Tutorial: Usar Multivariate Anomaly Detector en Azure Synapse Analytics
Importante
A partir del 20 de septiembre de 2023, no podrá crear nuevos recursos de Anomaly Detector. El servicio Anomaly Detector se va a retirar el 1 de octubre de 2026.
Use este tutorial para detectar anomalías entre distintas variables en Azure Synapse Analytics en conjuntos de datos y bases de datos muy grandes. Esta solución es perfecta para escenarios como el mantenimiento predictivo de equipos. La potencia subyacente procede de la integración con SynapseML, una biblioteca de código abierto que pretende simplificar la creación de canalizaciones de aprendizaje automático escalables de forma masiva. Se puede instalar y usar en cualquier infraestructura de Spark 3, incluido el equipo local, Databricks, Synapse Analytics y otros.
En este tutorial, aprenderá a:
- Use Azure Synapse Analytics para detectar anomalías entre distintas variables en Synapse Analytics.
- Entrene un modelo de detector de anomalías multivariante e inferencia en cuadernos independientes en Synapse Analytics.
- Obtiene el resultado de la detección de anomalías y el análisis de la causa principal de cada anomalía.
Prerrequisitos
En esta sección, creará los siguientes recursos en Azure Portal:
- Un recurso Anomaly Detector para obtener acceso a la funcionalidad de Multivariate Anomaly Detector.
