Antipatrón Extraneous Fetching
Los antipatrones son errores de diseño comunes que pueden interrumpir el funcionamiento del software o las aplicaciones en situaciones de carga elevada y que no deberían pasarse por alto. En un antipatrón de recuperación superflua, se recuperan más datos de los necesarios para una operación empresarial, lo que suele producir una sobrecarga de E/S innecesaria y una capacidad de respuesta reducida.
Ejemplo del antipatrón de recuperación superflua
Este antipatrón puede producirse si la aplicación intenta minimizar las solicitudes de E/S recuperando todos los datos que podría necesitar. A menudo, es el resultado de realizar una compensación excesiva para el antipatrón Chatty I/O. Por ejemplo, una aplicación podría capturar los detalles de todos los productos de una base de datos. Pero puede que el usuario solo tenga un subconjunto de los detalles (algunos pueden no ser pertinentes para los clientes) y probablemente no necesite ver todos los productos a la vez. Aunque el usuario esté explorando el catálogo completo, tendría sentido paginar los resultados (por ejemplo, mostrar 20 a la vez).
Otro origen de este problema es seguir prácticas de programación o diseño deficientes. Por ejemplo, el código siguiente utiliza Entity Framework para capturar los detalles completos para todos los productos. A continuación, filtra los resultados para devolver únicamente un subconjunto de los campos y descarta el resto. Puede encontrar el ejemplo completo aquí.
public async Task<IHttpActionResult> GetAllFieldsAsync()
{
using (var context = new AdventureWorksContext())
{
// Execute the query. This happens at the database.
var products = await context.Products.ToListAsync();
// Project fields from the query results. This happens in application memory.
var result = products.Select(p => new ProductInfo { Id = p.ProductId, Name = p.Name });
return Ok(result);
}
}
En el ejemplo siguiente, la aplicación recupera los datos para llevar a cabo una agregación que puede realizar la base de datos en su lugar. La aplicación calcula el total de ventas obteniendo todos los registros de todos los pedidos vendidos y, a continuación, calculando la suma de esos registros. Puede encontrar el ejemplo completo aquí.
public async Task<IHttpActionResult> AggregateOnClientAsync()
{
using (var context = new AdventureWorksContext())
{
// Fetch all order totals from the database.
var orderAmounts = await context.SalesOrderHeaders.Select(soh => soh.TotalDue).ToListAsync();
// Sum the order totals in memory.
var total = orderAmounts.Sum();
return Ok(total);
}
}
En el ejemplo siguiente se muestra un pequeño problema debido a la forma en que Entity Framework usa LINQ to Entities.
var query = from p in context.Products.AsEnumerable()
where p.SellStartDate < DateTime.Now.AddDays(-7) // AddDays cannot be mapped by LINQ to Entities
select ...;
List<Product> products = query.ToList();
La aplicación está intentando buscar productos con un valor de SellStartDate de más de una semana. En la mayoría de los casos, LINQ to Entities traduciría una cláusula where en una instrucción SQL que la base de datos ejecuta. No obstante, en este caso, LINQ to Entities no puede asignar el método AddDays a SQL. En su lugar, se devuelve cada fila de la tabla Product y los resultados se filtran en la memoria.
La llamada a AsEnumerable es una sugerencia de que hay un problema. Este método convierte los resultados a una interfaz IEnumerable. Aunque IEnumerable admite el filtrado, este se realiza en el cliente, no en la base de datos. De forma predeterminada, LINQ to Entities usa IQueryable, que pasa la responsabilidad del filtrado al origen de datos.
Corrección del antipatrón de recuperación superflua
Evite capturar grandes volúmenes de datos que puedan quedarse obsoletos rápidamente o podrían descartarse, y capture solo los necesarios para realizar la operación.
