Preparación de los datos y carga en la cuenta de almacenamiento
Importante
A partir del 20 de septiembre de 2023, no podrá crear nuevos recursos de Anomaly Detector. El servicio Anomaly Detector se va a retirar el 1 de octubre de 2026.
La detección de anomalías multivariante requiere entrenamiento para procesar los datos y una cuenta de Azure Storage para almacenar los datos para conocer los pasos de entrenamiento e inferencia adicionales.
Preparación de datos
En primer lugar, debe preparar los datos para el entrenamiento y la inferencia.
Esquema de datos de entrada
La detección de anomalías multivariante admite dos tipos de esquemas de datos: OneTable y MultiTable. Puede usar cualquiera de estos esquemas para preparar los datos y cargarlos en la cuenta de almacenamiento para realizar más entrenamiento e inferencia.

Esquema 1: OneTable
OneTable es un archivo CSV que contiene todas las variables que desea entrenar un modelo de detección de anomalías multivariante y una columna timestamp. Descarga de datos de ejemplo de una tabla
Los valores
timestampdeben cumplir la norma ISO 8601; los valores de otras variables en otras columnas pueden ser números enteros o decimales con cualquier número de posiciones decimales.Las variables para el entrenamiento y las variables para la inferencia deben ser coherentes. Por ejemplo, si usa
series_1,series_2,series_3,series_4yseries_5para el entrenamiento, debe proporcionar exactamente las mismas variables para la inferencia.Ejemplo:

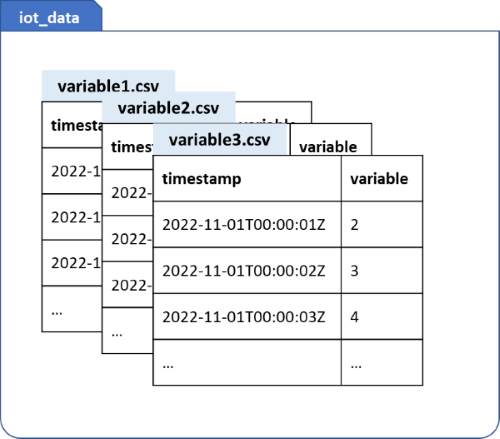
Esquema 2: MultiTable
MultiTable son varios archivos CSV en una carpeta de archivos y cada archivo CSV contiene solo dos columnas de una variable, con los nombres exactos de columna de: marca de tiempo y valor. Descargue los datos de ejemplo de varias tablas y descomprímalos.
Los valores de
timestampdeben cumplir la norma ISO 8601; los devaluepueden ser números enteros o decimales con cualquier número de posiciones decimales.El nombre del archivo csv se va a usar como nombre de variable y debe ser único. Por ejemplo, temperature.csv y humidity.csv.
Las variables para el entrenamiento y las variables para la inferencia deben ser coherentes. Por ejemplo, si usa
series_1,series_2,series_3,series_4yseries_5para el entrenamiento, debe proporcionar exactamente las mismas variables para la inferencia.Ejemplo:
Nota:
Si las marcas de tiempo tienen horas, minutos o segundos, asegúrese de que se redondeen correctamente antes de llamar a las API. Por ejemplo, si se da por hecho que la frecuencia de los datos es un punto de datos cada 30 segundos, pero observa marcas de tiempo como "12:00:01" y "12:00:28", es señal segura de que debe procesar previamente las marcas de tiempo a nuevos valores como "12:00:00" y "12:00:30". Para obtener más información, vea la sección "Redondeo de marcas de tiempo" del documento de procedimientos recomendados.
Carga de los datos en la cuenta de almacenamiento
Una vez que prepare los datos con cualquiera de los dos esquemas anteriores, puede cargar el archivo CSV (OneTable) o la carpeta de datos (MultiTable) en la cuenta de almacenamiento.