- Un recurso de Azure Synapse Analytics para usar Synapse Studio.
- Una cuenta de almacenamiento para cargar los datos para el entrenamiento del modelo y la detección de anomalías.
- Un recurso Key Vault que contiene la clave de Anomaly Detector y la cadena de conexión de la cuenta de almacenamiento.
Creación de recursos de Anomaly Detector y Azure Synapse Analytics
Cree un recurso para Azure Synapse Analytics en Azure Portal y rellene todos los elementos necesarios.
Cree un recurso de Anomaly Detector en Azure Portal.
Inicie sesión en Azure Synapse Analytics con su suscripción y el nombre del área de trabajo.
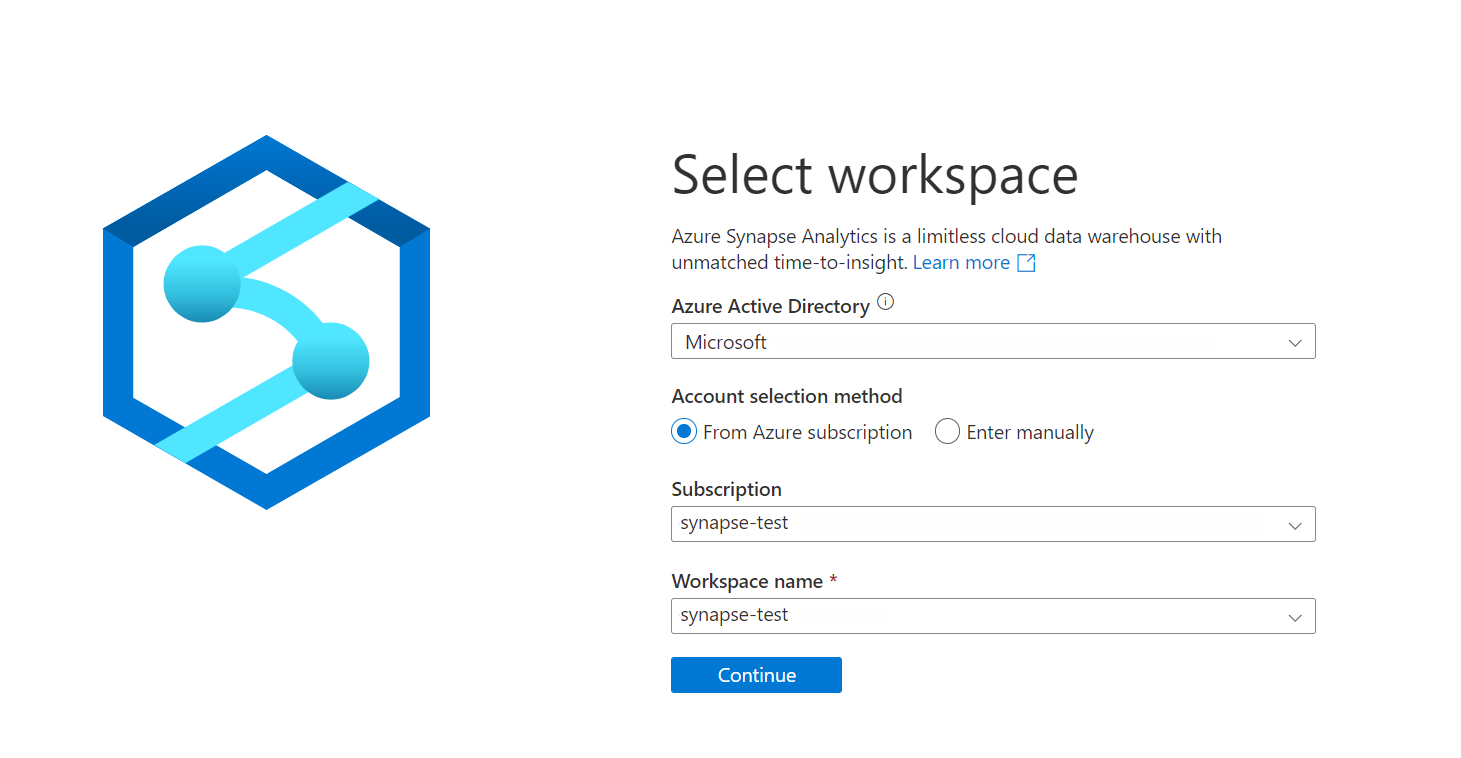
Creación de un recursos de cuenta de almacenamiento
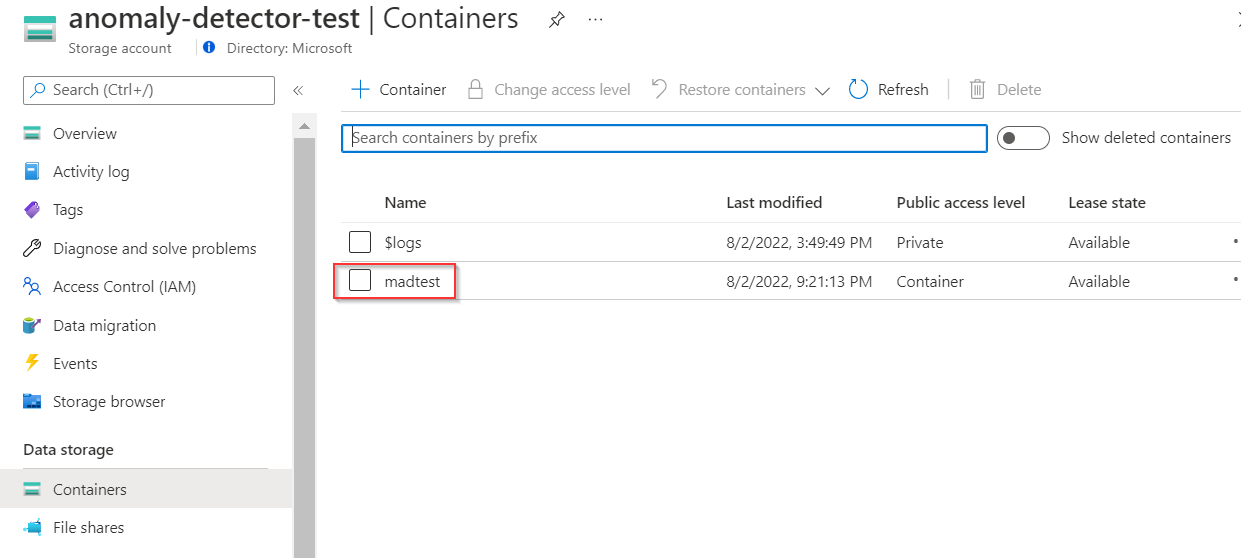
Cree un recurso de cuenta de almacenamiento en Azure Porta. Una vez compilada la cuenta de almacenamiento, cree un contenedor para almacenar datos intermedios, ya que SynapseML transformará los datos originales en un esquema que admite Multivariate Anomaly Detector. (Consulte el esquema de entrada de Multivariate Anomaly Detector)
Nota:
Para los fines de este ejemplo, solo se establece la seguridad en el contenedor para permitir el acceso de lectura anónimo para contenedores y blobs, ya que solo contendrá nuestros datos de ejemplo .csv. Para fines distintos a demostración, no se recomienda.
