Inicio rápido: Reconocimiento y conversión de voz en texto
Importante
Los elementos marcados (versión preliminar) en este artículo se encuentran actualmente en versión preliminar pública. Esta versión preliminar se ofrece sin acuerdo de nivel de servicio y no se recomienda para las cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas. Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
En este inicio rápido, probará la conversión de voz en tiempo real en texto en Azure AI Foundry.
Requisitos previos
- Una suscripción a Azure: cree una cuenta gratuita.
- Algunas características de servicios de Azure AI son gratuitas para probar en el portal de Azure AI Foundry. Para acceder a todas las funcionalidades descritas en este artículo, debe conectar los servicios de IA a Azure AI Foundry.
Pruebe la conversión de voz en tiempo real en texto
Vaya al proyecto de Azure AI Foundry. Si necesita crear un proyecto, consulte Creación de un proyecto de Azure AI Foundry.
Seleccione Áreas de juegos en el panel izquierdo y, a continuación, seleccione un área de juegos para usarla. En este ejemplo, seleccione Probar el área de juegos de voz.
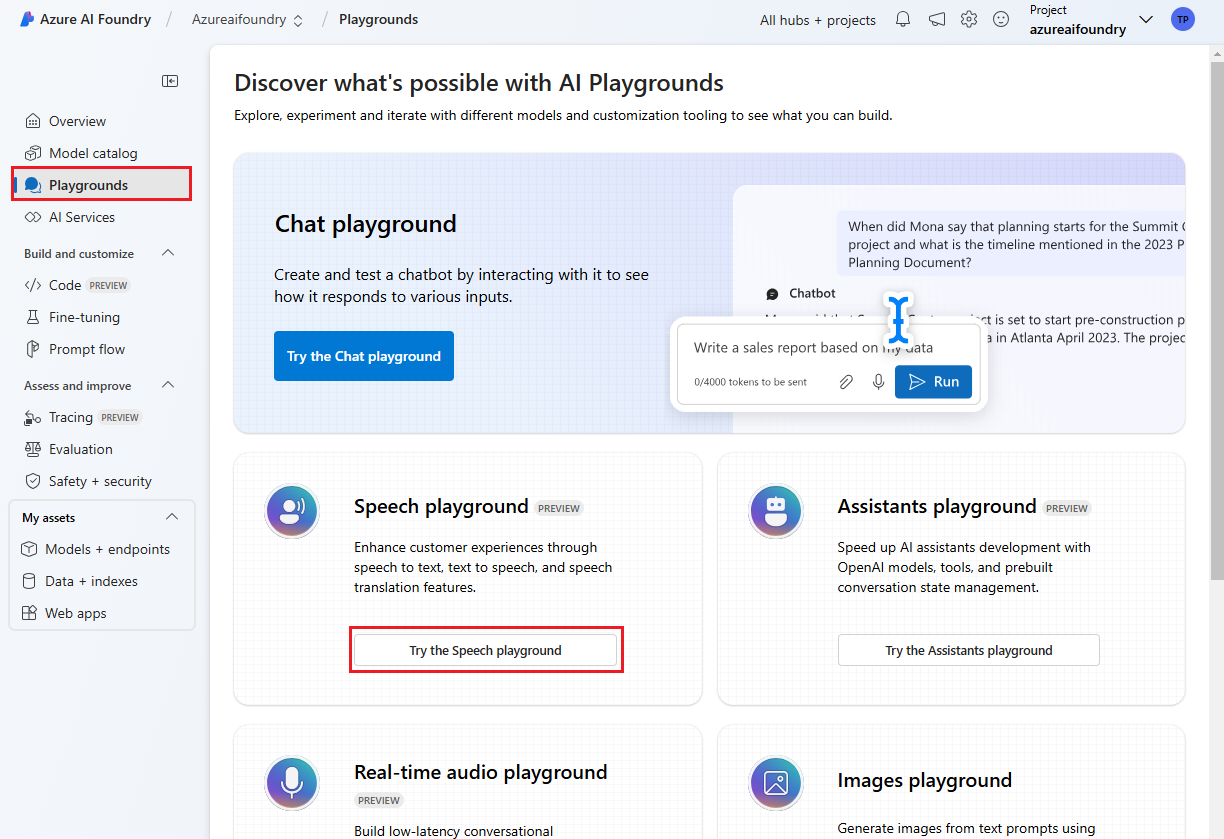
Opcionalmente, puede seleccionar una conexión diferente para usarla en el área de juegos. En el área de juegos de voz, puede conectarse a los recursos de varios servicios de Azure AI o a los recursos del servicio voz.
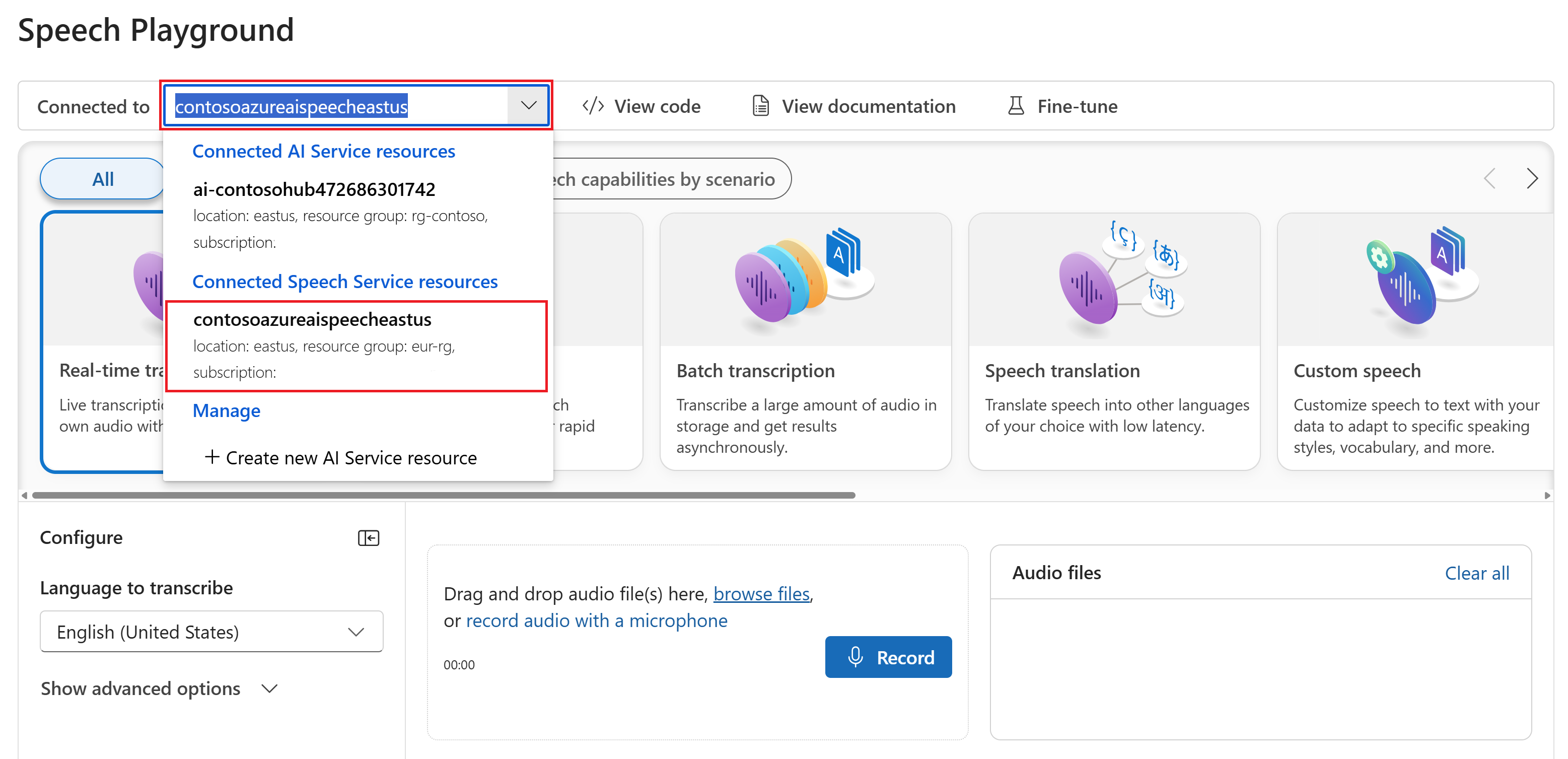
Seleccione Transcripción en tiempo real.
Seleccione Mostrar opciones avanzadas para configurar opciones de voz en texto, como:
- Identificación de idiomas: se utiliza para identificar los idiomas hablados en el audio al compararlos con una lista de idiomas admitidos. Para obtener más información sobre las opciones de identificación de idiomas, como el reconocimiento al inicio y continuo, consulte Identificación de idiomas.
- Diarización de orador: se utiliza para identificar y separar los oradores en audio. La diarización distingue entre los diferentes oradores que participan en la conversación. El servicio Voz proporciona información sobre qué hablante hablaba una parte determinada de la voz transcrita. Para obtener más información sobre la diarización del orador, consulta el inicio rápido de conversión de voz a texto en tiempo real con diarización del orador.