En lugar de obtener todas las columnas de una tabla y, a continuación, filtrarlas después, seleccione las que necesite de la base de datos.
public async Task<IHttpActionResult> GetRequiredFieldsAsync()
{
using (var context = new AdventureWorksContext())
{
// Project fields as part of the query itself
var result = await context.Products
.Select(p => new ProductInfo {Id = p.ProductId, Name = p.Name})
.ToListAsync();
return Ok(result);
}
}
De igual forma, realice las agregaciones en la base de datos y no en memoria de la aplicación.
public async Task<IHttpActionResult> AggregateOnDatabaseAsync()
{
using (var context = new AdventureWorksContext())
{
// Sum the order totals as part of the database query.
var total = await context.SalesOrderHeaders.SumAsync(soh => soh.TotalDue);
return Ok(total);
}
}
Al utilizar Entity Framework, asegúrese de que las consultas LINQ se resuelven mediante la interfaz IQueryable, no IEnumerable. Puede que tenga que ajustar la consulta para utilizar solo las funciones que se puedan asignar al origen de datos. El ejemplo anterior se puede refactorizar para quitar el método AddDays de la consulta, lo que permite que la base de datos realice el filtrado.
DateTime dateSince = DateTime.Now.AddDays(-7); // AddDays has been factored out.
var query = from p in context.Products
where p.SellStartDate < dateSince // This criterion can be passed to the database by LINQ to Entities
select ...;
List<Product> products = query.ToList();
Consideraciones
En algunos casos, puede mejorar el rendimiento mediante la partición horizontal de los datos. Si diferentes operaciones acceden a atributos distintos de los datos, crear particiones horizontales puede reducir la contención. A menudo, la mayoría de las operaciones se ejecutan en un pequeño subconjunto de los datos, de modo que diseminar esta carga puede mejorar el rendimiento. Consulte Creación de particiones de datos.
Para las operaciones que tienen que admitir consultas sin limitar, implemente la paginación y capture solo un número limitado de entidades a la vez. Por ejemplo, si un cliente está explorando un catálogo de productos, puede mostrar una página de resultados al mismo tiempo.
Cuando sea posible, aproveche las características integradas en el almacén de datos. Por ejemplo, las bases de datos SQL suelen proporcionar funciones de agregado.
Si utiliza un almacén de datos que no es compatible con una función determinada, como la agregación, podría almacenar el resultado calculado en otra parte, actualizar el valor a medida que los registros se agregan o se actualizan, de forma que la aplicación no tenga que volver a calcular el valor cada vez que sea necesario.
Si ve que las solicitudes recuperan un gran número de campos, examine el código fuente para determinar si todos son necesarios. A veces, estas solicitudes son el resultado de una consulta
SELECT *con un diseño inadecuado.De forma similar, las solicitudes que recuperan un gran número de entidades pueden ser un indicio de que la aplicación no filtra los datos correctamente. Compruebe que todas estas entidades sean necesarias. Use el filtrado de la base de datos si es posible, por ejemplo, mediante cláusulas
WHEREde SQL.Descargar el procesamiento en la base de datos no siempre es la mejor opción. Solo puede usar esta estrategia cuando la base de datos se haya diseñado u optimizado para realizar esta acción. La mayor parte de sistemas de base de datos están muy optimizados para determinadas funciones, pero no están diseñados para actuar como motores de aplicaciones de uso general. Para más información, consulte el antipatrón Busy Database.
Detección del antipatrón de recuperación superflua
Algunos síntomas del antipatrón Extraneous Fetching son una latencia elevada y un rendimiento bajo. Si los datos se recuperan de un almacén de datos, también es probable que se dé una mayor contención. Es probable que los usuarios finales informen de tiempos de respuesta prolongados o errores provocados por el agotamiento del tiempo de espera de los servicios. Estos errores podrían devolver errores HTTP 500 (servidor interno) o errores HTTP 503 (servicio no disponible). Examine los registros de eventos del servidor web, que probablemente contengan información más detallada sobre las causas y las circunstancias de los errores.
Tanto los síntomas de este antipatrón como algunos de los datos telemetría obtenidos podrían ser muy similares a los del antipatrón Monolithic Persistence.