Creación de un Key Vault para contener una clave de Anomaly Detector y una cadena de conexión de cuenta de almacenamiento
Creación de un almacén de claves y configuración de los secretos y el acceso
Cree un almacén de claves en Azure Portal.
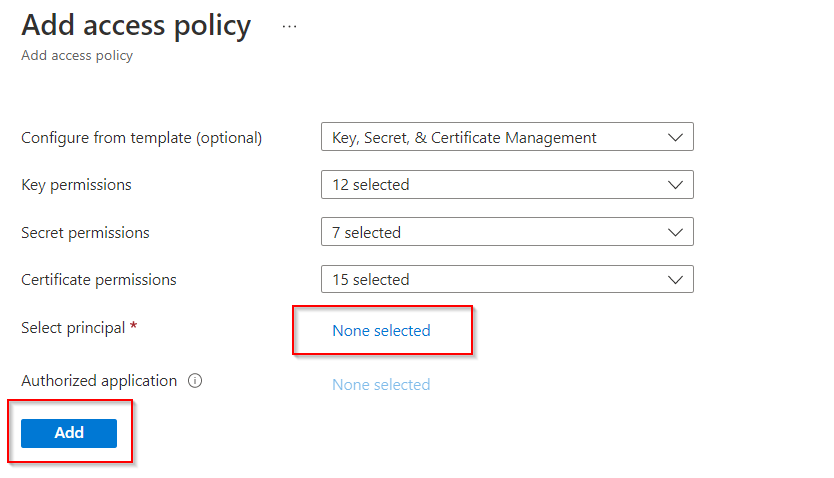
Vaya a Key Vault > Directivas de acceso y conceda permiso al área de trabajo de Azure Synapse para leer secretos de Azure Key Vault.
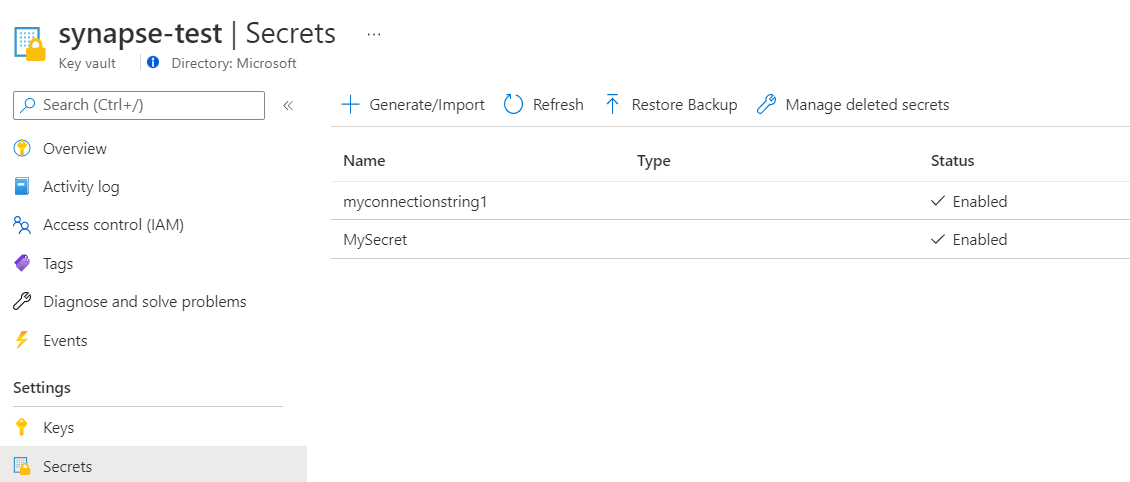
Creación de un secreto en Key Vault para contener la clave de Anomaly Detector
Vaya al recurso de Anomaly Detector, Anomaly Detector>Claves y punto de conexión. A continuación, copie una de las dos claves en el Portapapeles.
