Filtrado de contenido en Inteligencia artificial de Azure Studio
Importante
Algunas de las características descritas en este artículo solo pueden estar disponibles en versión preliminar. Esta versión preliminar se ofrece sin acuerdo de nivel de servicio y no se recomienda para las cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas. Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
Azure AI Studio incluye un sistema de filtrado de contenido que funciona junto con los modelos principales y los modelos de generación de imágenes DALL-E.
Importante
El sistema de filtrado de contenido no se aplica a solicitudes y finalizaciones procesadas por el modelo Whisper en el servicio Azure OpenAI. Obtenga más información sobre el modelo Whisper en Azure OpenAI.
Funcionamiento
Este sistema de filtrado de contenido se basa en Seguridad de contenido de Azure AI, y funciona mediante la ejecución de la salida de solicitud de entrada y finalización a través de un conjunto de modelos de clasificación destinados a detectar y evitar la salida de contenido perjudicial. Las variaciones en las configuraciones de API y el diseño de aplicaciones pueden afectar a las finalizaciones y, por tanto, al comportamiento de filtrado.
Con las implementaciones de modelos de Azure OpenAI, puede usar el filtro de contenido predeterminado o crear su propio filtro de contenido (que se describe más adelante). El filtro de contenido predeterminado también está disponible para otros modelos de texto mantenidos por Azure AI en el catálogo de modelos, pero los filtros de contenido personalizados aún no están disponibles para esos modelos. Los modelos disponibles a través de los Modelos como servicio tienen el filtrado de contenido habilitado de forma predeterminada y no se pueden configurar.
Compatibilidad con idiomas
Los modelos de filtrado de contenido se han entrenado y probado en los siguientes idiomas: inglés, alemán, japonés, español, francés, italiano, portugués y chino. Sin embargo, el servicio puede funcionar en muchos otros idiomas, pero la calidad puede variar. En todos los casos, debe realizar sus propias pruebas para asegurarse de que funciona para la aplicación.
Creación de un filtro de contenido
Para cualquier implementación de modelos en Azure AI Studio, puede usar directamente el filtro de contenido predeterminado, pero es posible que desee tener más control. Por ejemplo, podría hacer que un filtro sea más estricto o más permisivo, o habilitar funcionalidades más avanzadas, como escudos de avisos y detección de materiales protegidos.
Siga estos pasos para crear un filtro de contenido:
Vaya a AI Studio y vaya al centro. A continuación, seleccione la pestaña Filtros de contenido en el panel de navegación izquierdo y seleccione el botón Crear filtro de contenido.

En la página Información básica, escriba un nombre para el filtro de contenido. Seleccione una conexión para asociar con el filtro de contenido. Luego, seleccione Siguiente.

En la página Filtros de entrada, puede establecer el filtro para el mensaje de entrada. Establezca el umbral de nivel de gravedad y acción para cada tipo de filtro. En esta página se configuran los filtros predeterminados y otros filtros (como Prompt Shields para ataques de jailbreak). Luego, seleccione Siguiente.