- Punto de conexión personalizado: use un modelo implementado a partir de voz personalizada para mejorar la precisión del reconocimiento. Para usar el modelo de línea de base de Microsoft, deje este valor en Ninguno. Para obtener más información sobre la voz personalizada, consulte Habla personalizada.
- Formato de salida: elija entre formatos de salida simples y detallados. La salida simple incluye formato de presentación y marcas de tiempo. La salida detallada incluye más formatos (como mostrar, léxico, ITN y ITN enmascarado), marcas de tiempo y N mejores listas.
- Lsta de frases: mejore la precisión de la transcripción proporcionando una lista de frases conocidas, como nombres de personas o ubicaciones específicas. Use comas o punto y coma para separar cada valor de la lista de frases. Para obtener más información sobre las listas de frases, consulte la Listas de frases.
Seleccione un archivo de audio para cargar o grabar audio en tiempo real. En este ejemplo, se usa el archivo
Call1_separated_16k_health_insurance.wavque está disponible en el repositorio del SDK de Voz en GitHub. Puede descargar el archivo o usar su propio archivo de audio.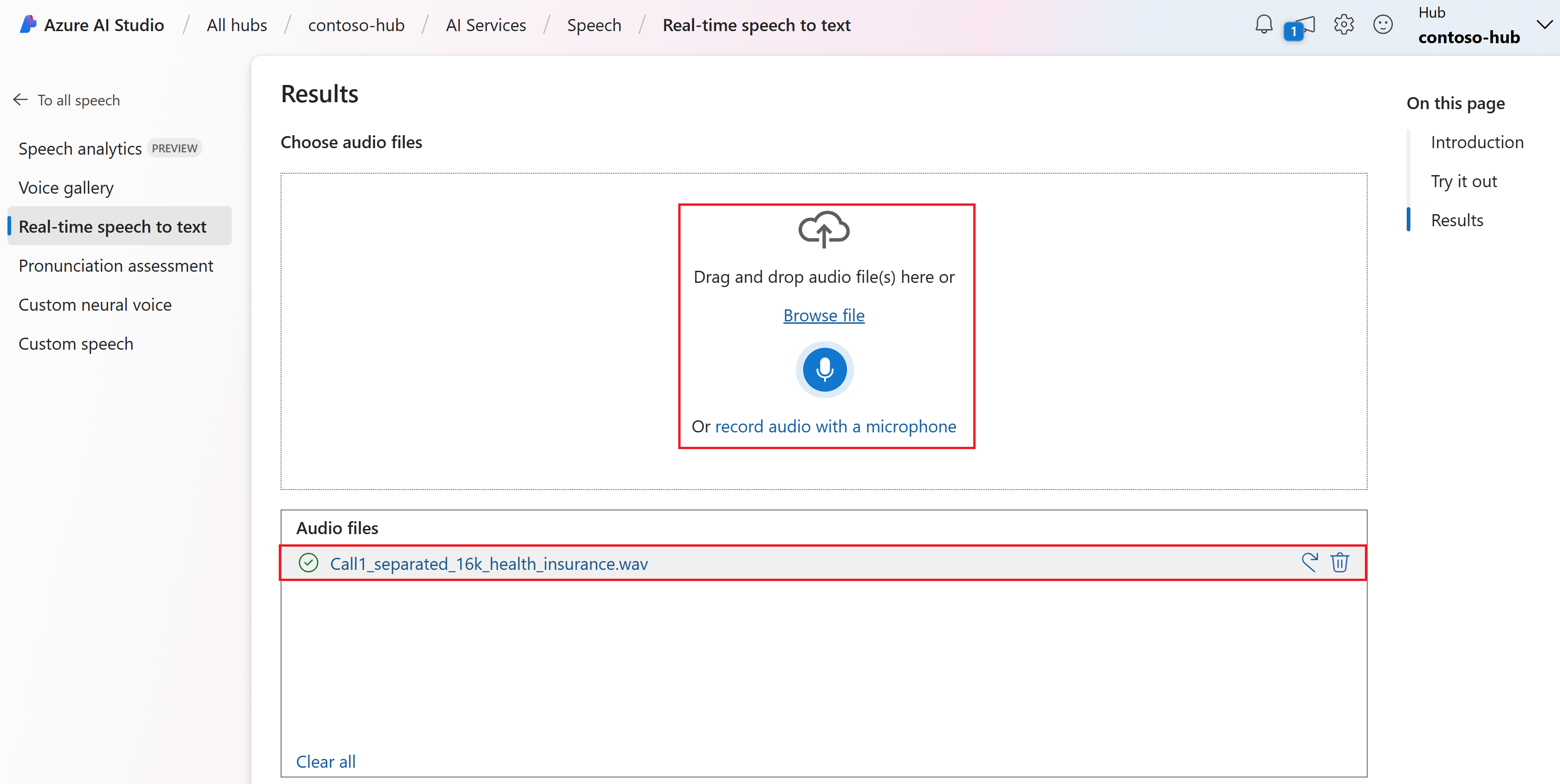
Puede ver la transcripción en tiempo real en la parte inferior de la página.
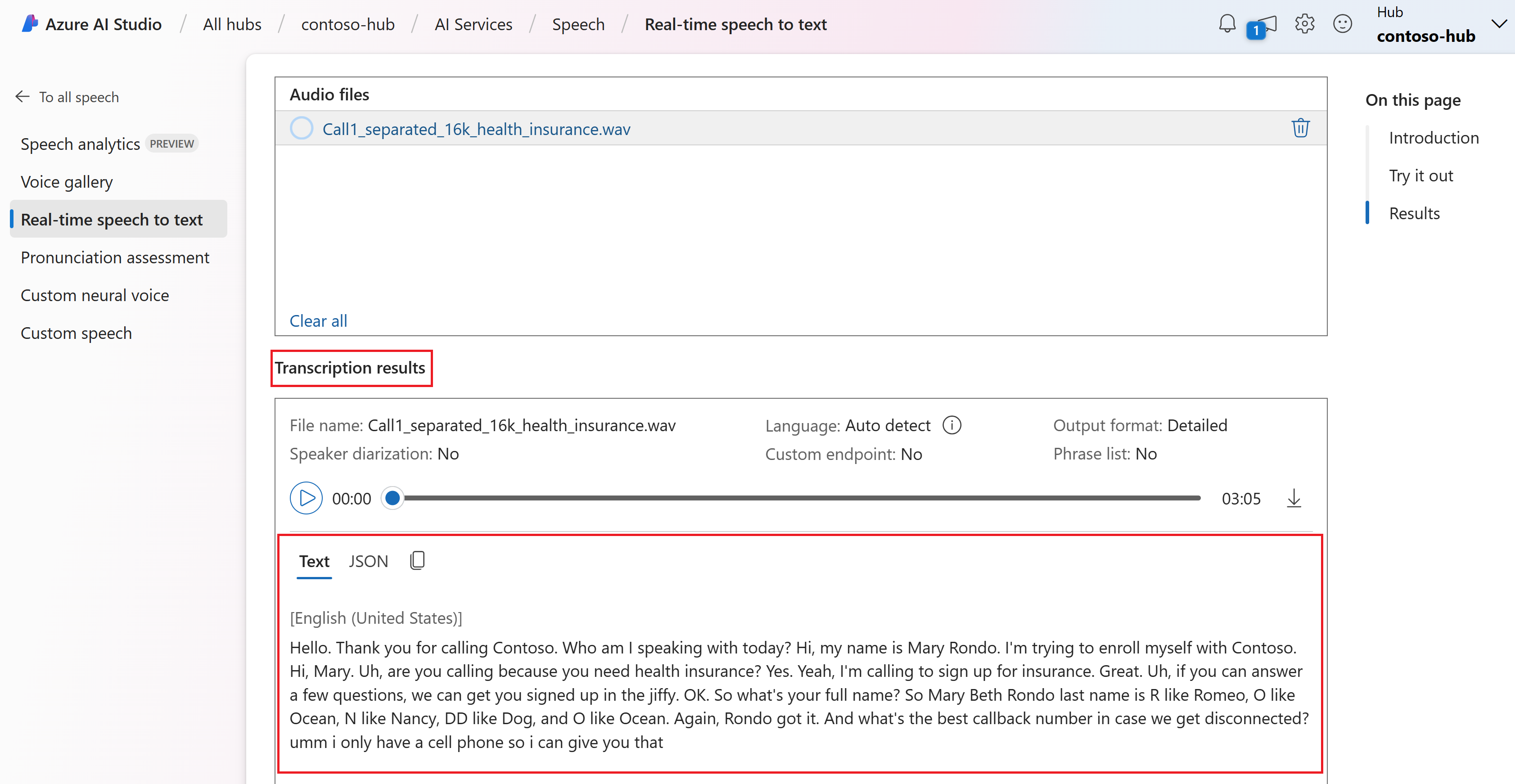
Puede seleccionar la pestaña JSON para ver la salida JSON de la transcripción. Estas propiedades incluyen
Offset,Duration,RecognitionStatus,Display,Lexical,ITN, etc.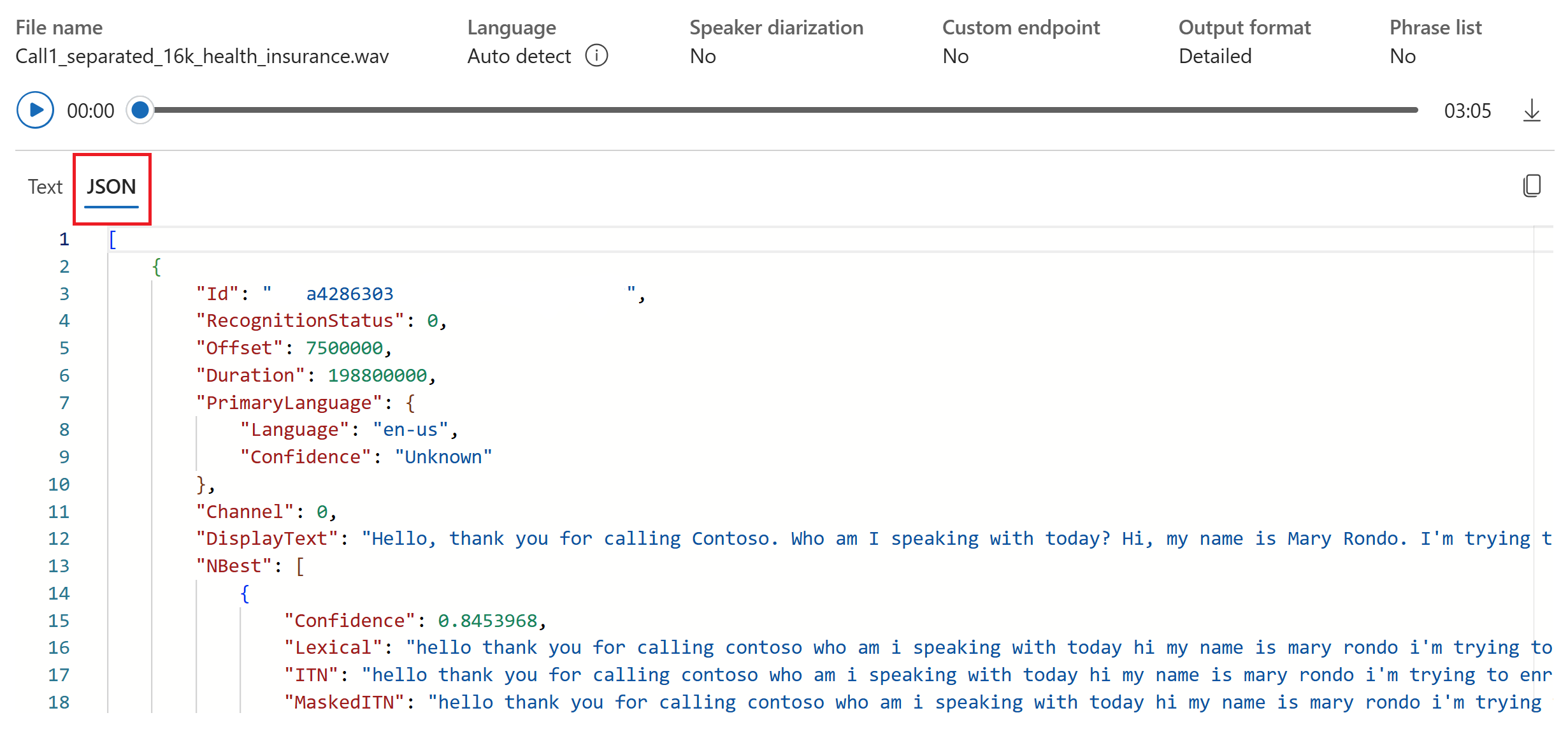





Documentación de referencia | Paquete (NuGet) | Ejemplos adicionales en GitHub
En este inicio rápido, creará y ejecutará una aplicación para reconocer y realizar la conversión de voz en texto en tiempo real.
En cambio, para transcribir archivos de audio de forma asincrónica, consulte Qué es la transcripción por lotes. Si no está seguro de qué solución de conversión de voz en texto es adecuada para usted, consulte¿Qué es la conversión de voz en texto?
Requisitos previos
- Suscripción a Azure. Puede crear una de forma gratuita.
- Creación de un recurso de Voz en Azure Portal.
- Obtenga la clave y la región del recurso de Voz. Una vez implementado el recurso de Voz, seleccione Ir al recurso para ver y administrar claves.
Configuración del entorno
El SDK de Voz está disponible como paquete NuGet e implementa .NET Standard 2.0. Instalará el SDK de Voz más adelante en esta guía. Para conocer los demás requisitos, consulte Instalación del SDK de Voz.
Establecimiento de variables de entorno
Debe autenticar la aplicación para acceder a los servicios de Azure AI. En este artículo se muestra cómo usar variables de entorno para almacenar las credenciales. A continuación, puede acceder a las variables de entorno desde el código para autenticar la aplicación. Para producción, use una manera más segura de almacenar y acceder a sus credenciales.
Importante
Se recomienda la autenticación de Microsoft Entra ID con identidades administradas para los recursos de Azure para evitar almacenar credenciales con sus aplicaciones que se ejecutan en la nube.
Si usa una clave de API, almacénela de forma segura en otro lugar, como en Azure Key Vault. No incluya la clave de API directamente en el código ni la exponga nunca públicamente.
Para más información sobre la seguridad de los servicios de AI, consulte Autenticación de solicitudes a los servicios de Azure AI.
Para establecer las variables de entorno de su clave de recursos de voz y de su región, abra una ventana de la consola y siga las instrucciones correspondientes a su sistema operativo y a su entorno de desarrollo.
- Para establecer la variable de entorno de
SPEECH_KEY, reemplace su clave por una de las claves del recurso. - Para establecer la variable de entorno de
SPEECH_REGION, reemplace su región por una de las regiones del recurso.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Nota:
Si solo necesita acceder a las variables de entorno en la consola actual, puede establecer la variable de entorno con set en vez de setx.
Después de agregar las variables de entorno, puede que tenga que reiniciar cualquier programa que necesite leer las variables de entorno, incluida la ventana de consola. Por ejemplo, si usa Visual Studio como editor, reinícielo antes de ejecutar el ejemplo.
Reconocimiento de voz a través de un micrófono
Sugerencia
Pruebe el Azure AI Speech Toolkit para compilar y ejecutar fácilmente ejemplos en Visual Studio Code.
Siga estos pasos para crear una aplicación de consola e instalar el SDK de Voz.
Abra una ventana del símbolo del sistema en la carpeta donde desee el nuevo proyecto. Ejecute este comando para crear una aplicación de consola con la CLI de .NET.
dotnet new consoleEste comando crea el archivo Program.cs en el directorio del proyecto.
Instale el SDK de Voz en el nuevo proyecto con la CLI de .NET.
dotnet add package Microsoft.CognitiveServices.SpeechReemplace el contenido de Program.cs por el código siguiente:
using System; using System.IO; using System.Threading.Tasks; using Microsoft.CognitiveServices.Speech; using Microsoft.CognitiveServices.Speech.Audio; class Program { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" static string speechKey = Environment.GetEnvironmentVariable("SPEECH_KEY"); static string speechRegion = Environment.GetEnvironmentVariable("SPEECH_REGION"); static void OutputSpeechRecognitionResult(SpeechRecognitionResult speechRecognitionResult) { switch (speechRecognitionResult.Reason) { case ResultReason.RecognizedSpeech: Console.WriteLine($"RECOGNIZED: Text={speechRecognitionResult.Text}"); break; case ResultReason.NoMatch: Console.WriteLine($"NOMATCH: Speech could not be recognized."); break; case ResultReason.Canceled: var cancellation = CancellationDetails.FromResult(speechRecognitionResult); Console.WriteLine($"CANCELED: Reason={cancellation.Reason}"); if (cancellation.Reason == CancellationReason.Error) { Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}"); Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}"); Console.WriteLine($"CANCELED: Did you set the speech resource key and region values?"); } break; } } async static Task Main(string[] args) { var speechConfig = SpeechConfig.FromSubscription(speechKey, speechRegion); speechConfig.SpeechRecognitionLanguage = "en-US"; using var audioConfig = AudioConfig.FromDefaultMicrophoneInput(); using var speechRecognizer = new SpeechRecognizer(speechConfig, audioConfig); Console.WriteLine("Speak into your microphone."); var speechRecognitionResult = await speechRecognizer.RecognizeOnceAsync(); OutputSpeechRecognitionResult(speechRecognitionResult); } }Para cambiar el idioma de reconocimiento de voz, reemplace
en-USpor otroen-US. Por ejemplo, usees-ESpara Español (España). Si no especifica un idioma, el valor predeterminado esen-US. Para más información sobre cómo identificar uno de los distintos idiomas que se pueden hablar, consulte Identificación del idioma.Ejecute la nueva aplicación de consola para iniciar el reconocimiento de voz a través de un micrófono:
dotnet runHable por el micrófono cuando se le solicite. Lo que diga debería aparecer como texto:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Comentarios
Estas son algunas otras consideraciones:
En este ejemplo se usa la operación
RecognizeOnceAsyncpara transcribir expresiones de hasta 30 segundos, o hasta que se detecta el silencio. Para obtener información sobre el reconocimiento continuo de audio más largo, incluidas las conversaciones en varios idiomas, consulte Reconocimiento de voz.Para reconocer la voz de un archivo de audio, use
FromWavFileInputen lugar deFromDefaultMicrophoneInput:using var audioConfig = AudioConfig.FromWavFileInput("YourAudioFile.wav");Para archivos de audio comprimidos como MP4, instale GStreamer y utilice
PullAudioInputStreamoPushAudioInputStream. Para más información, consulte Uso de entradas de audio comprimido.