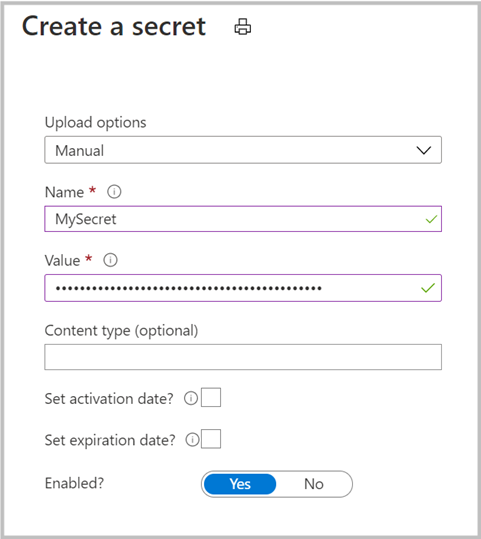
Vaya a Key Vault>Secreto para crear un secreto nuevo. Especifique el nombre del secreto y pegue la clave del paso anterior en el campo Valor. Por último, seleccione Crear.
Creación de un secreto en Key Vault para contener la cadena de conexión de la cuenta de almacenamiento
Vaya al recurso de la cuenta de almacenamiento y seleccione Claves de acceso para copiar una de las cadenas de conexión.
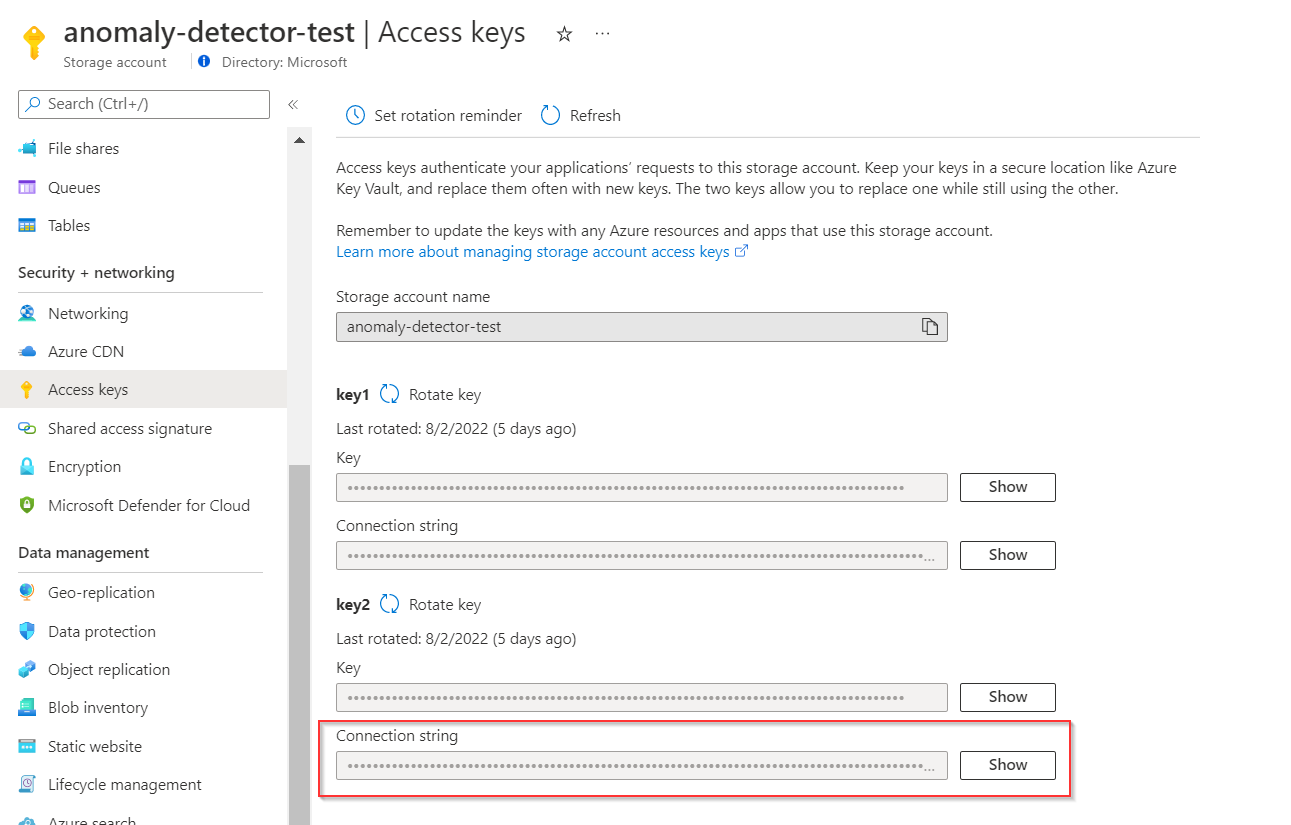