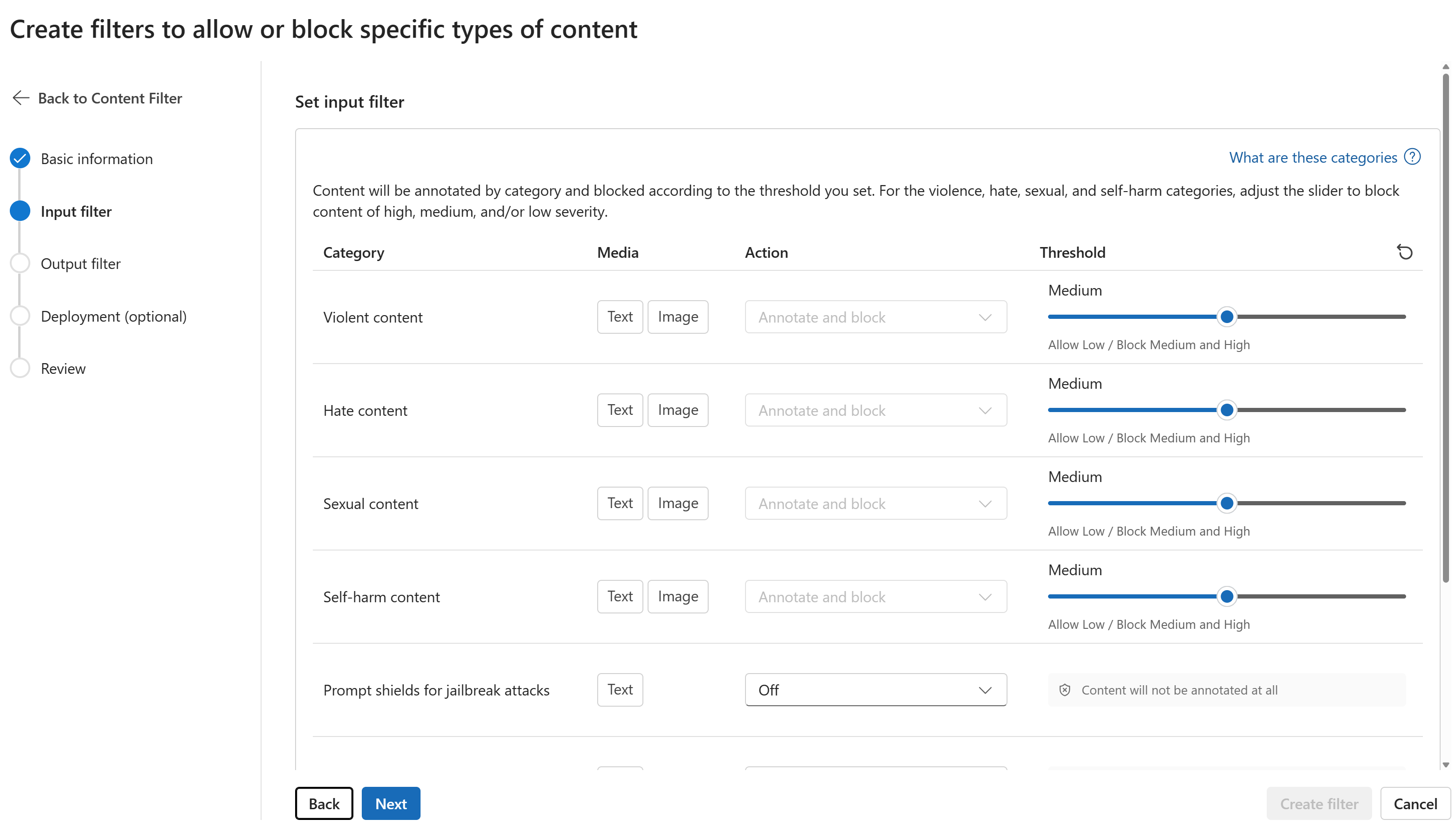
El contenido se anotará por categoría y se bloqueará según el umbral establecido. Para las categorías de violencia, odio, sexo y autolesión, ajuste el control deslizante para bloquear el contenido de gravedad alta, media o baja.
En la página Filtros de salida, puede configurar el filtro de salida, que se aplicará a todo el contenido de salida generado por el modelo. Configure los filtros individuales como antes. Esta página también proporciona la opción Modo de streaming, que permite filtrar el contenido casi en tiempo real a medida que el modelo genera, lo que reduce la latencia. Cuando haya terminado, seleccione Siguiente.
Cada categoría anotará el contenido y se bloqueará según el umbral. Para el contenido violento, el contenido de odio, el contenido sexual y la categoría de contenido de daño personal, ajuste el umbral para bloquear el contenido dañino con niveles de gravedad iguales o superiores.
Opcionalmente, en la página Implementación, puede asociar el filtro de contenido a una implementación. Si una implementación seleccionada ya tiene un filtro asociado, debe confirmar que desea reemplazarla. También puede asociar el filtro de contenido a una implementación más adelante. Seleccione Crear.