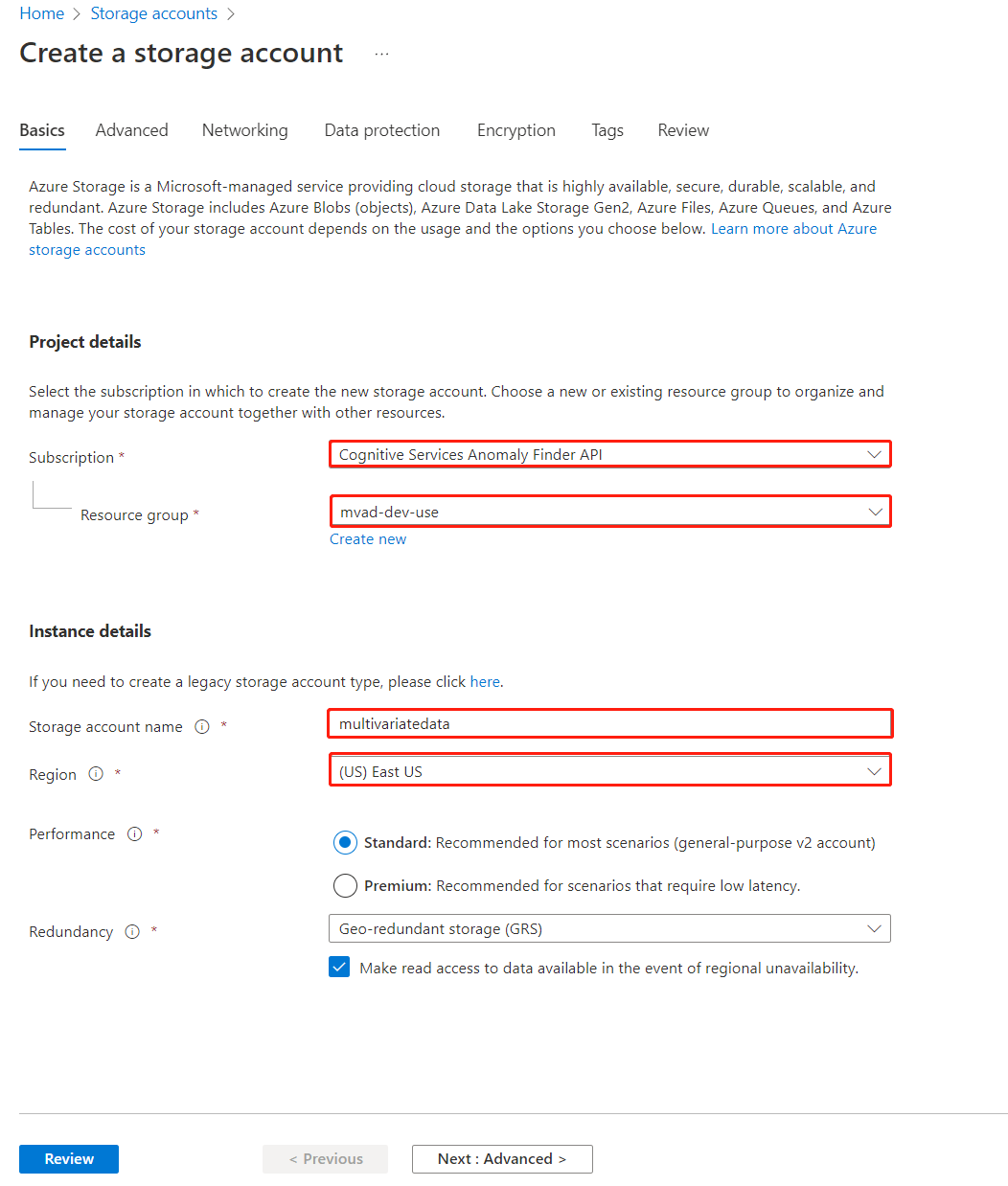
Cree una cuenta de almacenamiento, rellene los campos, que son similares a los pasos al crear Anomaly Detector recurso.
Seleccione Contenedor a la izquierda en el recurso de la cuenta de almacenamiento y seleccione +Contenedor para crear uno que almacene los datos.
Cargue los datos al contenedor.
