aplicación de n niveles en varias regiones de Azure Stack Hub, con la finalidad de conseguir disponibilidad y una sólida estructura de recuperación ante desastres. En este documento, Traffic Manager se usa para lograr alta disponibilidad. Sin embargo, si Traffic Manager no es una opción preferida en el entorno, también podría usarse un par de equilibradores de carga de alta disponibilidad.
Nota:
Tenga en cuenta que la instancia de Traffic Manager que se usa en la arquitectura siguiente se debe configurar en Azure y los puntos de conexión usados para configurar el perfil de Traffic Manager deben ser direcciones IP enrutables públicamente.
Architecture
Esta arquitectura se basa en la que se muestra en Aplicación de n niveles con SQL Server.
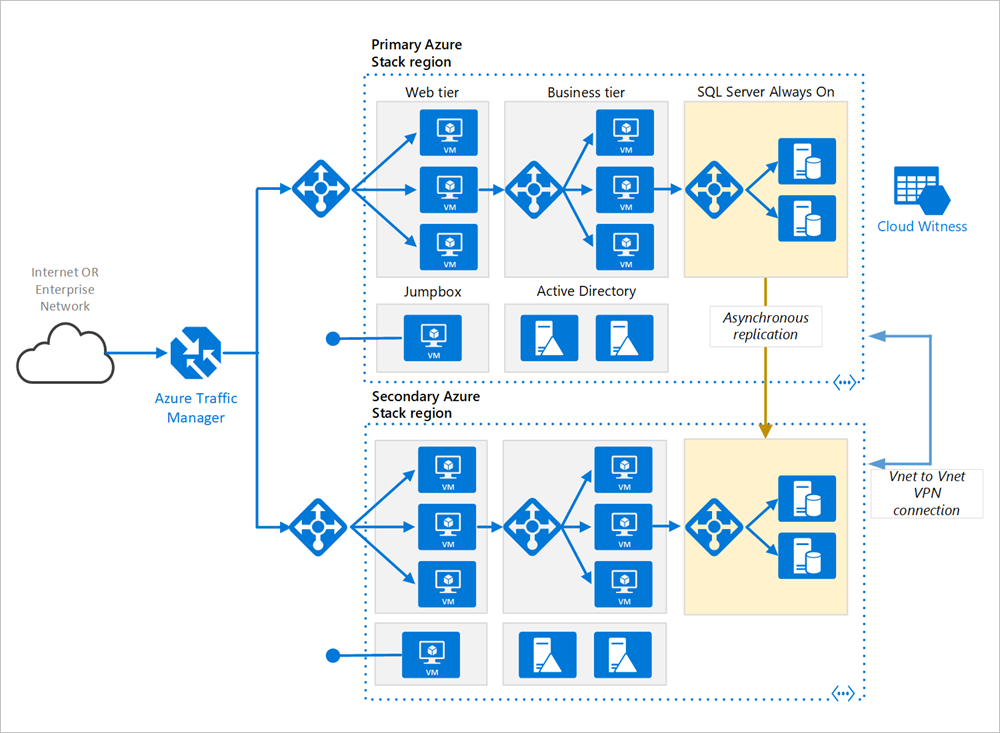
Regiones primarias y secundarias Use dos regiones para lograr una mayor disponibilidad. Una es la región primaria. La otra región es para la conmutación por error.
Azure Traffic Manager. Traffic Manager enruta las solicitudes entrantes a una de las regiones. Durante las operaciones normales enruta las solicitudes a la región primaria. Si dicha región no está disponible, Traffic Manager conmuta por error a la región secundaria. Para más información, consulte la sección Configuración de Traffic Manager.
Grupos de recursos. Cree grupos de recursos independientes para la región primaria y para la región secundaria. De esta manera, obtiene la flexibilidad para administrar cada región como una única colección de recursos. Por ejemplo, podría volver a implementar una región, sin quitar la otra. Vincule los grupos de recursos, de modo que pueda ejecutar una consulta para obtener una lista de todos los recursos de la aplicación.
Redes virtuales. Cree una red virtual independiente para cada región. Asegúrese de que los espacios de direcciones no se superpongan.
Grupo de disponibilidad AlwaysOn de SQL Server Si usa SQL Server, se recomiendan los grupos de disponibilidad AlwaysOn de SQL para conseguir alta disponibilidad. Cree un único grupo de disponibilidad que incluya las instancias de SQL Server en ambas regiones.
Conexión VPN de red virtual a red virtual. Como Emparejamiento de VNET todavía no está disponible en Azure Stack Hub, use la conexión VPN de red virtual a red virtual para conectar las dos redes virtuales. Consulte Red virtual a red virtual en Azure Stack Hub para más información.
Recomendaciones
Una arquitectura de varias regiones puede proporcionar una mayor disponibilidad que la implementación en una sola región. Si una interrupción regional afecta a la región primaria, puede usar Traffic Manager para conmutar por error en la región secundaria. Esta arquitectura también puede ayudar si un determinado subsistema de la aplicación produce un error.