Puede realizar los pasos siguientes para ayudar a identificar la causa:
- Identifique las cargas de trabajo o transacciones lentas realizando pruebas de carga, supervisando los procesos o con otros métodos de captura de datos de instrumentación.
- Observe los patrones de comportamiento mostrados por el sistema. ¿Hay límites determinados en cuanto a transacciones por segundo o en el volumen de los usuarios?
- Ponga en correlación las instancias de las cargas de trabajo de baja velocidad con los patrones de comportamiento.
- Identifique los almacenes de datos que se van a usar. Para cada origen de datos, ejecute una telemetría de nivel inferior para observar el comportamiento de las operaciones.
- Identifique las consultas de ejecución lenta que hacen referencia a estos orígenes de datos.
- Realice un análisis específico de los recursos de las consultas de ejecución lenta y determine cómo se usan y consumen los datos.
Busque alguno de estos síntomas:
- Solicitudes de E/S frecuentes y grandes realizadas en el mismo almacén de datos o de recursos.
- Contención en un almacén de datos o un recurso compartido.
- Una operación que reciba con frecuencia grandes volúmenes de datos a través de la red.
- Aplicaciones y servicios que empleen mucho tiempo esperando a que las operaciones de E/S se completen.
Diagnóstico de ejemplo
En las secciones siguientes se aplican estos pasos a los ejemplos anteriores.
Identificación de las cargas de trabajo de baja velocidad
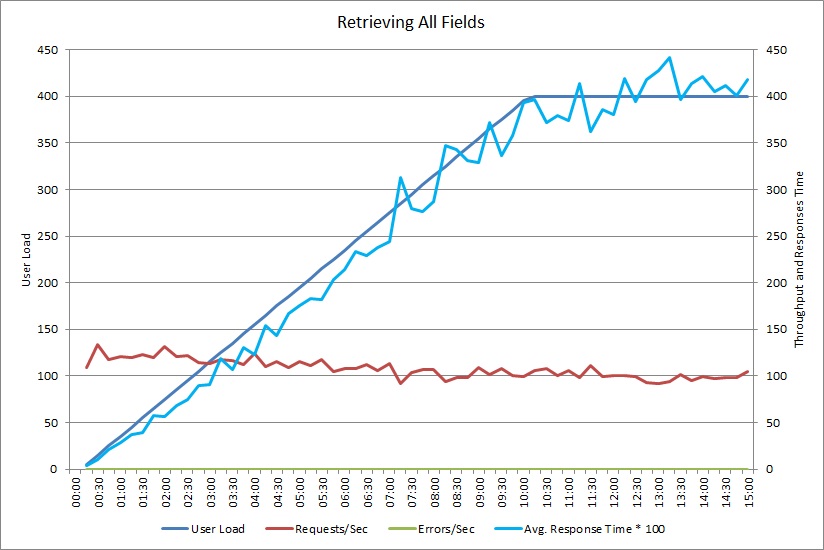
Este gráfico muestra los resultados de rendimiento de una prueba de carga que simula hasta 400 usuarios que ejecutan simultáneamente el método GetAllFieldsAsync mostrado anteriormente. El rendimiento disminuye lentamente a medida que aumenta la carga. El tiempo promedio de respuesta aumenta cuando aumenta la carga de trabajo.