Limpieza de recursos
Puede usar Azure Portal o la Interfaz de la línea de comandos (CLI) de Azure para quitar el recurso de Voz que creó.
Documentación de referencia | Paquete (NuGet) | Ejemplos adicionales en GitHub
En este inicio rápido, creará y ejecutará una aplicación para reconocer y realizar la conversión de voz en texto en tiempo real.
En cambio, para transcribir archivos de audio de forma asincrónica, consulte Qué es la transcripción por lotes. Si no está seguro de qué solución de conversión de voz en texto es adecuada para usted, consulte¿Qué es la conversión de voz en texto?
Requisitos previos
- Suscripción a Azure. Puede crear una de forma gratuita.
- Creación de un recurso de Voz en Azure Portal.
- Obtenga la clave y la región del recurso de Voz. Una vez implementado el recurso de Voz, seleccione Ir al recurso para ver y administrar claves.
Configuración del entorno
El SDK de Voz está disponible como paquete NuGet e implementa .NET Standard 2.0. Instalará el SDK de Voz más adelante en esta guía. Para conocer los demás requisitos, consulte Instalación del SDK de Voz.
Establecimiento de variables de entorno
Debe autenticar la aplicación para acceder a los servicios de Azure AI. En este artículo se muestra cómo usar variables de entorno para almacenar las credenciales. A continuación, puede acceder a las variables de entorno desde el código para autenticar la aplicación. Para producción, use una manera más segura de almacenar y acceder a sus credenciales.
Importante
Se recomienda la autenticación de Microsoft Entra ID con identidades administradas para los recursos de Azure para evitar almacenar credenciales con sus aplicaciones que se ejecutan en la nube.
Si usa una clave de API, almacénela de forma segura en otro lugar, como en Azure Key Vault. No incluya la clave de API directamente en el código ni la exponga nunca públicamente.
Para más información sobre la seguridad de los servicios de AI, consulte Autenticación de solicitudes a los servicios de Azure AI.
Para establecer las variables de entorno de su clave de recursos de voz y de su región, abra una ventana de la consola y siga las instrucciones correspondientes a su sistema operativo y a su entorno de desarrollo.
- Para establecer la variable de entorno de
SPEECH_KEY, reemplace su clave por una de las claves del recurso. - Para establecer la variable de entorno de
SPEECH_REGION, reemplace su región por una de las regiones del recurso.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Nota:
Si solo necesita acceder a las variables de entorno en la consola actual, puede establecer la variable de entorno con set en vez de setx.
Después de agregar las variables de entorno, puede que tenga que reiniciar cualquier programa que necesite leer las variables de entorno, incluida la ventana de consola. Por ejemplo, si usa Visual Studio como editor, reinícielo antes de ejecutar el ejemplo.
Reconocimiento de voz a través de un micrófono
Sugerencia
Pruebe el Azure AI Speech Toolkit para compilar y ejecutar fácilmente ejemplos en Visual Studio Code.
Siga estos pasos para crear una aplicación de consola e instalar el SDK de Voz.
Cree un proyecto de consola de C++ en Visual Studio Community denominado
SpeechRecognition.Seleccione Herramientas>Administrador de paquetes Nuget>Consola del Administrador de paquetes. En la consola del administrador de paquetes, ejecute este comando:
Install-Package Microsoft.CognitiveServices.SpeechReemplace el contenido de
SpeechRecognition.cpppor el código siguiente:#include <iostream> #include <stdlib.h> #include <speechapi_cxx.h> using namespace Microsoft::CognitiveServices::Speech; using namespace Microsoft::CognitiveServices::Speech::Audio; std::string GetEnvironmentVariable(const char* name); int main() { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" auto speechKey = GetEnvironmentVariable("SPEECH_KEY"); auto speechRegion = GetEnvironmentVariable("SPEECH_REGION"); if ((size(speechKey) == 0) || (size(speechRegion) == 0)) { std::cout << "Please set both SPEECH_KEY and SPEECH_REGION environment variables." << std::endl; return -1; } auto speechConfig = SpeechConfig::FromSubscription(speechKey, speechRegion); speechConfig->SetSpeechRecognitionLanguage("en-US"); auto audioConfig = AudioConfig::FromDefaultMicrophoneInput(); auto speechRecognizer = SpeechRecognizer::FromConfig(speechConfig, audioConfig); std::cout << "Speak into your microphone.\n"; auto result = speechRecognizer->RecognizeOnceAsync().get(); if (result->Reason == ResultReason::RecognizedSpeech) { std::cout << "RECOGNIZED: Text=" << result->Text << std::endl; } else if (result->Reason == ResultReason::NoMatch) { std::cout << "NOMATCH: Speech could not be recognized." << std::endl; } else if (result->Reason == ResultReason::Canceled) { auto cancellation = CancellationDetails::FromResult(result); std::cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl; if (cancellation->Reason == CancellationReason::Error) { std::cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl; std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl; std::cout << "CANCELED: Did you set the speech resource key and region values?" << std::endl; } } } std::string GetEnvironmentVariable(const char* name) { #if defined(_MSC_VER) size_t requiredSize = 0; (void)getenv_s(&requiredSize, nullptr, 0, name); if (requiredSize == 0) { return ""; } auto buffer = std::make_unique<char[]>(requiredSize); (void)getenv_s(&requiredSize, buffer.get(), requiredSize, name); return buffer.get(); #else auto value = getenv(name); return value ? value : ""; #endif }Para cambiar el idioma de reconocimiento de voz, reemplace
en-USpor otroen-US. Por ejemplo, usees-ESpara Español (España). Si no especifica un idioma, el valor predeterminado esen-US. Para más información sobre cómo identificar uno de los distintos idiomas que se pueden hablar, consulte Identificación del idioma.Compile y ejecute la nueva aplicación de consola para iniciar el reconocimiento de voz a través de un micrófono.
Hable por el micrófono cuando se le solicite. Lo que diga debería aparecer como texto:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Comentarios
Estas son algunas otras consideraciones:
En este ejemplo se usa la operación
RecognizeOnceAsyncpara transcribir expresiones de hasta 30 segundos, o hasta que se detecta el silencio. Para obtener información sobre el reconocimiento continuo de audio más largo, incluidas las conversaciones en varios idiomas, consulte Reconocimiento de voz.Para reconocer la voz de un archivo de audio, use
FromWavFileInputen lugar deFromDefaultMicrophoneInput:auto audioConfig = AudioConfig::FromWavFileInput("YourAudioFile.wav");Para archivos de audio comprimidos como MP4, instale GStreamer y utilice
PullAudioInputStreamoPushAudioInputStream. Para más información, consulte Uso de entradas de audio comprimido.
Limpieza de recursos
Puede usar Azure Portal o la Interfaz de la línea de comandos (CLI) de Azure para quitar el recurso de Voz que creó.
Documentación de referencia | Paquete (Go) | Ejemplos adicionales en GitHub
En este inicio rápido, creará y ejecutará una aplicación para reconocer y realizar la conversión de voz en texto en tiempo real.
En cambio, para transcribir archivos de audio de forma asincrónica, consulte Qué es la transcripción por lotes. Si no está seguro de qué solución de conversión de voz en texto es adecuada para usted, consulte¿Qué es la conversión de voz en texto?
Requisitos previos
- Suscripción a Azure. Puede crear una de forma gratuita.
- Creación de un recurso de Voz en Azure Portal.
- Obtenga la clave y la región del recurso de Voz. Una vez implementado el recurso de Voz, seleccione Ir al recurso para ver y administrar claves.
Configuración del entorno
Instale el SDK de Voz para Go. Para conocer los requisitos e instrucciones, consulte Instalación del SDK de Voz.
Establecimiento de variables de entorno
Debe autenticar la aplicación para acceder a los servicios de Azure AI. En este artículo se muestra cómo usar variables de entorno para almacenar las credenciales. A continuación, puede acceder a las variables de entorno desde el código para autenticar la aplicación. Para producción, use una manera más segura de almacenar y acceder a sus credenciales.
Importante
Se recomienda la autenticación de Microsoft Entra ID con identidades administradas para los recursos de Azure para evitar almacenar credenciales con sus aplicaciones que se ejecutan en la nube.
Si usa una clave de API, almacénela de forma segura en otro lugar, como en Azure Key Vault. No incluya la clave de API directamente en el código ni la exponga nunca públicamente.
Para más información sobre la seguridad de los servicios de AI, consulte Autenticación de solicitudes a los servicios de Azure AI.
Para establecer las variables de entorno de su clave de recursos de voz y de su región, abra una ventana de la consola y siga las instrucciones correspondientes a su sistema operativo y a su entorno de desarrollo.
- Para establecer la variable de entorno de
SPEECH_KEY, reemplace su clave por una de las claves del recurso. - Para establecer la variable de entorno de
SPEECH_REGION, reemplace su región por una de las regiones del recurso.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Nota:
Si solo necesita acceder a las variables de entorno en la consola actual, puede establecer la variable de entorno con set en vez de setx.