Existen varios enfoques generales para lograr una alta disponibilidad en regiones:
Activo/pasivo con espera activa. Un tráfico se dirige a una región, mientras el otro se encuentra en espera activa. Espera activa significa que las máquinas virtuales de la región secundaria están siempre asignadas y en funcionamiento.
Activo/pasivo con espera pasiva. El tráfico se dirige a una región, mientras el otro se encuentra en espera pasiva. Espera pasiva significa que las máquinas virtuales de la región secundaria no se asignan hasta que son necesarias para una conmutación por error. Este enfoque tiene un coste menor de ejecución, pero generalmente tarda más en ponerse en línea durante un error.
Activo/activo. Ambas regiones están activas y se equilibra la carga de las solicitudes entre ellas. Si una región no está disponible, se saca de la rotación.
Esta arquitectura de referencia se centra en el enfoque activo/pasivo con espera activa y usa Traffic Manager para la conmutación por error. Podría implementar un número pequeño de máquinas virtuales para la espera activa y luego escalarlas horizontalmente si es necesario.
Configuración de Traffic Manager
Al configurar Traffic Manager, tenga en cuenta lo siguiente:
Enrutamiento. Traffic Manager admite varios algoritmos de enrutamiento. Para el escenario descrito en este artículo, use el enrutamiento de prioridad (anteriormente conocido como enrutamiento de conmutación por error). Con esta configuración, Traffic Manager envía todas las solicitudes a la región primaria, a no ser que no sea posible comunicarse con ella. En ese momento, conmuta por error automáticamente a la región secundaria. Consulte Configuración del método de conmutación por error.
Sondeo de mantenimiento. Traffic Manager usa un sondeo HTTP (o HTTPS) para supervisar la disponibilidad de cada región. El sondeo comprueba si hay una respuesta HTTP 200 para una ruta de acceso de dirección URL especificada. Como procedimiento recomendado, cree un punto de conexión que indique el estado general de la aplicación y úselo para el sondeo de estado. En caso contrario, el sondeo podría informar de un punto de conexión correcto cuando realmente se producen errores en partes críticas de la aplicación. Para más información, consulte Patrón Health Endpoint Monitoring.
Cuando Traffic Manager conmuta por error, hay un período de tiempo en que los clientes no pueden comunicarse con la aplicación. La duración viene determinada por los siguientes factores:
El sondeo de estado debe detectar que la región primaria se ha vuelto inaccesible.
Los servidores DNS deben actualizar los registros DNS almacenados en caché con la dirección IP, lo cual depende del período de vida (TTL) de DNS. El TTL predeterminado es de 300 segundos (5 minutos), pero puede configurar este valor al crear el perfil de Traffic Manager.
Para más información, consulte el artículo sobre la supervisión de Traffic Manager.
Si Traffic Manager conmuta por error, se recomienda realizar una conmutación por recuperación manual en lugar de implementar una automática. En caso contrario, puede crear una situación donde la aplicación va y viene incesantemente entre regiones. Compruebe que todos los subsistemas de aplicación tengan un estado correcto antes de la conmutación por recuperación.
Tenga en cuenta que Traffic Manager conmuta por recuperación automáticamente de forma predeterminada. Para evitar esto, reduzca manualmente la prioridad de la región primaria después de un evento de conmutación por error. Por ejemplo, suponga que la región primaria tiene la prioridad 1 y la secundaria la prioridad 2. Después de una conmutación por error, establezca la región primaria en la prioridad 3 para evitar la conmutación por recuperación automática. Cuando esté listo para cambiar de nuevo, actualice la prioridad a 1.
El siguiente comando de la CLI de Azure actualiza la prioridad:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type externalEndpoints --priority 3
Otro enfoque consiste en deshabilitar temporalmente el punto de conexión hasta que esté listo para conmutar por recuperación:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type externalEndpoints --endpoint-status Disabled
Dependiendo de la causa de una conmutación por error, tendrá que volver a implementar los recursos dentro de una región. Antes de proceder a la conmutación por recuperación, realice una prueba de preparación operativa. La prueba debe comprobar aspectos como:
Máquinas virtuales configuradas correctamente. (Todo el software necesario está instalado, IIS está en funcionamiento, etc.).
El estado de los subsistemas de aplicación es correcto.
Pruebas funcionales. (Por ejemplo, la capa de base de datos es accesible desde la capa web).
Configuración de los grupos de disponibilidad AlwaysOn de SQL Server
Antes de Windows Server 2016, los grupos de disponibilidad AlwaysOn de SQL Server requerían un controlador de dominio y todos los nodos del grupo de disponibilidad debían estar en el mismo dominio de Active Directory (AD).
Para configurar el grupo de disponibilidad:
Coloque dos controladores de dominio, como mínimo, en cada región.
Asigne una dirección IP estática a cada controlador de dominio.
Cree una VPN para habilitar la comunicación entre dos redes virtuales.