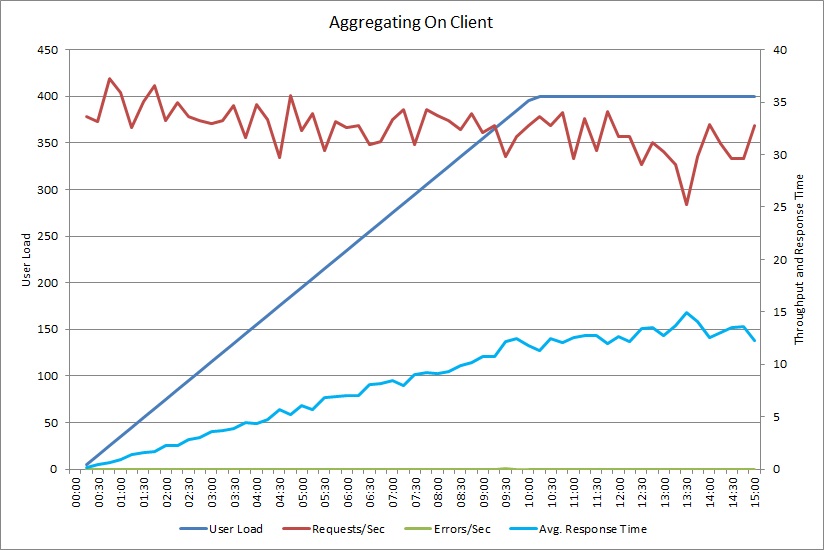
Una prueba de carga para la operación AggregateOnClientAsync muestra un patrón similar. El volumen de solicitudes es razonablemente estable. El tiempo promedio de respuesta aumenta la carga de trabajo, aunque más lentamente que en el gráfico anterior.
Ponga en correlación de las cargas de trabajo de baja velocidad con los patrones de comportamiento
La correlación entre períodos regulares de uso elevado y una disminución del rendimiento pueden indicar áreas problemáticas. Examine detenidamente el perfil de rendimiento de la funcionalidad que parece ejecutarse con lentitud, para determinar si coincide con las pruebas de carga realizadas anteriormente.
Realice la prueba de carga de la misma funcionalidad con cargas de usuario paso a paso, para buscar el punto donde el rendimiento disminuye de forma significativa o se colapsa por completo. Si ese punto cae dentro de los límites de su uso real esperado, examine cómo se implementa la funcionalidad.
Un funcionamiento lento no es necesariamente un problema, si no ocurre cuando el sistema está bajo presión, en un momento crítico y no afecta negativamente al rendimiento de otras operaciones importantes. Por ejemplo, generar estadísticas de funcionamiento mensuales podría ser una operación de ejecución prolongada, pero probablemente se pueda realizar como un proceso por lotes y ejecutarse como un trabajo de prioridad baja. Por otro lado, que los clientes consulten el catálogo de productos es una operación esencial para el negocio. Céntrese en la telemetría generada por estas operaciones críticas para ver cómo varía el rendimiento durante los períodos de uso elevado.
Identificación de los orígenes de datos en las cargas de trabajo de baja velocidad
Si sospecha que un servicio está teniendo un rendimiento bajo debido al modo en que recupera los datos, investigue cómo interactúa la aplicación con los repositorios que utiliza. Supervise el sistema real para ver a qué orígenes se tiene acceso durante los períodos de bajo rendimiento.
Para cada origen de datos, instrumente el sistema para capturar lo siguiente:
- La frecuencia con que se tiene acceso a cada almacén de datos.
- El volumen de datos que entran y salen en el almacén de datos.
- La temporalización de estas operaciones, especialmente la latencia de las solicitudes.
- La naturaleza y la frecuencia de los errores que se producen al tener acceso a cada almacén de datos bajo una carga típica.
Compare esta información con el volumen de datos devueltos por la aplicación al cliente. Realice un seguimiento de la relación entre el volumen de datos devueltos por el almacén de datos y el volumen devuelto al cliente. Si hay grandes diferencias, investigue para determinar si la aplicación está recuperando datos que no sean necesarios.
Es posible que pueda capturar estos datos observando el sistema real y siguiendo el ciclo de vida de cada solicitud de usuario, o que pueda modelar una serie de cargas de trabajo sintéticas y ejecutarlas en un sistema de prueba.
