En este artículo se describe un enfoque alternativo a los proyectos de almacenamiento de datos que se denomina análisis exploratorio de datos (EDA). Este enfoque puede reducir los desafíos de las operaciones de extracción, transformación y carga (ETL). Se centra en primer lugar en la generación de información empresarial y, a continuación, pasa a resolver las tareas de modelado y ETL.
Architecture

Descargue un archivo Visio de esta arquitectura.
En el caso del EDA, solo le preocupa la parte derecha del diagrama. Azure Synapse SQL sin servidor se usa como motor de proceso sobre los archivos de lago de datos.
Para realizar el EDA:
- Las consultas T-SQL se ejecutan directamente en Azure Synapse SQL sin servidor o Azure Synapse Spark.
- Las consultas se ejecutan desde una herramienta gráfica de consulta como Power BI o Azure Data Studio.
Se recomienda conservar todos los datos de lago de datos mediante Parquet o Delta.
Puede implementar el lado izquierdo del diagrama (ingesta de datos) mediante cualquier herramienta de extracción, carga y transformación (ELT). No tiene ningún efecto en el EDA.
Componentes
Azure Synapse Analytics combina integración de datos, almacenamiento de datos empresariales y análisis de macrodatos sobre datos de lago de datos. En esta solución:
- Un área de trabajo de Azure Synapse promueve la colaboración entre ingenieros de datos, científicos de datos, analistas de datos y profesionales de inteligencia empresarial (BI) para las tareas del EDA.
- Los grupos de SQL sin servidor de Azure Synapse analizan datos no estructurados y semiestructurados en Azure Data Lake Storage mediante el uso de T-SQL estándar.
- Los grupos de Apache Spark sin servidor de Azure Synapse hacen exploraciones de Code First en Data Lake Storage con lenguajes de Spark, como Spark SQL, PySpark y Scala.
Azure Data Lake Storage proporciona almacenamiento para los datos que luego son analizados por grupos de SQL sin servidor de Azure Synapse.
Azure Machine Learning proporciona datos para Azure Synapse Spark.
Power BI se usa en esta solución para consultar datos y cumplir con el EDA.
Alternativas
Puede reemplazar o complementar grupos de Synapse SQL sin servidor con Azure Databricks.
En lugar de usar un modelo de lago de datos con grupos de Synapse SQL sin servidor, puede usar grupos de SQL dedicados de Azure Synapse para almacenar datos empresariales. Revise los casos de uso y las consideraciones de este artículo y los recursos relacionados para decidir qué tecnología utilizar.
Detalles del escenario
Esta solución muestra una implementación del enfoque EDA para los proyectos de almacenamiento de datos. Este enfoque puede reducir los desafíos de las operaciones ETL. Se centra en primer lugar en la generación de información empresarial y, luego, pasa a resolver las tareas de modelado y ETL.
Posibles casos de uso
Otros escenarios que pueden beneficiarse de este patrón de análisis son:
Análisis prescriptivos. Realice preguntas sobre los datos, como Next Best Action (Siguiente mejor acción) o what do we do next? (¿Qué hacemos a continuación?). Use los datos para guiarse más por ellos y menos por su instinto. Los datos podrían no estar estructurados y proceder de muchos orígenes externos de distinta calidad. Quizá quiera usar los datos lo más rápido posible para evaluar su estrategia empresarial sin cargar realmente los datos en un almacenamiento de datos. Puede eliminar los datos después de responder a sus preguntas.
Autoservicio de ETL. Efectúe la ETL/ELT al realizar las actividades de espacio aislado de datos (EDA). Transforme los datos para que sean más útiles. Esto puede mejorar la escala de los desarrolladores de ETL.
Acerca de los análisis de datos exploratorios
Antes de ver con más atención cómo funciona el EDA, merece la pena resumir el enfoque tradicional de los proyectos de almacenamiento de datos. El enfoque tradicional tiene este aspecto:
Reunión de requisitos. Documente qué hacer con los datos.
Modelado de datos. Determine cómo modelar los datos numéricos y de atributo en tablas de hechos y dimensiones. Tradicionalmente, este paso se hace antes de adquirir los nuevos datos.
