Fase de modelado del ciclo de vida del proceso de ciencia de datos en equipos
En este artículo se describen los objetivos, las tareas y los resultados asociados a la fase de modelado del Proceso de ciencia de datos en equipo (TDSP). Este proceso proporciona un ciclo de vida recomendado que el equipo puede usar para estructurar los proyectos de ciencia de datos. El ciclo de vida describe las fases principales que realiza el equipo, a menudo iterativamente:
- Conocimiento del negocio
- Adquisición y comprensión de los datos
- Modelado
- Implementación
- Aceptación del cliente
Esta es una representación visual del ciclo de vida de TDSP:
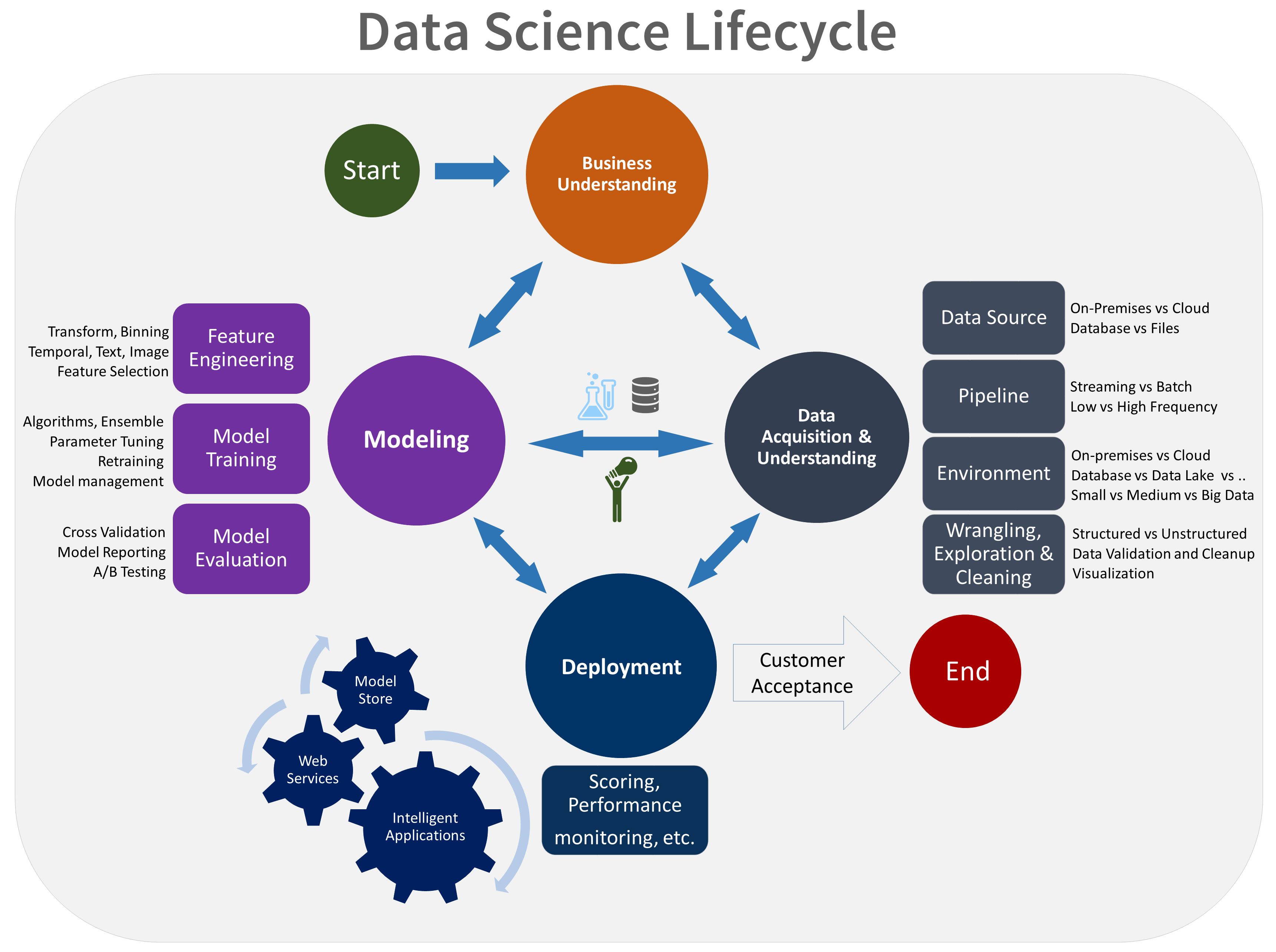
Objetivos
Los objetivos de la fase de modelado son:
Determinar las características óptimas de los datos para el modelo de aprendizaje automático.
Crear un modelo de aprendizaje automático informativo que predice el objetivo con la máxima precisión.
Crear un modelo de aprendizaje automático que es adecuado para entornos de producción.
Cómo completar las tareas
La fase de modelado tiene tres tareas principales:
Diseño de características: cree características de datos a partir de los datos sin procesar para facilitar el entrenamiento del modelo.
Entrenamiento del modelo: busque el modelo que responda a la pregunta con la máxima precisión comparando sus métricas de éxito.
Evaluación del modelo: determine si el modelo es adecuado para su uso en producción.
Ingeniería de características
El diseño de características consiste en incluir, agregar y transformar variables sin procesar para crear las características que se utilizan en el análisis. Si desea obtener información sobre cómo se compila un modelo, debe estudiar las características subyacentes del modelo.