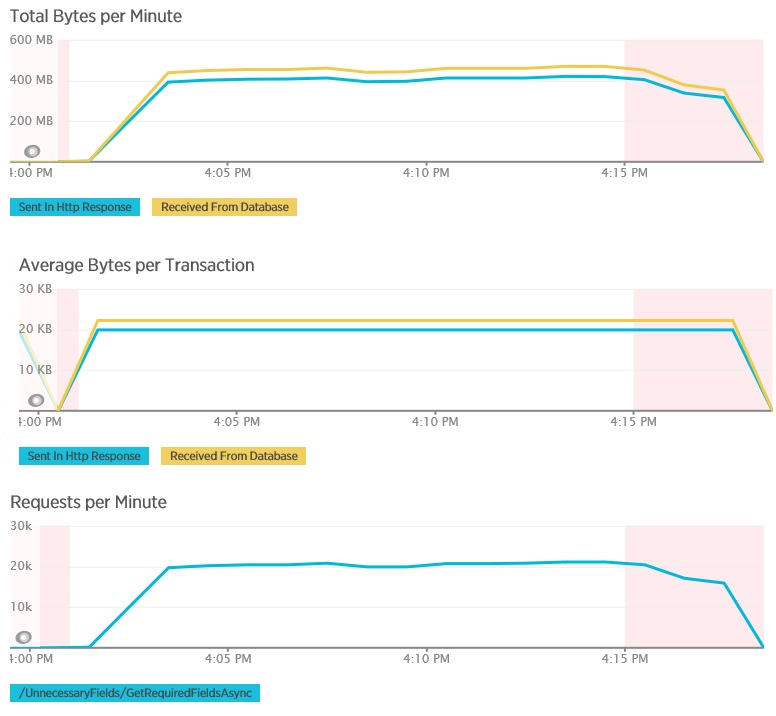
Los gráficos siguientes muestran la telemetría capturada mediante APM de New Relic durante una prueba de carga del método GetAllFieldsAsync. Tenga en cuenta la diferencia entre los volúmenes de los datos recibidos de la base de datos y las respuestas HTTP correspondientes.
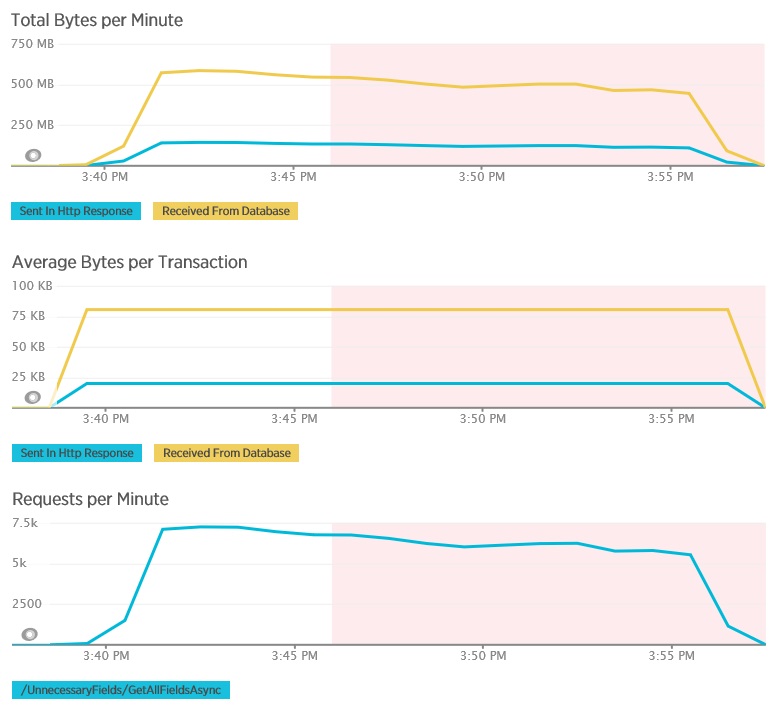
Para cada solicitud, la base de datos devolvió 80 503 bytes, pero la respuesta al cliente solo contenía 19 855 bytes, aproximadamente un 25 % del tamaño de la respuesta de la base de datos. El tamaño de los datos devueltos al cliente puede variar según el formato. Para esta prueba de carga, el cliente solicitó datos JSON. La prueba independiente con XML (que no se muestra) tenía un tamaño de respuesta de 35 655 bytes o el 44 % del tamaño de la respuesta de la base de datos.