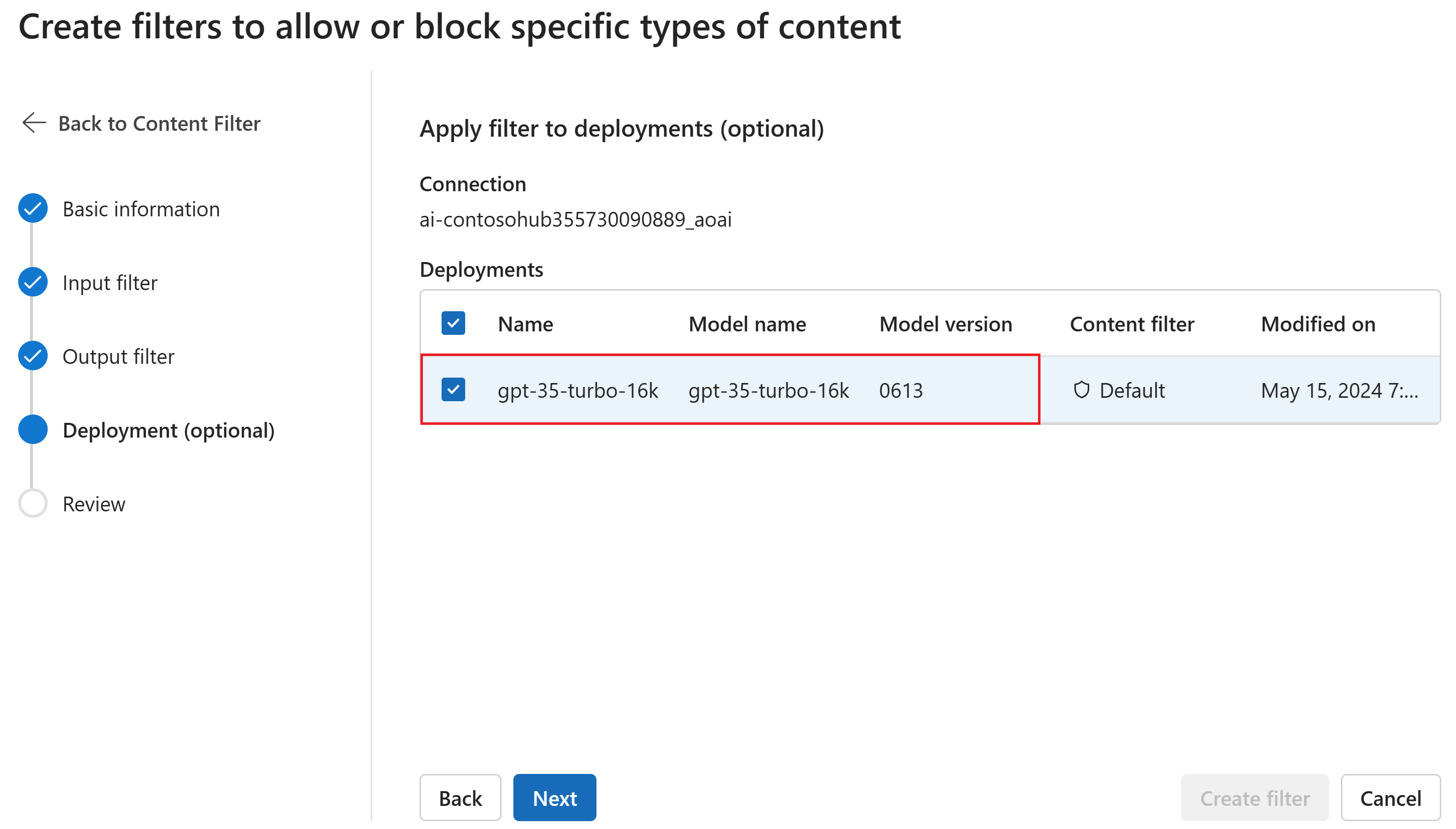
Las configuraciones de filtrado de contenido se crean en el nivel de concentrador en AI Studio. Obtenga más información sobre la capacidad de configuración en los Documentos de Azure OpenAI.