Después vaya a Key Vault>Secreto para crear un secreto nuevo. Especifique el nombre del secreto (como micadenadeconexión) y pegue la cadena de conexión del paso anterior en el campo Valor. Por último, seleccione Crear.
Uso de un cuaderno para realizar la detección de anomalías multivariante en Synapse Analytics
Creación de un cuaderno y un grupo de Spark
Inicie sesión en Azure Synapse Analytics y cree un cuaderno para codificar.
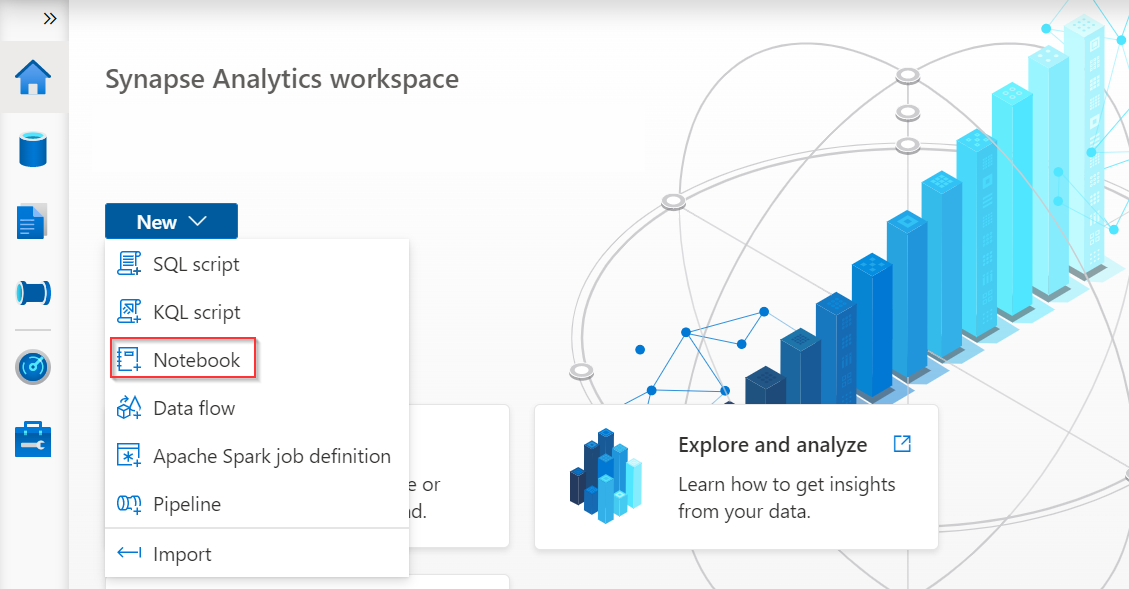
Seleccione Administrar grupos en la página del cuaderno para crear un nuevo grupo de Apache Spark si no tiene uno.