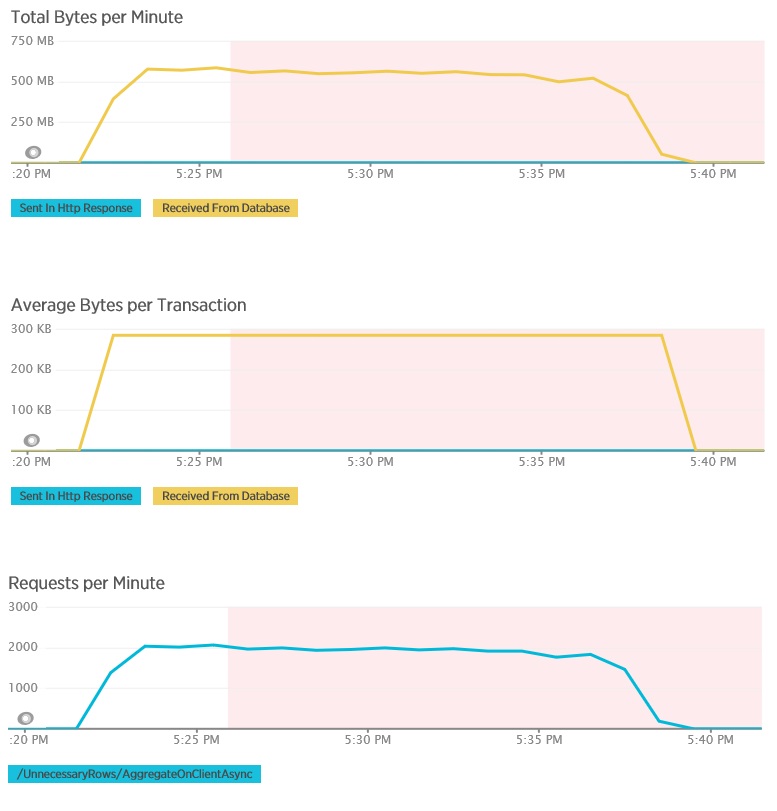
La prueba de carga para el método AggregateOnClientAsync muestra resultados más extremos. En este caso, cada prueba realizó una consulta que recuperó más de 280 Kb de datos de la base de datos, pero la respuesta JSON fue solo de 14 bytes. La amplia disparidad se debe a que el método calcula un resultado total a partir de un gran volumen de datos.
Identificación y análisis de las consultas de baja velocidad
Busque las consultas de base de datos que consuman la mayoría de los recursos y tarden más tiempo en ejecutarse. Puede agregar instrumentación para buscar las horas de inicio y finalización de muchas operaciones de base de datos. Muchos de los almacenes de datos también proporcionan información detallada sobre cómo se realizan y optimizan las consultas. Por ejemplo, el panel Rendimiento de las consultas en el portal de administración de Azure SQL Database permite seleccionar una consulta y ver la información detallada del rendimiento en tiempo de ejecución. Esta es la consulta generada por la operación GetAllFieldsAsync:
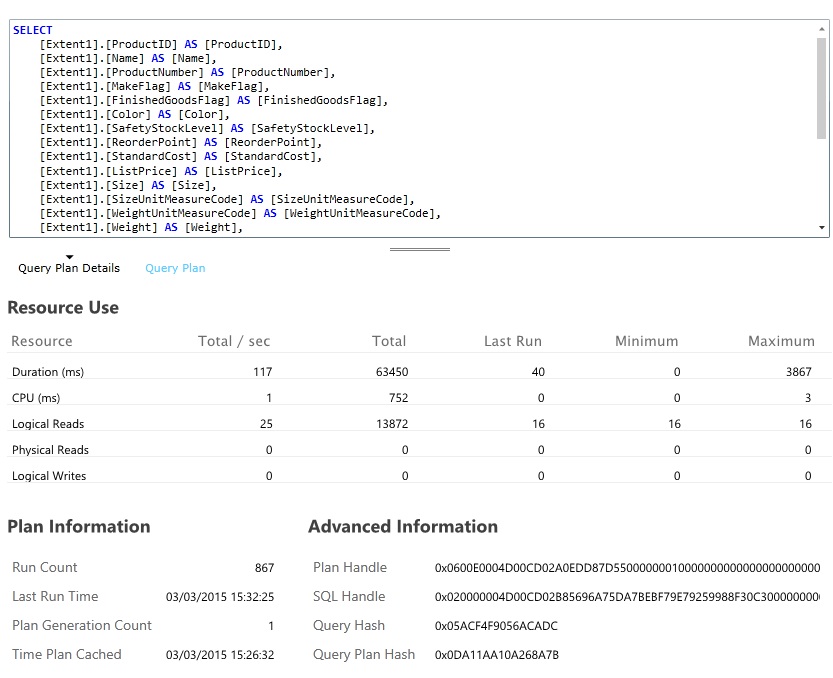
Implementación de la solución y comprobación del resultado
Después de cambiar el método GetRequiredFieldsAsync para utilizar una instrucción SELECT en la base de datos, las pruebas de carga mostraban los resultados siguientes.
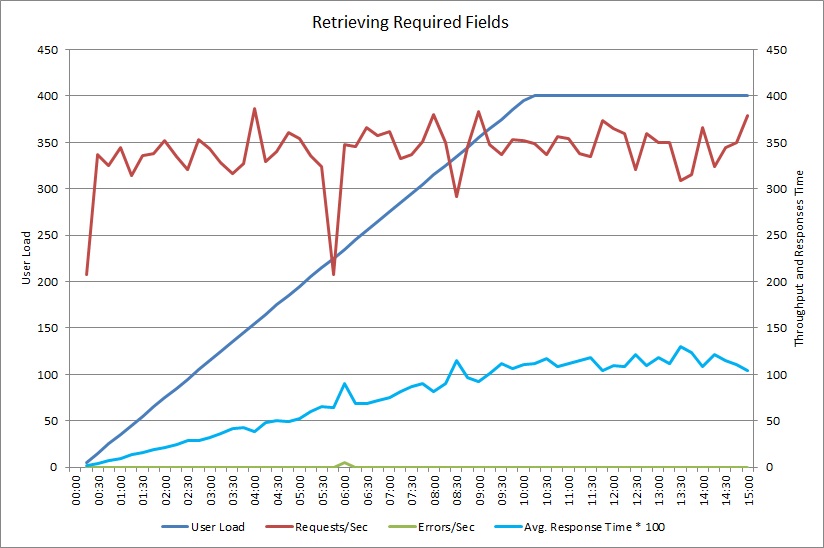
Esta prueba de carga usaba la misma implementación y la misma carga de trabajo simulada de 400 usuarios simultáneos anterior. El gráfico muestra una latencia mucho menor. El tiempo de respuesta aumenta con la carga a aproximadamente 1,3 segundos, en comparación con los 4 segundos del caso anterior. El rendimiento también es superior a 350 solicitudes por segundo, en comparación con los de 100 de antes. El volumen de datos recuperados de la base de datos ahora coincide más con el tamaño de los mensajes de respuesta HTTP.