Carga de datos de OneTable
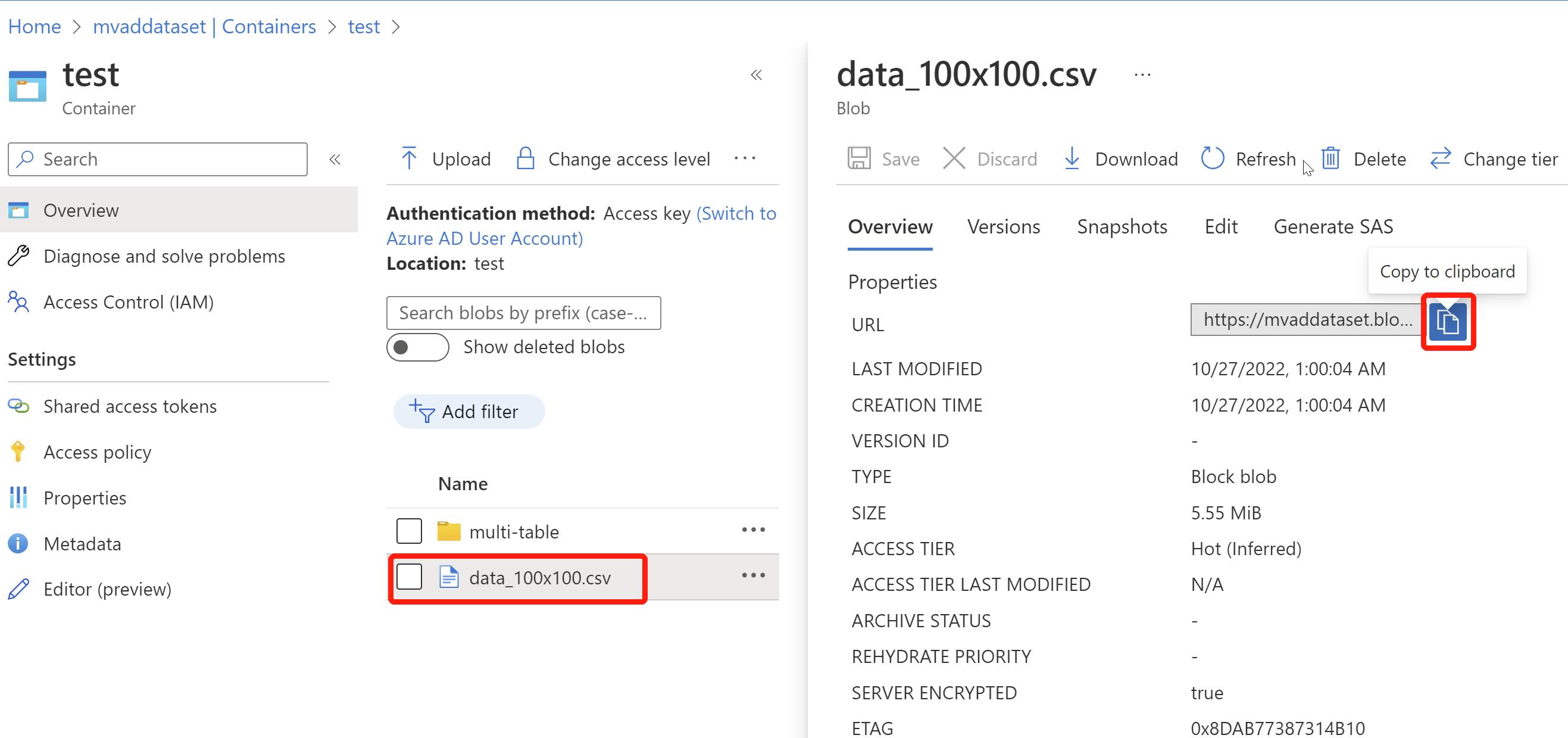
Vaya al contenedor creado y seleccione Cargar y, a continuación, elija el archivo CSV preparado y cárguelo.
Una vez cargados los datos, seleccione el archivo CSV y copie la dirección URL del blob mediante el pequeño botón azul. (Pegue la dirección URL en algún lugar conveniente para seguir los pasos).