Después de agregar las variables de entorno, puede que tenga que reiniciar cualquier programa que necesite leer las variables de entorno, incluida la ventana de consola. Por ejemplo, si usa Visual Studio como editor, reinícielo antes de ejecutar el ejemplo.
Reconocimiento de voz a través de un micrófono
Siga estos pasos para crear un módulo de Go.
Abra una ventana del símbolo del sistema en la carpeta donde desee el nuevo proyecto. Cree un nuevo archivo denominado speech-recognition.go.
Copie el siguiente código en speech-recognition.go:
package main import ( "bufio" "fmt" "os" "github.com/Microsoft/cognitive-services-speech-sdk-go/audio" "github.com/Microsoft/cognitive-services-speech-sdk-go/speech" ) func sessionStartedHandler(event speech.SessionEventArgs) { defer event.Close() fmt.Println("Session Started (ID=", event.SessionID, ")") } func sessionStoppedHandler(event speech.SessionEventArgs) { defer event.Close() fmt.Println("Session Stopped (ID=", event.SessionID, ")") } func recognizingHandler(event speech.SpeechRecognitionEventArgs) { defer event.Close() fmt.Println("Recognizing:", event.Result.Text) } func recognizedHandler(event speech.SpeechRecognitionEventArgs) { defer event.Close() fmt.Println("Recognized:", event.Result.Text) } func cancelledHandler(event speech.SpeechRecognitionCanceledEventArgs) { defer event.Close() fmt.Println("Received a cancellation: ", event.ErrorDetails) fmt.Println("Did you set the speech resource key and region values?") } func main() { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" speechKey := os.Getenv("SPEECH_KEY") speechRegion := os.Getenv("SPEECH_REGION") audioConfig, err := audio.NewAudioConfigFromDefaultMicrophoneInput() if err != nil { fmt.Println("Got an error: ", err) return } defer audioConfig.Close() speechConfig, err := speech.NewSpeechConfigFromSubscription(speechKey, speechRegion) if err != nil { fmt.Println("Got an error: ", err) return } defer speechConfig.Close() speechRecognizer, err := speech.NewSpeechRecognizerFromConfig(speechConfig, audioConfig) if err != nil { fmt.Println("Got an error: ", err) return } defer speechRecognizer.Close() speechRecognizer.SessionStarted(sessionStartedHandler) speechRecognizer.SessionStopped(sessionStoppedHandler) speechRecognizer.Recognizing(recognizingHandler) speechRecognizer.Recognized(recognizedHandler) speechRecognizer.Canceled(cancelledHandler) speechRecognizer.StartContinuousRecognitionAsync() defer speechRecognizer.StopContinuousRecognitionAsync() bufio.NewReader(os.Stdin).ReadBytes('\n') }Ejecute los comandos siguientes para crear un archivo go.mod que vincule a los componentes hospedados en GitHub:
go mod init speech-recognition go get github.com/Microsoft/cognitive-services-speech-sdk-goCompilación y ejecución del código
go build go run speech-recognition
Limpieza de recursos
Puede usar Azure Portal o la Interfaz de la línea de comandos (CLI) de Azure para quitar el recurso de Voz que creó.
Documentación de referencia | Ejemplos adicionales en GitHub
En este inicio rápido, creará y ejecutará una aplicación para reconocer y realizar la conversión de voz en texto en tiempo real.
En cambio, para transcribir archivos de audio de forma asincrónica, consulte Qué es la transcripción por lotes. Si no está seguro de qué solución de conversión de voz en texto es adecuada para usted, consulte¿Qué es la conversión de voz en texto?
Requisitos previos
- Suscripción a Azure. Puede crear una de forma gratuita.
- Creación de un recurso de Voz en Azure Portal.
- Obtenga la clave y la región del recurso de Voz. Una vez implementado el recurso de Voz, seleccione Ir al recurso para ver y administrar claves.
Configuración del entorno
Para configurar el entorno, instale el SDK de Voz. El ejemplo de esta guía de inicio rápido funciona con el entorno de ejecución de Java.
Instalación de Apache Maven. A continuación, ejecute
mvn -vpara confirmar que la instalación se ha realizado correctamente.Cree un nuevo archivo
pom.xmlen la raíz del proyecto y copie el siguiente código en él:<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.microsoft.cognitiveservices.speech.samples</groupId> <artifactId>quickstart-eclipse</artifactId> <version>1.0.0-SNAPSHOT</version> <build> <sourceDirectory>src</sourceDirectory> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.7.0</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> </plugins> </build> <dependencies> <dependency> <groupId>com.microsoft.cognitiveservices.speech</groupId> <artifactId>client-sdk</artifactId> <version>1.42.0</version> </dependency> </dependencies> </project>Instale el SDK de Voz y las dependencias.
mvn clean dependency:copy-dependencies
Establecimiento de variables de entorno
Debe autenticar la aplicación para acceder a los servicios de Azure AI. En este artículo se muestra cómo usar variables de entorno para almacenar las credenciales. A continuación, puede acceder a las variables de entorno desde el código para autenticar la aplicación. Para producción, use una manera más segura de almacenar y acceder a sus credenciales.
Importante
Se recomienda la autenticación de Microsoft Entra ID con identidades administradas para los recursos de Azure para evitar almacenar credenciales con sus aplicaciones que se ejecutan en la nube.
Si usa una clave de API, almacénela de forma segura en otro lugar, como en Azure Key Vault. No incluya la clave de API directamente en el código ni la exponga nunca públicamente.
Para más información sobre la seguridad de los servicios de AI, consulte Autenticación de solicitudes a los servicios de Azure AI.
Para establecer las variables de entorno de su clave de recursos de voz y de su región, abra una ventana de la consola y siga las instrucciones correspondientes a su sistema operativo y a su entorno de desarrollo.
- Para establecer la variable de entorno de
SPEECH_KEY, reemplace su clave por una de las claves del recurso. - Para establecer la variable de entorno de
SPEECH_REGION, reemplace su región por una de las regiones del recurso.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Nota:
Si solo necesita acceder a las variables de entorno en la consola actual, puede establecer la variable de entorno con set en vez de setx.
Después de agregar las variables de entorno, puede que tenga que reiniciar cualquier programa que necesite leer las variables de entorno, incluida la ventana de consola. Por ejemplo, si usa Visual Studio como editor, reinícielo antes de ejecutar el ejemplo.
Reconocimiento de voz a través de un micrófono
Siga estos pasos para crear una aplicación de consola para el reconocimiento de voz.
Cree un nuevo archivo denominado SpeechRecognition.java en el mismo directorio raíz del proyecto.
Copie el siguiente código en SpeechRecognition.java:
import com.microsoft.cognitiveservices.speech.*; import com.microsoft.cognitiveservices.speech.audio.AudioConfig; import java.util.concurrent.ExecutionException; import java.util.concurrent.Future; public class SpeechRecognition { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" private static String speechKey = System.getenv("SPEECH_KEY"); private static String speechRegion = System.getenv("SPEECH_REGION"); public static void main(String[] args) throws InterruptedException, ExecutionException { SpeechConfig speechConfig = SpeechConfig.fromSubscription(speechKey, speechRegion); speechConfig.setSpeechRecognitionLanguage("en-US"); recognizeFromMicrophone(speechConfig); } public static void recognizeFromMicrophone(SpeechConfig speechConfig) throws InterruptedException, ExecutionException { AudioConfig audioConfig = AudioConfig.fromDefaultMicrophoneInput(); SpeechRecognizer speechRecognizer = new SpeechRecognizer(speechConfig, audioConfig); System.out.println("Speak into your microphone."); Future<SpeechRecognitionResult> task = speechRecognizer.recognizeOnceAsync(); SpeechRecognitionResult speechRecognitionResult = task.get(); if (speechRecognitionResult.getReason() == ResultReason.RecognizedSpeech) { System.out.println("RECOGNIZED: Text=" + speechRecognitionResult.getText()); } else if (speechRecognitionResult.getReason() == ResultReason.NoMatch) { System.out.println("NOMATCH: Speech could not be recognized."); } else if (speechRecognitionResult.getReason() == ResultReason.Canceled) { CancellationDetails cancellation = CancellationDetails.fromResult(speechRecognitionResult); System.out.println("CANCELED: Reason=" + cancellation.getReason()); if (cancellation.getReason() == CancellationReason.Error) { System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode()); System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails()); System.out.println("CANCELED: Did you set the speech resource key and region values?"); } } System.exit(0); } }Para cambiar el idioma de reconocimiento de voz, reemplace
en-USpor otroen-US. Por ejemplo, usees-ESpara Español (España). Si no especifica un idioma, el valor predeterminado esen-US. Para más información sobre cómo identificar uno de los distintos idiomas que se pueden hablar, consulte Identificación del idioma.Ejecute la nueva aplicación de consola para iniciar el reconocimiento de voz a través de un micrófono:
javac SpeechRecognition.java -cp ".;target\dependency\*" java -cp ".;target\dependency\*" SpeechRecognitionHable por el micrófono cuando se le solicite. Lo que diga debería aparecer como texto:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Comentarios
Estas son algunas otras consideraciones:
En este ejemplo se usa la operación
RecognizeOnceAsyncpara transcribir expresiones de hasta 30 segundos, o hasta que se detecta el silencio. Para obtener información sobre el reconocimiento continuo de audio más largo, incluidas las conversaciones en varios idiomas, consulte Reconocimiento de voz.Para reconocer la voz de un archivo de audio, use
fromWavFileInputen lugar defromDefaultMicrophoneInput:AudioConfig audioConfig = AudioConfig.fromWavFileInput("YourAudioFile.wav");Para archivos de audio comprimidos como MP4, instale GStreamer y utilice
PullAudioInputStreamoPushAudioInputStream. Para más información, consulte Uso de entradas de audio comprimido.