ETL. Adquiera los datos y acomódelos en el modelo de datos del almacenamiento de datos.
Estos pasos pueden tardar semanas o incluso meses. Solo entonces puede empezar a consultar los datos y resolver el problema empresarial. El usuario solo ve el valor después de crear los informes. Normalmente, la arquitectura de la solución tiene un aspecto similar al siguiente:
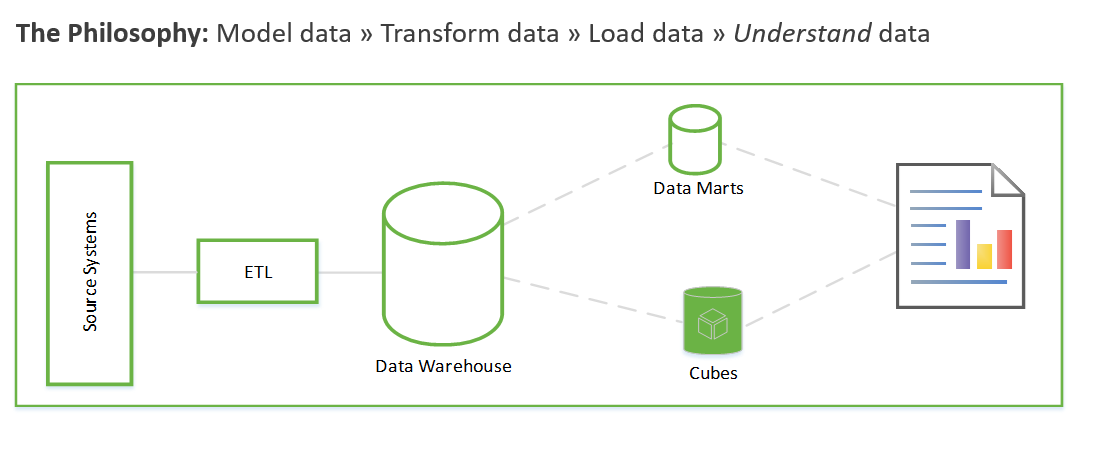
Puede hacerlo de otra manera que se centre en primer lugar en la generación de información empresarial y, a continuación, pasa a resolver las tareas de modelado y ETL. El proceso es similar a los procesos de ciencia de datos. Se parece a lo siguiente:
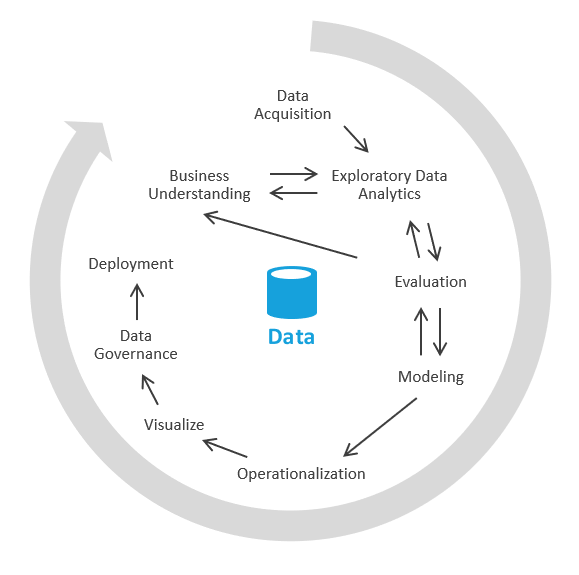
En el sector, este proceso se denomina EDAo análisis exploratorio de datos.
Estos son los pasos que debe realizar:
Adquisición de datos. En primer lugar, debe determinar qué orígenes de datos necesita ingerir en el lago de datos o espacio aislado. A continuación, debe llevar esos datos al área de aterrizaje del lago. Azure proporciona herramientas como Azure Data Factory y Azure Logic Apps que pueden ingerir datos rápidamente.
Espacio aislado de datos. Inicialmente, trabajan en conjunto un analista de negocios y un ingeniero experto en análisis de datos exploratorios a través de Azure Synapse Analytics sin servidor o SQL básico. Durante esta fase, están intentando descubrir la información empresarial mediante los nuevos datos. El EDA es un proceso iterativo. Es posible que tenga que ingerir más datos, hablar con los SME, hacer más preguntas o generar visualizaciones.