Para cada red virtual, agregue las direcciones IP de los controladores de dominio (de ambas regiones) a la lista de servidores DNS. Puede usar el siguiente comando de la CLI. Para más información, consulte Cambio de servidores DNS.
az network vnet update --resource-group <resource-group> --name <vnet-name> --dns-servers "10.0.0.4,10.0.0.6,172.16.0.4,172.16.0.6"Cree un clúster de Clústeres de conmutación por error de Windows Server (WSFC) que incluya las instancias de SQL Server en ambas regiones.
Cree un grupo de disponibilidad AlwaysOn de SQL Server que incluya las instancias de SQL Server en las regiones primaria y secundaria. Consulte Extending Always On Availability Group to Remote Azure Datacenter (PowerShell) (Extensión de un grupo de disponibilidad AlwaysOn para el acceso remoto a un centro de datos de Azure [PowerShell)] para conocer los pasos.
Coloque la réplica principal en la región primaria.
Coloque una o varias réplicas secundarias en la región primaria. Configure estos elementos para usar la confirmación sincrónica con conmutación automática por error.
Coloque una o varias réplicas secundarias en la región secundaria. Por motivos de rendimiento, configure estas opciones para usar confirmación asincrónica. (De lo contrario, todas las transacciones de T-SQL deberán esperar el recorrido de ida y vuelta a través de la red hasta la región secundaria).
Nota:
Las réplicas de confirmación asincrónica no admiten la conmutación automática por error.
Consideraciones sobre disponibilidad
Con una aplicación de N niveles compleja, no es necesario replicar toda la aplicación en la región secundaria. En su lugar, puede replicar simplemente un subsistema crítico que sea necesario para permitir la continuidad empresarial.
Traffic Manager es un posible punto de error en el sistema. Si se produce un error en Traffic Manager, los clientes no podrán acceder a la aplicación durante el tiempo de inactividad. Revise el Acuerdo de Nivel de Servicio de Traffic Manager y determine si el uso de Traffic Manager por sí solo cumple sus requisitos empresariales de alta disponibilidad. Si no es así, considere la posibilidad de agregar otra solución de administración de tráfico como conmutación por recuperación. Si el servicio Azure Traffic Manager no funciona, cambie los registros CNAME de DNS para que apunten a otro servicio de administración del tráfico. (Este paso debe realizarse manualmente, y la aplicación dejará de estar disponible hasta que se propaguen los cambios de DNS).
Para el clúster de SQL Server, hay dos escenarios de conmutación por error que se deben tener en cuenta:
Todas las réplicas de base de datos de SQL Server de la región primaria generarán un error. Esto podría ocurrir, por ejemplo, durante una interrupción regional. En ese caso, debe conmutar por error manualmente el grupo de disponibilidad, aunque Traffic Manager conmute por error automáticamente en el servidor front-end. Siga los pasos que se indican en Perform a Forced Manual Failover of a SQL Server Availability Group (Realización de una conmutación por error manual forzada de un grupo de disponibilidad de SQL Server), donde se describe cómo realizar una conmutación por error forzada mediante SQL Server Management Studio, Transact-SQL o PowerShell en SQL Server 2016.
Advertencia
Con la conmutación por error forzada, se corre el riesgo de pérdida de datos. Una vez que la región primaria vuelve a estar en línea, tome una instantánea de la base de datos y use tablediff para encontrar las diferencias.
Traffic Manager conmuta por error a la región secundaria, pero la réplica principal de base de datos SQL Server sigue estando disponible. Por ejemplo, si el nivel de front-end produjera un error, las máquinas virtuales de SQL Server no se verían afectadas. En ese caso, el tráfico de Internet se enrutaría a la región secundaria y esa región podría seguir conectándose a la réplica principal. Sin embargo, habrá una mayor latencia, ya que las conexiones de SQL Server atraviesan las regiones. En esta situación, debe realizar una conmutación por error manual como se indica a continuación:
Cambie temporalmente una réplica de base de datos de SQL Server de la región secundaria a confirmación sincrónica. De esta forma, se garantiza que no haya pérdida de datos durante la conmutación por error.
Conmute por error a esa réplica.
Cuando conmute por recuperación a la región primaria, restaure el valor de configuración de confirmación asincrónica.
Consideraciones sobre la manejabilidad
Al actualizar la implementación, actualice una región cada vez para reducir la probabilidad de un error global derivado de una configuración incorrecta o un error en la aplicación.
Pruebe la resistencia del sistema a los errores. Estos son algunos escenarios comunes de error que se pueden probar:
Apagado de las instancias de máquina virtual.
Recursos de presión, como CPU y memoria.
Desconexión o retraso de la red.
Bloqueo de procesos.
Caducidad de certificados.
Simulación de errores de hardware.
Apagado del servicio DNS en los controladores de dominio.
Medición de los tiempos de recuperación y comprobación de que cumplen los requisitos empresariales. Pruebe también combinaciones de modos de error.
Pasos siguientes
- Para más información sobre los patrones de nube de Azure, consulte Patrones de diseño en la nube.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de