Limpieza de recursos
Puede usar Azure Portal o la Interfaz de la línea de comandos (CLI) de Azure para quitar el recurso de Voz que creó.
Documentación de referencia | Paquete (npm) | Ejemplos adicionales en GitHub | Código fuente de la biblioteca
En este inicio rápido, creará y ejecutará una aplicación para reconocer y realizar la conversión de voz en texto en tiempo real.
En cambio, para transcribir archivos de audio de forma asincrónica, consulte Qué es la transcripción por lotes. Si no está seguro de qué solución de conversión de voz en texto es adecuada para usted, consulte¿Qué es la conversión de voz en texto?
Requisitos previos
- Suscripción a Azure. Puede crear una de forma gratuita.
- Creación de un recurso de Voz en Azure Portal.
- Obtenga la clave y la región del recurso de Voz. Una vez implementado el recurso de Voz, seleccione Ir al recurso para ver y administrar claves.
También necesita un archivo de audio .wav en el equipo local. Puede usar su propio archivo .wav (hasta 30 segundos) o descargar el archivo de ejemplo https://crbn.us/whatstheweatherlike.wav.
Configuración del entorno
Para configurar el entorno, instale el SDK de Voz para JavaScript. Ejecuta este comando: npm install microsoft-cognitiveservices-speech-sdk. Para obtener instrucciones de instalación guiadas, consulte Instalación del SDK de Voz.
Establecimiento de variables de entorno
Debe autenticar la aplicación para acceder a los servicios de Azure AI. En este artículo se muestra cómo usar variables de entorno para almacenar las credenciales. A continuación, puede acceder a las variables de entorno desde el código para autenticar la aplicación. Para producción, use una manera más segura de almacenar y acceder a sus credenciales.
Importante
Se recomienda la autenticación de Microsoft Entra ID con identidades administradas para los recursos de Azure para evitar almacenar credenciales con sus aplicaciones que se ejecutan en la nube.
Si usa una clave de API, almacénela de forma segura en otro lugar, como en Azure Key Vault. No incluya la clave de API directamente en el código ni la exponga nunca públicamente.
Para más información sobre la seguridad de los servicios de AI, consulte Autenticación de solicitudes a los servicios de Azure AI.
Para establecer las variables de entorno de su clave de recursos de voz y de su región, abra una ventana de la consola y siga las instrucciones correspondientes a su sistema operativo y a su entorno de desarrollo.
- Para establecer la variable de entorno de
SPEECH_KEY, reemplace su clave por una de las claves del recurso. - Para establecer la variable de entorno de
SPEECH_REGION, reemplace su región por una de las regiones del recurso.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Nota:
Si solo necesita acceder a las variables de entorno en la consola actual, puede establecer la variable de entorno con set en vez de setx.
Después de agregar las variables de entorno, puede que tenga que reiniciar cualquier programa que necesite leer las variables de entorno, incluida la ventana de consola. Por ejemplo, si usa Visual Studio como editor, reinícielo antes de ejecutar el ejemplo.
Reconocer la voz a partir de un archivo
Sugerencia
Pruebe el Azure AI Speech Toolkit para compilar y ejecutar fácilmente ejemplos en Visual Studio Code.
Siga estos pasos para crear una aplicación de consola de Node.js para el reconocimiento de voz.
Abra una ventana del símbolo del sistema donde quiera el nuevo proyecto y cree un archivo llamado SpeechRecognition.js.
Instale el SDK de voz para JavaScript:
npm install microsoft-cognitiveservices-speech-sdkCopie el siguiente código en SpeechRecognition.js:
const fs = require("fs"); const sdk = require("microsoft-cognitiveservices-speech-sdk"); // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" const speechConfig = sdk.SpeechConfig.fromSubscription(process.env.SPEECH_KEY, process.env.SPEECH_REGION); speechConfig.speechRecognitionLanguage = "en-US"; function fromFile() { let audioConfig = sdk.AudioConfig.fromWavFileInput(fs.readFileSync("YourAudioFile.wav")); let speechRecognizer = new sdk.SpeechRecognizer(speechConfig, audioConfig); speechRecognizer.recognizeOnceAsync(result => { switch (result.reason) { case sdk.ResultReason.RecognizedSpeech: console.log(`RECOGNIZED: Text=${result.text}`); break; case sdk.ResultReason.NoMatch: console.log("NOMATCH: Speech could not be recognized."); break; case sdk.ResultReason.Canceled: const cancellation = sdk.CancellationDetails.fromResult(result); console.log(`CANCELED: Reason=${cancellation.reason}`); if (cancellation.reason == sdk.CancellationReason.Error) { console.log(`CANCELED: ErrorCode=${cancellation.ErrorCode}`); console.log(`CANCELED: ErrorDetails=${cancellation.errorDetails}`); console.log("CANCELED: Did you set the speech resource key and region values?"); } break; } speechRecognizer.close(); }); } fromFile();En SpeechRecognition.js, reemplace YourAudioFile.wav por su propio archivo .wav. En este ejemplo solo se reconoce la voz desde un archivo.wav. Para obtener información sobre otros formatos de audio, consulte Uso de entradas de audio comprimidas. Este ejemplo admite hasta 30 segundos de audio.
Para cambiar el idioma de reconocimiento de voz, reemplace
en-USpor otroen-US. Por ejemplo, usees-ESpara Español (España). Si no especifica un idioma, el valor predeterminado esen-US. Para más información sobre cómo identificar uno de los distintos idiomas que se pueden hablar, consulte Identificación del idioma.Ejecute la nueva aplicación de consola para iniciar el reconocimiento de voz desde un archivo:
node.exe SpeechRecognition.jsImportante
Asegúrese de establecer las variables de entorno
SPEECH_KEYySPEECH_REGION. Si no establece estas variables, se produce un fallo en el ejemplo, con un mensaje de error.La voz del archivo de audio debe devolverse como texto:
RECOGNIZED: Text=I'm excited to try speech to text.
Comentarios
En este ejemplo se usa la operación recognizeOnceAsync para transcribir expresiones de hasta 30 segundos, o hasta que se detecta el silencio. Para obtener información sobre el reconocimiento continuo de audio más largo, incluidas las conversaciones en varios idiomas, consulte Reconocimiento de voz.
Nota:
No se admite el reconocimiento de voz a través de un micrófono en Node.js. Solo se admite en un entorno de JavaScript basado en explorador. Para obtener más información, consulte el ejemplo de React y la implementación de la conversión de voz en texto a través de un micrófono en GitHub.
En el ejemplo de React se muestran patrones de diseño para el intercambio y la administración de tokens de autenticación. También se muestra la captura de audio desde un micrófono o un archivo para realizar conversiones de voz en texto.
Limpieza de recursos
Puede usar Azure Portal o la Interfaz de la línea de comandos (CLI) de Azure para quitar el recurso de Voz que creó.
Documentación de referencia | Paquete (PyPi) | Ejemplos adicionales en GitHub
En este inicio rápido, creará y ejecutará una aplicación para reconocer y realizar la conversión de voz en texto en tiempo real.
En cambio, para transcribir archivos de audio de forma asincrónica, consulte Qué es la transcripción por lotes. Si no está seguro de qué solución de conversión de voz en texto es adecuada para usted, consulte¿Qué es la conversión de voz en texto?
Requisitos previos
- Suscripción a Azure. Puede crear una de forma gratuita.
- Creación de un recurso de Voz en Azure Portal.
- Obtenga la clave y la región del recurso de Voz. Una vez implementado el recurso de Voz, seleccione Ir al recurso para ver y administrar claves.
Configuración del entorno
El SDK de Voz para Python está disponible como módulo de índice de paquetes de Python (PyPI). El SDK de Voz para Python es compatible con Windows, Linux y macOS.
- Para Windows, instale Microsoft Visual C++ Redistributable para Visual Studio 2015, 2017, 2019 y 2022 para su plataforma. Durante la primera instalación del paquete, es posible que deba reiniciar.
- En Linux, debe usar la arquitectura de destino x64.
Instale una versión de Python desde la 3.7 en adelante. Para conocer los demás requisitos, consulte Instalación del SDK de Voz.
Establecimiento de variables de entorno
Debe autenticar la aplicación para acceder a los servicios de Azure AI. En este artículo se muestra cómo usar variables de entorno para almacenar las credenciales. A continuación, puede acceder a las variables de entorno desde el código para autenticar la aplicación. Para producción, use una manera más segura de almacenar y acceder a sus credenciales.
Importante
Se recomienda la autenticación de Microsoft Entra ID con identidades administradas para los recursos de Azure para evitar almacenar credenciales con sus aplicaciones que se ejecutan en la nube.
Si usa una clave de API, almacénela de forma segura en otro lugar, como en Azure Key Vault. No incluya la clave de API directamente en el código ni la exponga nunca públicamente.