Evaluación. Después de encontrar la información empresarial, debe evaluar qué hacer con los datos. Es posible que quiera conservar los datos en el almacenamiento de datos (por lo que debe pasar a la fase de modelado). En otros casos, puede decidir mantener los datos en el lago de datos y usarlos para el análisis predictivo (algoritmos de aprendizaje automático). En otros casos, puede decidir reposición de los sistemas de registro con la nueva información. En función de estas decisiones, puede comprender mejor lo que debe hacer a continuación. Es posible que no necesite realizar la ETL.
Estos métodos son el núcleo del verdadero análisis de autoservicio. Al utilizar el lago de datos y una herramienta de consulta como Azure Synapse sin servidor que comprende los patrones de consulta del lago de datos, puede poner sus recursos de datos en manos de empresarios que entiendan un mínimo de SQL. Puede reducir drásticamente el tiempo de creación de valor mediante este método y eliminar parte del riesgo asociado a las iniciativas de datos corporativos.
Consideraciones
Estas consideraciones implementan los pilares del marco de buena arquitectura de Azure, que es un conjunto de principios guía que se pueden usar para mejorar la calidad de una carga de trabajo. Para más información, consulte Marco de buena arquitectura de Microsoft Azure.
Disponibilidad
Los grupos de Azure Synapse SQL sin servidor son una característica de plataforma como servicio (PaaS) que puede satisfacer los requisitos de alta disponibilidad y recuperación ante desastres.
Los grupos sin servidor están disponibles a petición. No requieren escalar verticalmente/horizontalmente ni reducir verticalmente/horizontalmente, ni administración de ningún tipo. Usan un modelo de pago por consulta, por lo que no hay capacidad sin usar en ningún momento. Los grupos sin servidor son ideales para:
- Exploraciones de ciencia de datos ad hoc en T-SQL.
- Creación temprana de prototipos para entidades de almacenamiento de datos.
- Definición de vistas que los consumidores pueden usar, por ejemplo en Power BI, para escenarios que pueden tolerar el retardo de rendimiento.
- Análisis de datos exploratorios.
Operations
Synapse SQL sin servidor usa T-SQL estándar para realizar consultas y operaciones. Puede usar la interfaz de usuario del área de trabajo de Synapse, Azure Data Studio o SQL Server Management Studio como herramienta T-SQL.
Optimización de costos
La optimización de costos trata de buscar formas de reducir los gastos innecesarios y mejorar las eficiencias operativas. Para más información, vea Información general del pilar de optimización de costos.
Los precios de Data Lake Storage dependen de la cantidad de datos que almacene y de la frecuencia con la que los use. Los precios de ejemplo incluyen 1 TB de datos almacenados, con más suposiciones transaccionales. 1 TB hace referencia al tamaño del lago de datos, no al tamaño original de la base de datos heredada.
El grupo de Spark de Azure Synapse basa los precios en el tamaño del nodo, el número de instancias y el tiempo de actividad. En el ejemplo se supone que hay un nodo de ejecución pequeño con un uso entre 5 horas por semana y 40 horas al mes.
El grupo de SQL sin servidor de Azure Synapse basa los precios en TB de bases de datos procesadas. En el ejemplo se supone que se procesan 50 TB al mes. Esta cifra hace referencia al tamaño del lago de datos, no al tamaño original de la base de datos heredada.
Colaboradores
Microsoft está actualizando y manteniendo este artículo. Originalmente lo escribieron los siguientes colaboradores.
Creadores de entidad de seguridad:
- Dave Wentzel | Arquitecto técnico principal de MTC
Pasos siguientes
- Rutas de aprendizaje para Ingenieros de datos
- Tutorial: Introducción a Azure Synapse Analytics
- Creación de una base de datos única: Azure SQL Database
- Arquitectura de SQL de Azure Synapse
- Creación de una cuenta de almacenamiento para su uso con Azure Data Lake Storage
- Inicio rápido de Azure Event Hubs: Creación de un centro de eventos mediante Azure Portal
- Inicio rápido: Creación de un trabajo de Stream Analytics mediante Azure Portal
- Inicio rápido: Introducción a Azure Machine Learning