Carga de datos multitable
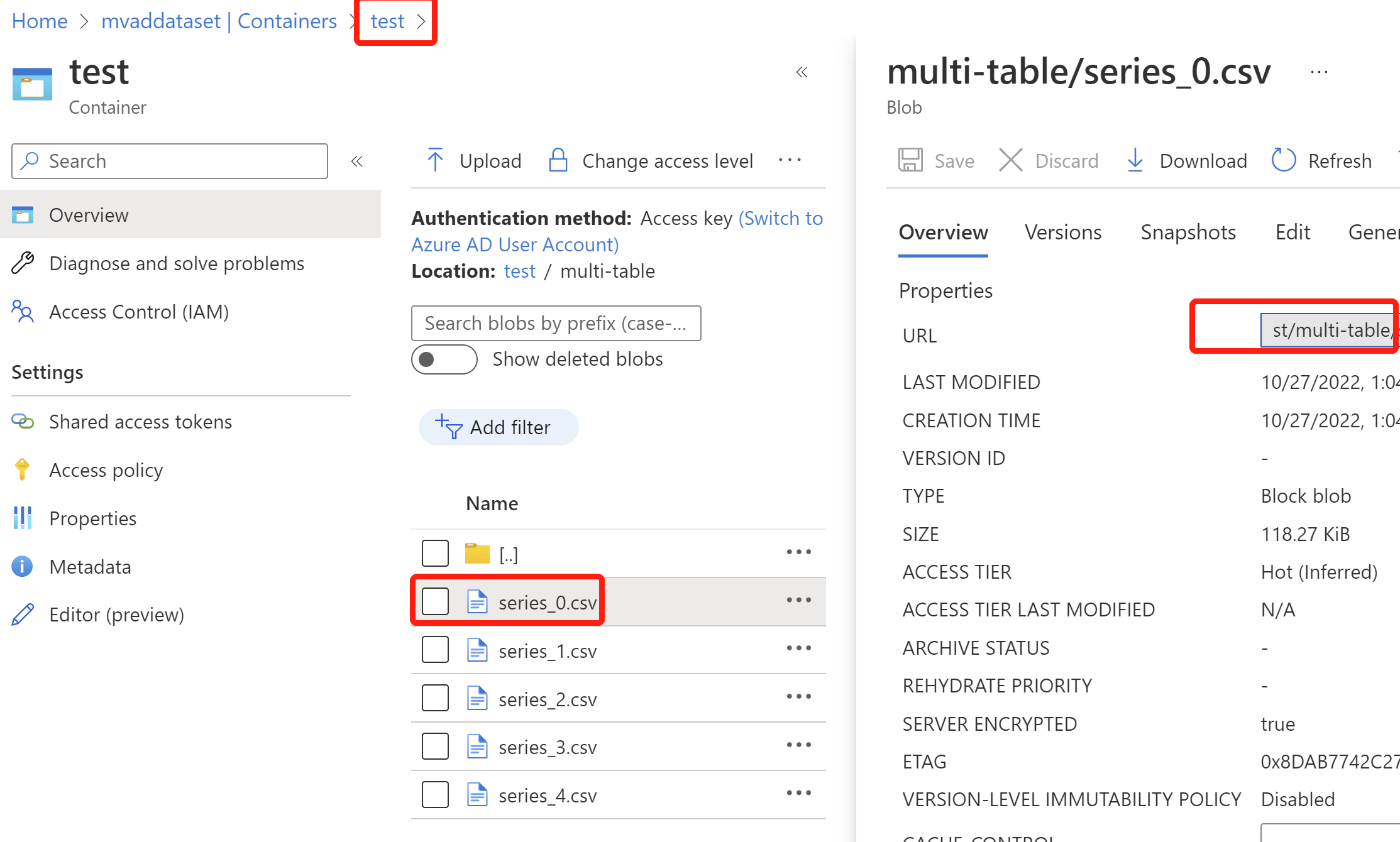
Vaya al contenedor que creó y seleccione Cargar, seleccione Avanzadas e inicie un nombre de carpeta en Cargar en carpeta y seleccione todas las variables en archivos CSV independientes y cargue.
Una vez cargados los datos, vaya a la carpeta y seleccione un archivo CSV en la carpeta, copie la dirección URL del blob y mantenga solo la parte antes del nombre de este archivo CSV, por lo que la dirección URL final del blob debe vincularse a la carpeta. (Pegue la dirección URL en algún lugar conveniente para seguir los pasos).
