El ciclo de vida del proceso de ciencia de datos en equipo
El Proceso de ciencia de datos en equipo (TDSP) ofrece un ciclo de vida que el equipo puede usar para estructurar los proyectos de ciencia de datos. El ciclo de vida describe los pasos que puede seguir para completar correctamente un proyecto.
Debe usar este ciclo de vida si tiene un proyecto de ciencia de datos que forma parte de una aplicación inteligente. Las aplicaciones inteligentes implementan modelos de Machine Learning o IA para realizar un análisis predictivo. También puede usar este proceso para proyectos de ciencia de datos exploratorios y proyectos de análisis improvisados, pero es posible que no necesite implementar todos los pasos del ciclo de vida.
Su equipo puede combinar el TDSP basado en tareas con otros ciclos de vida de la ciencia de datos, como el proceso estándar intersectorial para la minería de datos (CRISP-DM), el proceso de descubrimiento de conocimientos en bases de datos (KDD) u otro proceso personalizado propio de su organización.
Propósito y credibilidad
El propósito de TDSP es simplificar y estandarizar el enfoque de los proyectos de ciencia de datos e IA. Microsoft ha aplicado esta metodología estructurada en cientos de proyectos. Los investigadores estudiaron el TDSP y publicaron sus hallazgos en la documentación revisada por expertos. El marco arquitectónico del TDSP se ha probado a fondo y ha demostrado su eficacia en muchos ámbitos.
Cinco fases del ciclo de vida
El ciclo de vida de TDSP se compone de cinco fases principales que el equipo ejecuta de forma iterativa. Estas fases incluyen:
- Conocimiento del negocio
- Adquisición y comprensión de los datos
- Modelado
- Implementación
- Aceptación del cliente
Esta es una representación visual del ciclo de vida de TDSP:
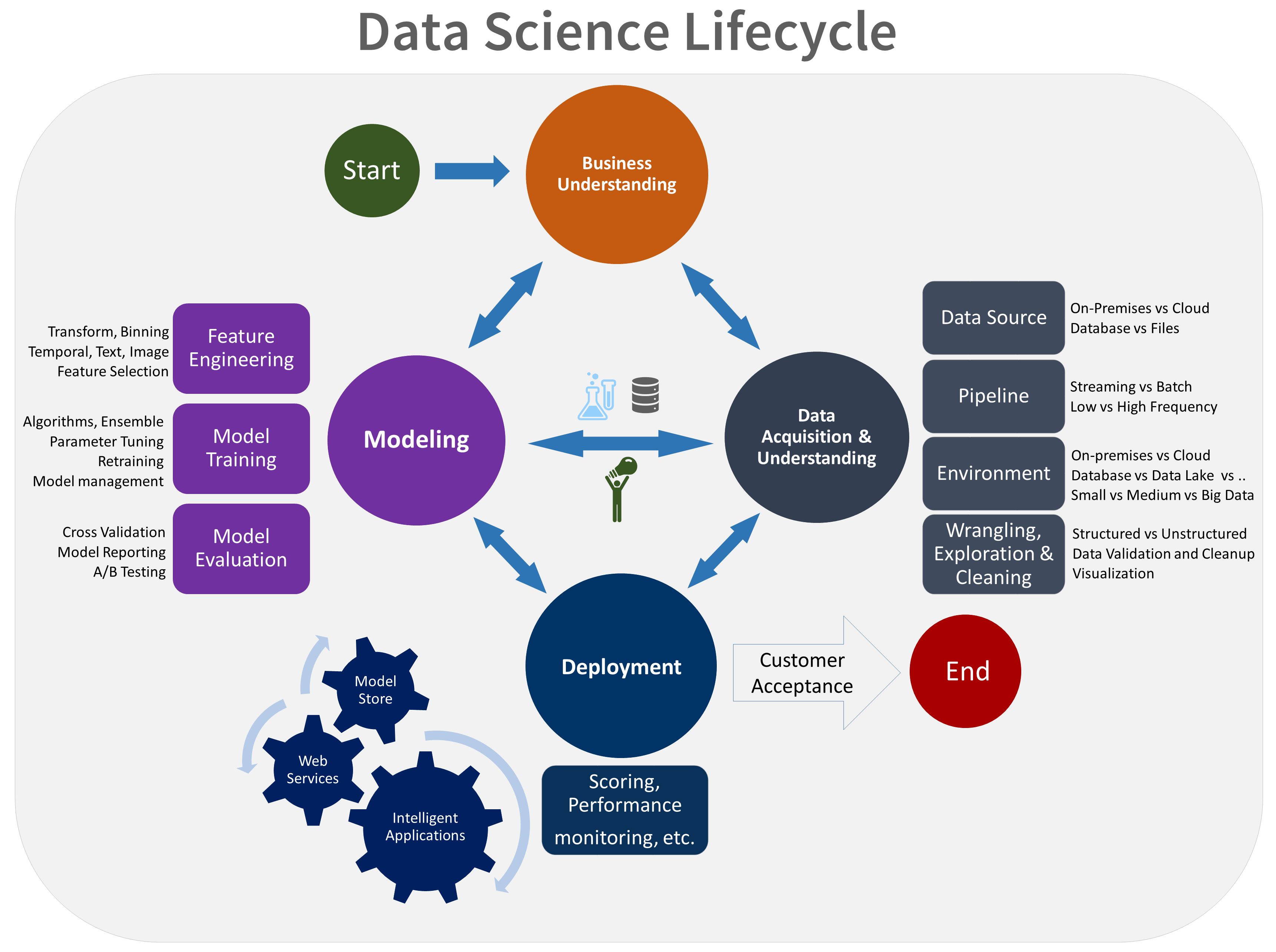
El ciclo de vida del TDSP es una secuencia de pasos que proporcionan instrucciones para crear modelos predictivos. El equipo implementa modelos de predicción en un entorno de producción que tiene previsto utilizar para crear aplicaciones inteligentes. El objetivo del ciclo de vida de este proceso consiste en hacer avanzar un proyecto de ciencia de datos hacia un punto final de interacción claro. La ciencia de datos es un ejercicio de investigación y detección. Cuando se usa un proceso bien definido para comunicar tareas al equipo, aumenta la posibilidad de llevar a cabo correctamente un proyecto de ciencia de datos.
Cada fase tiene su propio artículo que describe:
- Objetivos: los objetivos de la fase.
- Cómo hacerlo: un resumen de las tareas que realiza en la etapa y orientación sobre cómo completarlas.
- Artefactos: los resultados que necesita generar durante la fase y los recursos que puede usar para ayudarle a crearlos.
Citas revisadas por expertos
Los investigadores publican documentación revisada por expertos sobre el TDSP. Revise el siguiente material para investigar las aplicaciones y características de TDSP.
Ingeniería de software para Machine Learning: Caso práctico (páginas 291-300)
Un ciclo de vida de inteligencia artificial: de la concepción a la producción
Administración de artefactos del ciclo de vida de Machine Learning: una encuesta (páginas 18–35)
Construcción de un modelo de calidad para sistemas de aprendizaje automático (páginas 307–335)
Colaboradores
Microsoft mantiene este artículo. Originalmente lo escribieron los siguientes colaboradores.
Autor principal:
- Mark Tabladillo | Arquitecto sénior de soluciones en la nube
Para ver los perfiles no públicos de LinkedIn, inicie sesión en LinkedIn.
Recursos relacionados
- Para la primera fase del ciclo de vida, consulte Descripción empresarial.
- ¿Qué es el Proceso de ciencia de datos en equipo (TDSP)?
- Comparación de productos y tecnologías de aprendizaje automático de Microsoft
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de