Escritura de código en el cuaderno
Instale la versión más reciente de SynapseML con los modelos de Spark de detección de anomalías. También puede instalar SynapseML en paquetes de Spark, Databricks, Docker, etc. Consulte la página principal de SynapseML.
Si usa Spark 3.1, use el código siguiente:
%%configure -f { "name": "synapseml", "conf": { "spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.9.5-13-d1b51517-SNAPSHOT", "spark.jars.repositories": "https://mmlspark.azureedge.net/maven", "spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.12,org.scalactic:scalactic_2.12,org.scalatest:scalatest_2.12", "spark.yarn.user.classpath.first": "true" } }Si usa Spark 3.2, use el código siguiente:
%%configure -f { "name": "synapseml", "conf": { "spark.jars.packages": " com.microsoft.azure:synapseml_2.12:0.9.5 ", "spark.jars.repositories": "https://mmlspark.azureedge.net/maven", "spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.12,org.scalactic:scalactic_2.12,org.scalatest:scalatest_2.12,io.netty:netty-tcnative-boringssl-static", "spark.yarn.user.classpath.first": "true" } }Importe los módulos y bibliotecas necesarios.
from synapse.ml.cognitive import * from notebookutils import mssparkutils import numpy as np import pandas as pd import pyspark from pyspark.sql.functions import col from pyspark.sql.functions import lit from pyspark.sql.types import DoubleType import synapse.mlCargue los datos. Cree los datos en el siguiente formato y cárguelos en un almacenamiento en la nube que Spark admita como una cuenta de Azure Storage. La columna de marca de tiempo debe tener el formato
ISO8601y las columnas de características deben ser de tipostring.df = spark.read.format("csv").option("header", True).load("wasbs://[container_name]@[storage_account_name].blob.core.windows.net/[csv_file_name].csv") df = df.withColumn("sensor_1", col("sensor_1").cast(DoubleType())) \ .withColumn("sensor_2", col("sensor_2").cast(DoubleType())) \ .withColumn("sensor_3", col("sensor_3").cast(DoubleType())) df.show(10)
Entrenamiento de un modelo de detección de anomalías multivariante.
#Input your key vault name and anomaly key name in key vault. anomalyKey = mssparkutils.credentials.getSecret("[key_vault_name]","[anomaly_key_secret_name]") #Input your key vault name and connection string name in key vault. connectionString = mssparkutils.credentials.getSecret("[key_vault_name]", "[connection_string_secret_name]") #Specify information about your data. startTime = "2021-01-01T00:00:00Z" endTime = "2021-01-02T09:18:00Z" timestampColumn = "timestamp" inputColumns = ["sensor_1", "sensor_2", "sensor_3"] #Specify the container you created in Storage account, you could also initialize a new name here, and Synapse will help you create that container automatically. containerName = "[container_name]" #Set a folder name in Storage account to store the intermediate data. intermediateSaveDir = "intermediateData" simpleMultiAnomalyEstimator = (FitMultivariateAnomaly() .setSubscriptionKey(anomalyKey) #In .setLocation, specify the region of your Anomaly Detector resource, use lowercase letter like: eastus. .setLocation("[anomaly_detector_region]") .setStartTime(startTime) .setEndTime(endTime) .setContainerName(containerName) .setIntermediateSaveDir(intermediateSaveDir) .setTimestampCol(timestampColumn) .setInputCols(inputColumns) .setSlidingWindow(200) .setConnectionString(connectionString))Desencadene el proceso de entrenamiento a través de estos códigos.