Conceda a Anomaly Detector acceso para leer los datos de la cuenta de almacenamiento.
- En el contenedor, seleccione Access Control(IAM) a la izquierda, seleccione + Agregar a agregar asignación de roles. Si ve que la asignación de roles para agregar está deshabilitada, póngase en contacto con el propietario de la cuenta de almacenamiento para agregar el rol Propietario al contenedor.
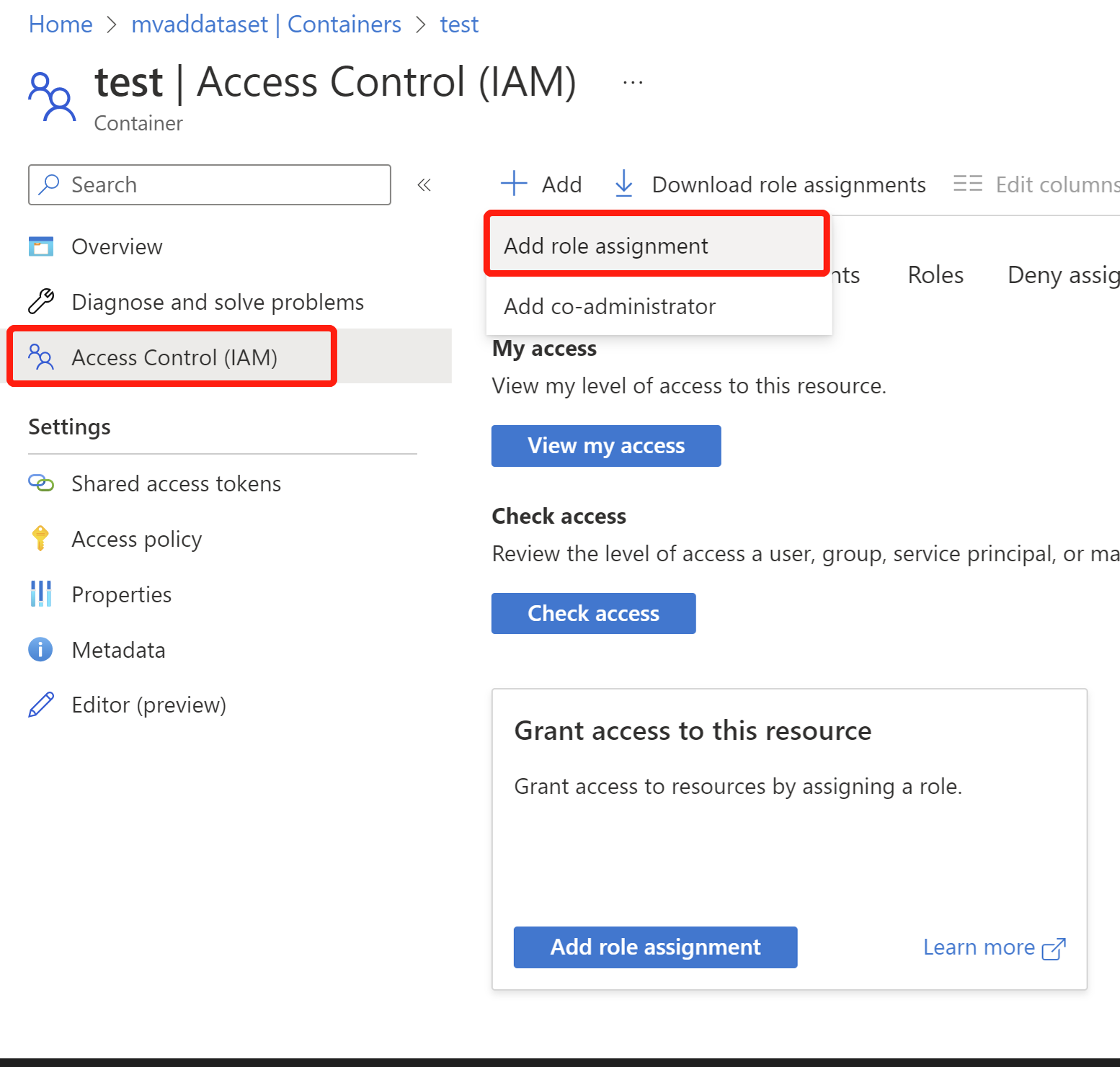
- Busque y seleccione el rol Lector de datos de blobs de almacenamiento y, a continuación, seleccione Siguiente. Técnicamente, todos los roles resaltados a continuación y el rol Propietario deberían funcionar.