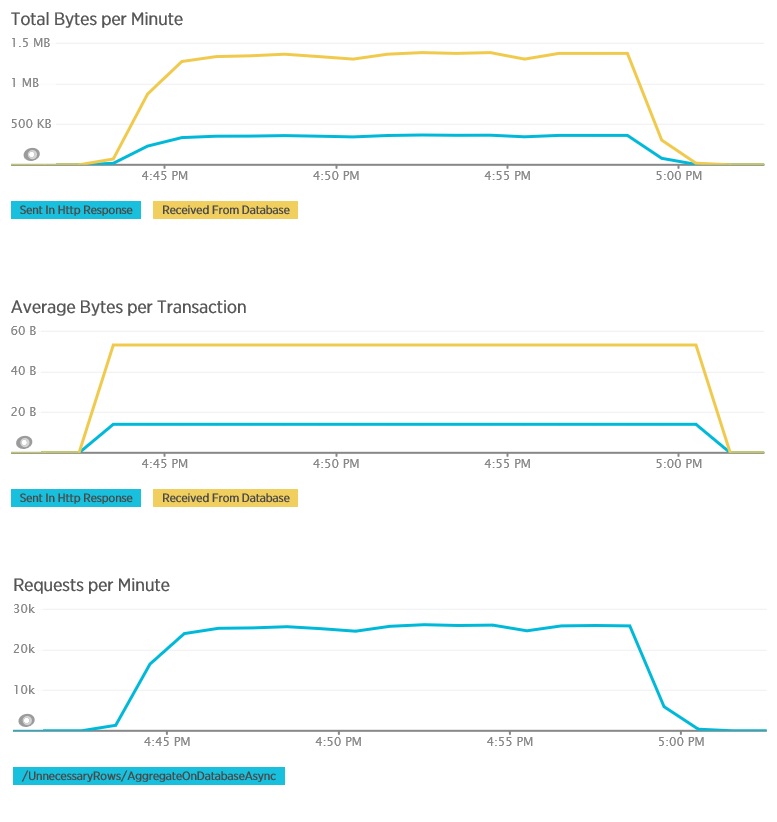
Las pruebas de carga mediante el método AggregateOnDatabaseAsync generan los siguientes resultados:
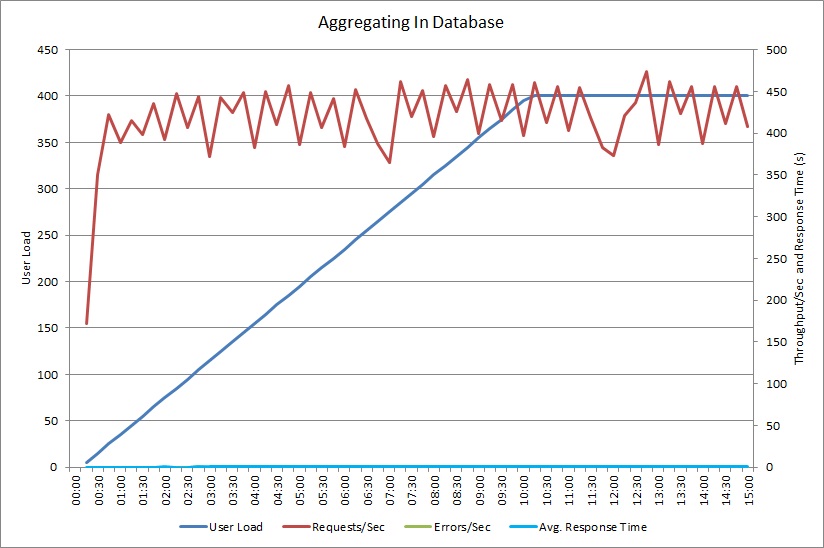
El tiempo de respuesta promedio ahora es mínimo. Se trata de una mejora del orden de magnitud en el rendimiento, provocada principalmente por la gran reducción de las operaciones de E/S desde la base de datos.
Aquí está la telemetría correspondiente para el método AggregateOnDatabaseAsync. La cantidad de datos recuperados de la base de datos se ha reducido considerablemente desde más de 280 Kb por transacción a 53 bytes. Como resultado, la cantidad máxima sostenida de solicitudes por minuto se ha ampliado de alrededor de 2 000 a más de 25 000.
Recursos relacionados
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de