model = simpleMultiAnomalyEstimator.fit(df) type(model)Desencadene el proceso de inferencia.
startInferenceTime = "2021-01-02T09:19:00Z" endInferenceTime = "2021-01-03T01:59:00Z" result = (model .setStartTime(startInferenceTime) .setEndTime(endInferenceTime) .setOutputCol("results") .setErrorCol("errors") .setTimestampCol(timestampColumn) .setInputCols(inputColumns) .transform(df))Obtenga los resultados de inferencia.
rdf = (result.select("timestamp",*inputColumns, "results.contributors", "results.isAnomaly", "results.severity").orderBy('timestamp', ascending=True).filter(col('timestamp') >= lit(startInferenceTime)).toPandas()) def parse(x): if type(x) is list: return dict([item[::-1] for item in x]) else: return {'series_0': 0, 'series_1': 0, 'series_2': 0} rdf['contributors'] = rdf['contributors'].apply(parse) rdf = pd.concat([rdf.drop(['contributors'], axis=1), pd.json_normalize(rdf['contributors'])], axis=1) rdfLos resultados de la inferencia tendrán el aspecto siguiente.
severityes un número comprendido entre 0 y 1, que muestra el grado de gravedad de una anomalía. Las tres últimas columnas indican el valorcontribution scorede cada sensor, cuanto mayor sea el número, más anómalo será el sensor.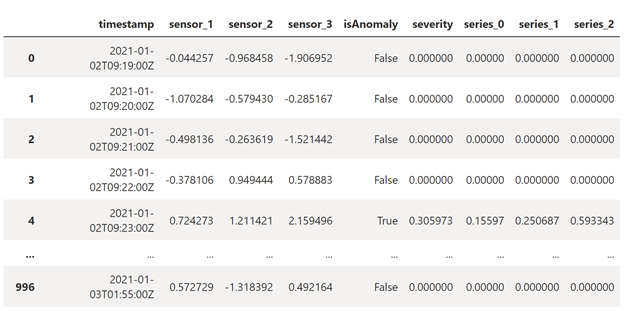
Limpieza de datos intermedios (opcional)
De forma predeterminada, el detector de anomalías cargará automáticamente los datos en una cuenta de almacenamiento para que el servicio pueda procesar los datos. Para limpiar los datos intermedios, puede ejecutar los códigos siguientes.
simpleMultiAnomalyEstimator.cleanUpIntermediateData()
model.cleanUpIntermediateData()
Uso del modelo entrenado en otro cuaderno con el identificador de modelo (opcional)
Si tiene la necesidad de ejecutar el código de entrenamiento y el código de inferencia en cuadernos independientes de Synapse, primero podría obtener el identificador del modelo y usarlo para cargar el modelo en otro cuaderno mediante la creación de un nuevo objeto.
Obtenga el identificador del modelo en el cuaderno de entrenamiento.
model.getModelId()Cargue el cuaderno de inferencia del modelo.
retrievedModel = (DetectMultivariateAnomaly() .setSubscriptionKey(anomalyKey) .setLocation("eastus") .setOutputCol("result") .setStartTime(startTime) .setEndTime(endTime) .setContainerName(containerName) .setIntermediateSaveDir(intermediateSaveDir) .setTimestampCol(timestampColumn) .setInputCols(inputColumns) .setConnectionString(connectionString) .setModelId('5bXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXe9'))
Saber más
Acerca de Anomaly Detector
- Obtenga más información sobre Multivariate Anomaly Detector.
- ¿Necesita soporte técnico? Únase a la comunidad de Anomaly Detector.
Acerca de Synapse
- Inicio rápido: Configuración de los requisitos previos para usar servicios de Azure AI en Azure Synapse Analytics.
- Visite el nuevo sitio web de SynpaseML para obtener los documentos, demostraciones y ejemplos más recientes.
- Más información acerca de Synapse Analytics.
- Obtenga información sobre la SynapseML versión v0.9.5 en GitHub.