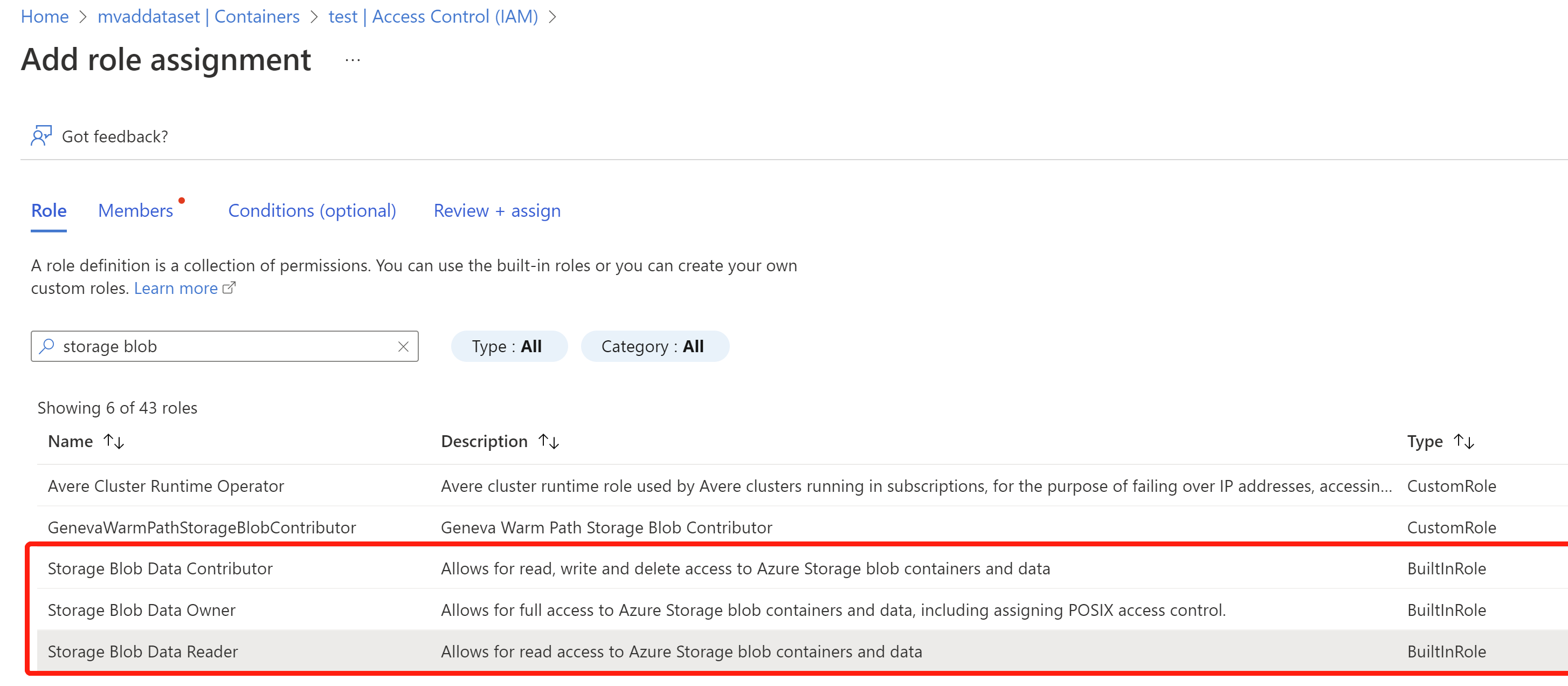
- Seleccione Asignar acceso a la identidad administrada, Seleccione Miembros y, después, elija el recurso de detector de anomalías que creó anteriormente y, después, seleccione Revisar y asignar.