Para más información sobre la seguridad de los servicios de AI, consulte Autenticación de solicitudes a los servicios de Azure AI.
Para establecer las variables de entorno de su clave de recursos de voz y de su región, abra una ventana de la consola y siga las instrucciones correspondientes a su sistema operativo y a su entorno de desarrollo.
- Para establecer la variable de entorno de
SPEECH_KEY, reemplace su clave por una de las claves del recurso. - Para establecer la variable de entorno de
SPEECH_REGION, reemplace su región por una de las regiones del recurso.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Nota:
Si solo necesita acceder a las variables de entorno en la consola actual, puede establecer la variable de entorno con set en vez de setx.
Después de agregar las variables de entorno, puede que tenga que reiniciar cualquier programa que necesite leer las variables de entorno, incluida la ventana de consola. Por ejemplo, si usa Visual Studio como editor, reinícielo antes de ejecutar el ejemplo.
Reconocimiento de voz a través de un micrófono
Sugerencia
Pruebe el Azure AI Speech Toolkit para compilar y ejecutar fácilmente ejemplos en Visual Studio Code.
Siga estos pasos para crear una aplicación de consola.
Abra una ventana del símbolo del sistema en la carpeta donde desee el nuevo proyecto. Cree un nuevo archivo denominado speech_recognition.py.
Ejecute este comando para instalar el SDK de voz:
pip install azure-cognitiveservices-speechCopie el siguiente código en speech_recognition.py:
import os import azure.cognitiveservices.speech as speechsdk def recognize_from_microphone(): # This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" speech_config = speechsdk.SpeechConfig(subscription=os.environ.get('SPEECH_KEY'), region=os.environ.get('SPEECH_REGION')) speech_config.speech_recognition_language="en-US" audio_config = speechsdk.audio.AudioConfig(use_default_microphone=True) speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config) print("Speak into your microphone.") speech_recognition_result = speech_recognizer.recognize_once_async().get() if speech_recognition_result.reason == speechsdk.ResultReason.RecognizedSpeech: print("Recognized: {}".format(speech_recognition_result.text)) elif speech_recognition_result.reason == speechsdk.ResultReason.NoMatch: print("No speech could be recognized: {}".format(speech_recognition_result.no_match_details)) elif speech_recognition_result.reason == speechsdk.ResultReason.Canceled: cancellation_details = speech_recognition_result.cancellation_details print("Speech Recognition canceled: {}".format(cancellation_details.reason)) if cancellation_details.reason == speechsdk.CancellationReason.Error: print("Error details: {}".format(cancellation_details.error_details)) print("Did you set the speech resource key and region values?") recognize_from_microphone()Para cambiar el idioma de reconocimiento de voz, reemplace
en-USpor otroen-US. Por ejemplo, usees-ESpara Español (España). Si no especifica un idioma, el valor predeterminado esen-US. Para obtener más información sobre cómo identificar uno de los distintos idiomas que se pueden hablar, consulte Identificación del idioma.Ejecute la nueva aplicación de consola para iniciar el reconocimiento de voz a través de un micrófono:
python speech_recognition.pyHable por el micrófono cuando se le solicite. Lo que diga debería aparecer como texto:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Comentarios
Estas son algunas otras consideraciones:
En este ejemplo se usa la operación
recognize_once_asyncpara transcribir expresiones de hasta 30 segundos, o hasta que se detecta el silencio. Para obtener información sobre el reconocimiento continuo de audio más largo, incluidas las conversaciones en varios idiomas, consulte Reconocimiento de voz.Para reconocer la voz de un archivo de audio, use
filenameen lugar deuse_default_microphone:audio_config = speechsdk.audio.AudioConfig(filename="YourAudioFile.wav")Para archivos de audio comprimidos como MP4, instale GStreamer y utilice
PullAudioInputStreamoPushAudioInputStream. Para más información, consulte Uso de entradas de audio comprimido.
Limpieza de recursos
Puede usar Azure Portal o la Interfaz de la línea de comandos (CLI) de Azure para quitar el recurso de Voz que creó.
Documentación de referencia | Paquete (descarga) | Ejemplos adicionales en GitHub
En este inicio rápido, creará y ejecutará una aplicación para reconocer y realizar la conversión de voz en texto en tiempo real.
En cambio, para transcribir archivos de audio de forma asincrónica, consulte Qué es la transcripción por lotes. Si no está seguro de qué solución de conversión de voz en texto es adecuada para usted, consulte¿Qué es la conversión de voz en texto?
Requisitos previos
- Suscripción a Azure. Puede crear una de forma gratuita.
- Creación de un recurso de Voz en Azure Portal.
- Obtenga la clave y la región del recurso de Voz. Una vez implementado el recurso de Voz, seleccione Ir al recurso para ver y administrar claves.
Configuración del entorno
El SDK de Voz para Swift se distribuye como un paquete de marcos. El marco admite Objective-C y Swift en iOS y macOS.
El SDK de Voz se puede usar en proyectos de Xcode como CocoaPod o se puede descargar directamente y vincular manualmente. En esta guía se usa CocoaPod. Instale el administrador de dependencias de CocoaPod como se describe en sus instrucciones de instalación.
Establecimiento de variables de entorno
Debe autenticar la aplicación para acceder a los servicios de Azure AI. En este artículo se muestra cómo usar variables de entorno para almacenar las credenciales. A continuación, puede acceder a las variables de entorno desde el código para autenticar la aplicación. Para producción, use una manera más segura de almacenar y acceder a sus credenciales.
Importante
Se recomienda la autenticación de Microsoft Entra ID con identidades administradas para los recursos de Azure para evitar almacenar credenciales con sus aplicaciones que se ejecutan en la nube.
Si usa una clave de API, almacénela de forma segura en otro lugar, como en Azure Key Vault. No incluya la clave de API directamente en el código ni la exponga nunca públicamente.
Para más información sobre la seguridad de los servicios de AI, consulte Autenticación de solicitudes a los servicios de Azure AI.
Para establecer las variables de entorno de su clave de recursos de voz y de su región, abra una ventana de la consola y siga las instrucciones correspondientes a su sistema operativo y a su entorno de desarrollo.
- Para establecer la variable de entorno de
SPEECH_KEY, reemplace su clave por una de las claves del recurso. - Para establecer la variable de entorno de
SPEECH_REGION, reemplace su región por una de las regiones del recurso.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Nota:
Si solo necesita acceder a las variables de entorno en la consola actual, puede establecer la variable de entorno con set en vez de setx.
Después de agregar las variables de entorno, puede que tenga que reiniciar cualquier programa que necesite leer las variables de entorno, incluida la ventana de consola. Por ejemplo, si usa Visual Studio como editor, reinícielo antes de ejecutar el ejemplo.
Reconocimiento de voz a través de un micrófono
Siga estos pasos para reconocer la voz en una aplicación de macOS.
Clone el repositorio Azure-Samples/cognitive-services-speech-sdk para obtener el proyecto de ejemplo Reconocimiento de voz desde un micrófono en Swift en macOS. El repositorio también tiene ejemplos de iOS.
Vaya al directorio de la aplicación de ejemplo descargada (
helloworld) en un terminal.Ejecute el comando
pod install. Este comando genera un área de trabajo de Xcodehelloworld.xcworkspaceque contiene la aplicación de ejemplo y el SDK de Voz como dependencia.Abra el área de trabajo
helloworld.xcworkspaceen Xcode.Abra el archivo llamado AppDelegate.swift y busque los métodos
applicationDidFinishLaunchingyrecognizeFromMictal como se muestra aquí.import Cocoa @NSApplicationMain class AppDelegate: NSObject, NSApplicationDelegate { var label: NSTextField! var fromMicButton: NSButton! var sub: String! var region: String! @IBOutlet weak var window: NSWindow! func applicationDidFinishLaunching(_ aNotification: Notification) { print("loading") // load subscription information sub = ProcessInfo.processInfo.environment["SPEECH_KEY"] region = ProcessInfo.processInfo.environment["SPEECH_REGION"] label = NSTextField(frame: NSRect(x: 100, y: 50, width: 200, height: 200)) label.textColor = NSColor.black label.lineBreakMode = .byWordWrapping label.stringValue = "Recognition Result" label.isEditable = false self.window.contentView?.addSubview(label) fromMicButton = NSButton(frame: NSRect(x: 100, y: 300, width: 200, height: 30)) fromMicButton.title = "Recognize" fromMicButton.target = self fromMicButton.action = #selector(fromMicButtonClicked) self.window.contentView?.addSubview(fromMicButton) } @objc func fromMicButtonClicked() { DispatchQueue.global(qos: .userInitiated).async { self.recognizeFromMic() } } func recognizeFromMic() { var speechConfig: SPXSpeechConfiguration? do { try speechConfig = SPXSpeechConfiguration(subscription: sub, region: region) } catch { print("error \(error) happened") speechConfig = nil } speechConfig?.speechRecognitionLanguage = "en-US" let audioConfig = SPXAudioConfiguration() let reco = try! SPXSpeechRecognizer(speechConfiguration: speechConfig!, audioConfiguration: audioConfig) reco.addRecognizingEventHandler() {reco, evt in print("intermediate recognition result: \(evt.result.text ?? "(no result)")") self.updateLabel(text: evt.result.text, color: .gray) } updateLabel(text: "Listening ...", color: .gray) print("Listening...") let result = try! reco.recognizeOnce() print("recognition result: \(result.text ?? "(no result)"), reason: \(result.reason.rawValue)") updateLabel(text: result.text, color: .black) if result.reason != SPXResultReason.recognizedSpeech { let cancellationDetails = try! SPXCancellationDetails(fromCanceledRecognitionResult: result) print("cancelled: \(result.reason), \(cancellationDetails.errorDetails)") print("Did you set the speech resource key and region values?") updateLabel(text: "Error: \(cancellationDetails.errorDetails)", color: .red) } } func updateLabel(text: String?, color: NSColor) { DispatchQueue.main.async { self.label.stringValue = text! self.label.textColor = color } } }En AppDelegate.m, use las variables de entorno que estableció anteriormente en la clave de recurso de Voz y en la región.
sub = ProcessInfo.processInfo.environment["SPEECH_KEY"] region = ProcessInfo.processInfo.environment["SPEECH_REGION"]Para cambiar el idioma de reconocimiento de voz, reemplace
en-USpor otroen-US. Por ejemplo, usees-ESpara Español (España). Si no especifica un idioma, el valor predeterminado esen-US. Para más información sobre cómo identificar uno de los distintos idiomas que se pueden hablar, consulte Identificación del idioma.Para hacer visible la salida de depuración, seleccione Ver>Área de depuración>Activar consola.