En la página Revisar, revise la configuración y a continuación, seleccione Crear filtro.




Usar una lista de bloqueados como filtro
Puede aplicar una lista de bloqueados como un filtro de entrada o salida, o ambos. Habilite la opción Lista de bloqueados en la página Filtro de entrada o Filtro de salida. Seleccione una o varias listas de bloqueados en la lista desplegable o use la lista de bloqueados soeces integrada. Puede combinar varias listas de bloqueados en el mismo filtro.
Aplicar un filtro de contenido
El proceso de creación de filtros le ofrece la opción de aplicar el filtro a las implementaciones que desee. También puede cambiar o quitar filtros de contenido de las implementaciones en cualquier momento.
Siga estos pasos para aplicar un filtro de contenido a una implementación:
Vaya a AI Studio y seleccione un proyecto.
Seleccione Implementaciones y elija una de las implementaciones y a continuación, seleccione Editar.

En la ventana Actualizar implementación, seleccione el filtro de contenido que desea aplicar a la implementación.



Ahora, puede ir al área de juegos para probar si el filtro de contenido funciona según lo previsto.
Categorías
| Category | Descripción |
|---|---|
| Odio | La categoría de odio describe los ataques o usos del lenguaje que incluyen un lenguaje peyorativo o discriminatorio con referencia a una persona o grupo de identidad en función de ciertos atributos diferenciadores de estos grupos, incluidos, entre otros, la raza, la etnia, la nacionalidad, la identidad y expresión de género, la orientación sexual, la religión, el estatus migratorio, el estado de capacidad, la apariencia personal y el tamaño corporal. |
| Sexual | La categoría sexual describe el lenguaje relacionado con órganos anatómicos y genitales, relaciones románticas, actos representados en términos eróticos o cariñosos, actos sexuales físicos, incluidos los que se representan como una agresión o un acto violento sexual forzado contra la voluntad, la prostitución, la pornografía y el abuso. |
| Violencia | La categoría de violencia describe el lenguaje relacionado con acciones físicas destinadas a herir, lesionar, dañar o matar a alguien o algo; describe armas, etc. |
| Autolesiones | En la categoría auto-daño se describe el lenguaje relacionado con las acciones físicas destinadas a dañar, dañar o dañar el cuerpo de uno mismo, o matarse a sí mismo. |
Niveles de gravedad
| Category | Descripción |
|---|---|
| Caja fuerte | El contenido puede estar relacionado con categorías de violencia, autolesiones, sexualidad u odio, pero los términos se usan en contextos generales, periodísticos, científicos, médicos y profesionales similares, que son apropiados para la mayoría del público. |
| Bajo | Contenido que expresa prejuicios, juicios u opiniones, incluyen el uso ofensivo del lenguaje, los estereotipos, los casos de uso que exploran un mundo ficticio (por ejemplo, los juegos, la literatura) y las representaciones con baja intensidad. |
| Media | El contenido que usa un lenguaje ofensivo, insultante, burlón, intimidatorio o degradante hacia grupos de identidad específicos, incluye representaciones de búsqueda y ejecución de instrucciones dañinas, fantasías, glorificación, promoción del daño con una intensidad media. |
| Alto | Contenido que muestra instrucciones, acciones, daños o abusos explícitos y gravemente perjudiciales; incluye la aprobación, glorificación o promoción de actos gravemente perjudiciales, formas extremas o ilegales de daño, radicalización o intercambio o abuso de poder no consentido. |
Capacidad de configuración (versión preliminar)