Este paso requiere una combinación creativa de experiencia de dominio y de los conocimientos obtenidos en el paso de exploración de datos. La ingeniería de características es un acto de equilibrio de buscar e incluir variables informativas evitando al mismo tiempo que se utilicen demasiadas variables no relacionadas. Las variables informativas mejoran el resultado. Las variables no relacionadas introducen ruido innecesario en el modelo. También debe generar estas características para los nuevos datos obtenidos durante la puntuación. Así pues, la generación de estas características solamente puede depender de los datos que están disponibles en el momento de la puntuación.
Entrenamiento del modelo
Según el tipo de la pregunta que intenta responder, existen muchos algoritmos de modelado que puede usar. Para obtener instrucciones sobre cómo elegir un algoritmo precompilado, consulte Hoja de referencia rápida del algoritmo de Machine Learning para el diseñador de Azure Machine Learning. Otros algoritmos están disponibles a través de paquetes de código abierto en R o Python. Aunque este se centra en Azure Machine Learning, la orientación resulta útil para muchos proyectos de aprendizaje automático.
El proceso de entrenamiento del modelo incluye los pasos siguientes:
Dividir los datos de entrada aleatoriamente para el modelado en un conjunto de datos de aprendizaje y un conjunto de datos de prueba.
Compilar los modelos mediante el conjunto de datos de aprendizaje.
Evaluar el entrenamiento y el conjunto de datos de prueba. Use una serie de algoritmos de aprendizaje automático competitivos. Utilice varios parámetros de ajuste asociados (conocidos como barridos de parámetros) que estén orientados a responder a la pregunta de interés con los datos actuales.
Determinar la mejor solución para responder a la pregunta mediante la comparación de las métricas de éxito entre los métodos alternativos.
Para obtener más información, consulte Entrenamiento de modelos con Machine Learning.
Nota:
Evitar fugas: puede provocar la fuga de datos si incluye datos ajenos al conjunto de datos de aprendizaje que permiten que un modelo o algoritmo de aprendizaje automático haga predicciones demasiado buenas para ser realistas. La pérdida de datos es uno de los motivos por los que los científicos de datos se preocupan cuando obtienen resultados predictivos que parecen demasiado buenos para ser ciertos. Estas dependencias pueden ser difíciles de detectar. Para evitar fugas, a menudo es preciso efectuar iteraciones entre la generación del conjunto de datos de análisis, la creación del modelo y la evaluación de la precisión de los resultados.
Evaluación del modelo
Después de entrenar el modelo, un científico de datos de su equipo se centra en la evaluación del modelo.
Realización de una determinación: evalúe si el modelo funciona suficientemente para producción. Algunas preguntas clave son:
¿El modelo responde a la pregunta con la confianza suficiente considerando los datos de prueba?
¿Debe probar algún planteamiento alternativo?
¿Debe recopilar más datos, realizar más ingeniería de características o experimentar con otros algoritmos?
Interpretación del modelo: use el SDK de Python de Machine Learning para realizar las siguientes tareas:
Explicar el comportamiento completo del modelo o predicciones individuales en el equipo personal de forma local.
Habilitar técnicas de interpretación para las características diseñadas.
Explicar el comportamiento completo del modelo y predicciones individuales en Azure.
Cargar las explicaciones en el historial de ejecución de Machine Learning.
Usar un panel de visualización para interactuar con las explicaciones del modelo, tanto en un cuaderno de Jupyter Notebook como en el área de trabajo de Machine Learning.
Implementar un explicador de puntuaciones junto con el modelo para observar las explicaciones durante la inferencia.
Evaluación de la equidad: use el paquete de Python de código abierto de equidad con Machine Learning para realizar las siguientes tareas:
Evalúe la equidad de las predicciones del modelo. Este proceso ayuda a su equipo a obtener más información sobre la equidad en el aprendizaje automático.
Cargue, enumere y descargue información de evaluación de equidad desde y hacia Machine Learning Studio.
Consulte el panel de evaluación de equidad en Machine Learning Studio para interactuar con la información de equidad de los modelos.
Integración con MLflow
Machine Learning se integra con MLflow para admitir el ciclo de vida de modelado. Usa el seguimiento de MLflow para experimentos, implementación de proyectos, administración de modelos y un registro de modelos. Esta integración garantiza un flujo de trabajo de aprendizaje automático sin problemas y eficiente. Las siguientes características de Machine Learning ayudan a admitir este elemento del ciclo de vida de modelado:
Seguimiento de experimentos: la funcionalidad principal de MLflow se usa ampliamente en la fase de modelado para realizar un seguimiento de varios experimentos, parámetros, métricas y artefactos.
Implementación de proyectos: el empaquetado de código con proyectos de MLflow garantiza ejecuciones coherentes y un fácil uso compartido entre los miembros del equipo, lo que es esencial durante el desarrollo de modelos iterativos.
Administración de modelos: la administración y el control de versiones de los modelos es fundamental en esta fase a medida que se crean, evalúan y ajustan diferentes modelos.
Registro de modelos: el registro de modelos se usa para el control de versiones y la administración de modelos a lo largo de su ciclo de vida.
Documentación revisada por expertos
Los investigadores publican estudios sobre el TDSP en la documentación revisada por expertos. Las citas proporcionan una oportunidad para investigar otras aplicaciones o ideas similares al TDSP, incluida la fase del ciclo de vida de modelado.
Colaboradores
Microsoft mantiene este artículo. Originalmente lo escribieron los siguientes colaboradores.
Autor principal:
- Mark Tabladillo | Arquitecto sénior de soluciones en la nube
Para ver los perfiles no públicos de LinkedIn, inicie sesión en LinkedIn.
Recursos relacionados
En estos artículos se describen las demás fases del ciclo de vida del TDSP:
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de