Para compilar y ejecutar el código de ejemplo, seleccione Producto>Ejecutar en el menú o seleccione el botón Reproducir.
Después de seleccionar el botón de la aplicación y decir algunas palabras, verá el texto que ha dicho en la parte inferior de la pantalla. Al ejecutar la aplicación por primera vez, se le solicita que proporcione a la aplicación acceso al micrófono del equipo.
Comentarios
En este ejemplo se usa la operación recognizeOnce para transcribir expresiones de hasta 30 segundos, o hasta que se detecta el silencio. Para obtener información sobre el reconocimiento continuo de audio más largo, incluidas las conversaciones en varios idiomas, consulte Reconocimiento de voz.
Objective-C
El SDK de Voz para Objective-C comparte bibliotecas cliente y documentación de referencia con el SDK de Voz para Swift. Para ver ejemplos de código de Objective-C, consulte el proyecto de ejemplo reconocer voz de un micrófono en Objective-C en macOS en GitHub.
Limpieza de recursos
Puede usar Azure Portal o la Interfaz de la línea de comandos (CLI) de Azure para quitar el recurso de Voz que creó.
Referencia de la API de REST de Conversión de voz en texto | Referencia de la API de REST de Conversión de voz en texto para audios de corta duración | Ejemplos adicionales sobre GitHub
En este inicio rápido, creará y ejecutará una aplicación para reconocer y realizar la conversión de voz en texto en tiempo real.
En cambio, para transcribir archivos de audio de forma asincrónica, consulte Qué es la transcripción por lotes. Si no está seguro de qué solución de conversión de voz en texto es adecuada para usted, consulte¿Qué es la conversión de voz en texto?
Requisitos previos
- Suscripción a Azure. Puede crear una de forma gratuita.
- Creación de un recurso de Voz en Azure Portal.
- Obtenga la clave y la región del recurso de Voz. Una vez implementado el recurso de Voz, seleccione Ir al recurso para ver y administrar claves.
También necesita un archivo de audio .wav en el equipo local. Puede usar su propio archivo .wav hasta 60 segundos o descargar el archivo de ejemplo https://crbn.us/whatstheweatherlike.wav.
Establecimiento de variables de entorno
Debe autenticar la aplicación para acceder a los servicios de Azure AI. En este artículo se muestra cómo usar variables de entorno para almacenar las credenciales. A continuación, puede acceder a las variables de entorno desde el código para autenticar la aplicación. Para producción, use una manera más segura de almacenar y acceder a sus credenciales.
Importante
Se recomienda la autenticación de Microsoft Entra ID con identidades administradas para los recursos de Azure para evitar almacenar credenciales con sus aplicaciones que se ejecutan en la nube.
Si usa una clave de API, almacénela de forma segura en otro lugar, como en Azure Key Vault. No incluya la clave de API directamente en el código ni la exponga nunca públicamente.
Para más información sobre la seguridad de los servicios de AI, consulte Autenticación de solicitudes a los servicios de Azure AI.
Para establecer las variables de entorno de su clave de recursos de voz y de su región, abra una ventana de la consola y siga las instrucciones correspondientes a su sistema operativo y a su entorno de desarrollo.
- Para establecer la variable de entorno de
SPEECH_KEY, reemplace su clave por una de las claves del recurso. - Para establecer la variable de entorno de
SPEECH_REGION, reemplace su región por una de las regiones del recurso.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Nota:
Si solo necesita acceder a las variables de entorno en la consola actual, puede establecer la variable de entorno con set en vez de setx.
Después de agregar las variables de entorno, puede que tenga que reiniciar cualquier programa que necesite leer las variables de entorno, incluida la ventana de consola. Por ejemplo, si usa Visual Studio como editor, reinícielo antes de ejecutar el ejemplo.
Reconocer la voz a partir de un archivo
Abra una ventana de la consola y ejecute el siguiente comando cURL. Reemplace YourAudioFile.wav por la ruta y el nombre del archivo de audio.
curl --location --request POST "https://%SPEECH_REGION%.stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?language=en-US&format=detailed" ^
--header "Ocp-Apim-Subscription-Key: %SPEECH_KEY%" ^
--header "Content-Type: audio/wav" ^
--data-binary "@YourAudioFile.wav"
Importante
Asegúrese de establecer las variables de entorno SPEECH_KEY y SPEECH_REGION . Si no establece estas variables, se produce un fallo en el ejemplo, con un mensaje de error.
Debería recibir una respuesta similar a la que se muestra aquí. DisplayText debe ser el texto que se reconoció desde el archivo de audio. El comando reconoce hasta 60 segundos de audio y lo convierte en texto.
{
"RecognitionStatus": "Success",
"DisplayText": "My voice is my passport, verify me.",
"Offset": 6600000,
"Duration": 32100000
}
Para más información, consulte API de REST de conversión de voz en texto para audios breves.
Limpieza de recursos
Puede usar Azure Portal o la Interfaz de la línea de comandos (CLI) de Azure para quitar el recurso de Voz que creó.
En este inicio rápido, creará y ejecutará una aplicación para reconocer y realizar la conversión de voz en texto en tiempo real.
En cambio, para transcribir archivos de audio de forma asincrónica, consulte Qué es la transcripción por lotes. Si no está seguro de qué solución de conversión de voz en texto es adecuada para usted, consulte¿Qué es la conversión de voz en texto?
Requisitos previos
- Suscripción a Azure. Puede crear una de forma gratuita.
- Creación de un recurso de Voz en Azure Portal.
- Obtenga la clave y la región del recurso de Voz. Una vez implementado el recurso de Voz, seleccione Ir al recurso para ver y administrar claves.
Configuración del entorno
Siga estos pasos y consulte el inicio rápido de la CLI de Voz para conocer los otros requisitos de la plataforma.
Ejecute el siguiente comando de la CLI de .NET para instalar la CLI de Voz:
dotnet tool install --global Microsoft.CognitiveServices.Speech.CLIConfigure la clave de recurso de Voz y la región mediante la ejecución de los siguientes comandos. Reemplace
SUBSCRIPTION-KEYpor la clave del recurso de Voz yREGIONpor la región del recurso de Voz.spx config @key --set SUBSCRIPTION-KEY spx config @region --set REGION
Reconocimiento de voz a través de un micrófono
Ejecute el siguiente comando para iniciar el reconocimiento de voz a través de un micrófono:
spx recognize --microphone --source en-USHable al micrófono y verá la transcripción de sus palabras en texto en tiempo real. La CLI de Voz se detendrá después de un período de silencio, 30 segundos, o cuando seleccione Ctrl+C.
Connection CONNECTED... RECOGNIZED: I'm excited to try speech to text.
Comentarios
Estas son algunas otras consideraciones:
Para reconocer la voz de un archivo de audio, use
--fileen lugar de--microphone. Para archivos de audio comprimidos como MP4, instale GStreamer y utilice--format. Para más información, consulte Uso de entradas de audio comprimido.spx recognize --file YourAudioFile.wav spx recognize --file YourAudioFile.mp4 --format anyPara mejorar la precisión del reconocimiento de palabras o expresiones específicas, use una lista de frases. Incluya una lista de frases en línea o con un archivo de texto junto con el comando
recognize:spx recognize --microphone --phrases "Contoso;Jessie;Rehaan;" spx recognize --microphone --phrases @phrases.txtPara cambiar el idioma de reconocimiento de voz, reemplace
en-USpor otroen-US. Por ejemplo, usees-ESpara Español (España). Si no especifica un idioma, el valor predeterminado esen-US.spx recognize --microphone --source es-ESPara el reconocimiento continuo del audio durante más de 30 segundos, anexe
--continuous:spx recognize --microphone --source es-ES --continuousEjecute este comando para obtener información sobre más opciones de reconocimiento de voz, como la entrada y la salida de archivos:
spx help recognize
Limpieza de recursos
Puede usar Azure Portal o la Interfaz de la línea de comandos (CLI) de Azure para quitar el recurso de Voz que creó.