La configuración de filtrado de contenido predeterminada para la serie de modelos GPT se establece para filtrar en el umbral de gravedad medio para las cuatro categorías de daño de contenido (odio, violencia, sexual y autolesión) y se aplica a ambos avisos (texto, texto o imagen multi modal) y finalizaciones (texto). Esto significa que el contenido que se detecta en el nivel de gravedad medio o alto se filtra, mientras que el contenido detectado en el nivel de gravedad bajo no se filtra por los filtros de contenido. Para DALL-E, el umbral de gravedad predeterminado se establece en bajo para las solicitudes (texto) y finalizaciones (imágenes), por lo que el contenido detectado en niveles de gravedad bajo, medio o alto se filtra. La característica de configuración está disponible en versión preliminar y permite a los clientes ajustar la configuración, por separado para solicitudes y finalizaciones, para filtrar el contenido de cada categoría de contenido en distintos niveles de gravedad, tal y como se describe en la tabla siguiente:
| Gravedad filtrada | Configurable para solicitudes | Configurable para finalizaciones | Descripciones |
|---|---|---|---|
| Bajo, medio, alto | Sí | Sí | Configuración de filtrado más estricta. El contenido detectado en niveles de gravedad bajo, medio y alto se filtra. |
| Medio y alto | Sí | Sí | El contenido detectado en el nivel de gravedad bajo no se filtra, sino que se filtra el contenido de un nivel medio y alto. |
| Alto | Sí | Sí | El contenido detectado en niveles de gravedad bajo y medio no se filtra. Solo se filtra el contenido en el nivel de gravedad alto. Requiere aprobación1. |
| Sin filtros | Si se aprueba1 | Si se aprueba1 | No se filtra ningún contenido, independientemente del nivel de gravedad detectado. Requiere aprobación1. |
1 Para los modelos de Azure OpenAI, solo los clientes que hayan sido aprobados para filtrar contenido modificado pueden controlar el filtrado completo del contenido, lo que incluye la configuración de filtros de contenido solo en el nivel de gravedad alto o la desactivación de los filtros de contenido. Solicite filtros de contenido modificado mediante este formulario: Revisión de acceso limitado de Azure OpenAI: filtros de contenido modificados y supervisión de abusos (microsoft.com)
Los clientes son responsables de garantizar que las aplicaciones que integran Azure OpenAI cumplan con el código de conducta.
Otros filtros de entrada
También puede habilitar filtros especiales para escenarios de IA generativa:
- Ataques de Jailbreak: los ataques de Jailbreak son mensajes de usuario diseñados para provocar el modelo de IA generativa en comportamientos que se entrenaron para evitar o interrumpir las reglas establecidas en el mensaje del sistema.
- Ataques indirectos: los ataques indirectos, también conocidos como ataques indirectos de avisos indirectos o ataques de inyección de mensajes entre dominios, son una posible vulnerabilidad en la que terceros colocan instrucciones malintencionadas dentro de los documentos a los que el sistema de inteligencia artificial generativa puede acceder y procesar.
Otros filtros de salida
También puede habilitar los siguientes filtros de salida especiales:
- Material protegido para texto: el texto del material protegido describe el contenido de texto conocido (por ejemplo, letras de canciones, artículos, recetas y contenido web seleccionado) que pueden generar modelos de lenguaje grandes.
- Material protegido para el código: el código material protegido describe el código fuente que coincide con un conjunto de código fuente de repositorios públicos, que pueden generar modelos de lenguaje grandes sin cita adecuada de repositorios de origen.
- Base: el filtro de detección de la base detecta si las respuestas de texto de los modelos de lenguaje grande (LLM) se basan en los materiales de origen proporcionados por los usuarios.
Pasos siguientes
- Más información sobre los modelos subyacentes que impulsan Azure OpenAI.
- El filtrado de contenido de Inteligencia artificial de Azure Studio funciona con tecnología de seguridad del contenido de Azure AI.
- Obtenga más información sobre cómo comprender y mitigar los riesgos asociados a la aplicación: Información general sobre las prácticas de inteligencia artificial responsable para los modelos de Azure OpenAI.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de