Migración de Apache Kafka a Azure
Apache Kafka es un sistema de mensajería distribuida altamente escalable y tolerante a errores que implementa una arquitectura de publicación y suscripción. Se usa como una capa de ingesta en escenarios de streaming en tiempo real, como Internet de las cosas y sistemas de supervisión de registros en tiempo real. También se usa cada vez más como el almacén de datos inmutable de solo anexión en arquitecturas kappa.
Apache®, Apache Spark®, Apache Hadoop®, Apache HBase, Apache Storm®, Apache Sqoop®, Apache Kafka® y el logotipo de llama son marcas comerciales registradas o marcas comerciales de Apache Software Foundation en Estados Unidos y/o en otros países. El uso de estas marcas no implica ninguna aprobación de The Apache Software Foundation.
Enfoque de migración
En este artículo se presentan varias estrategias para migrar Kafka a Azure:
- Migración de Kafka a la infraestructura como servicio (IaaS) de Azure
- Migración de Kafka a Azure Event Hubs para Kafka
- Migración de Kafka en Azure HDInsight
- Uso de Azure Kubernetes Service (AKS) con Kafka en HDInsight
- Uso de Kafka en AKS con el operador Strimzi
Este es un diagrama de flujo de decisión para decidir qué estrategia usar.
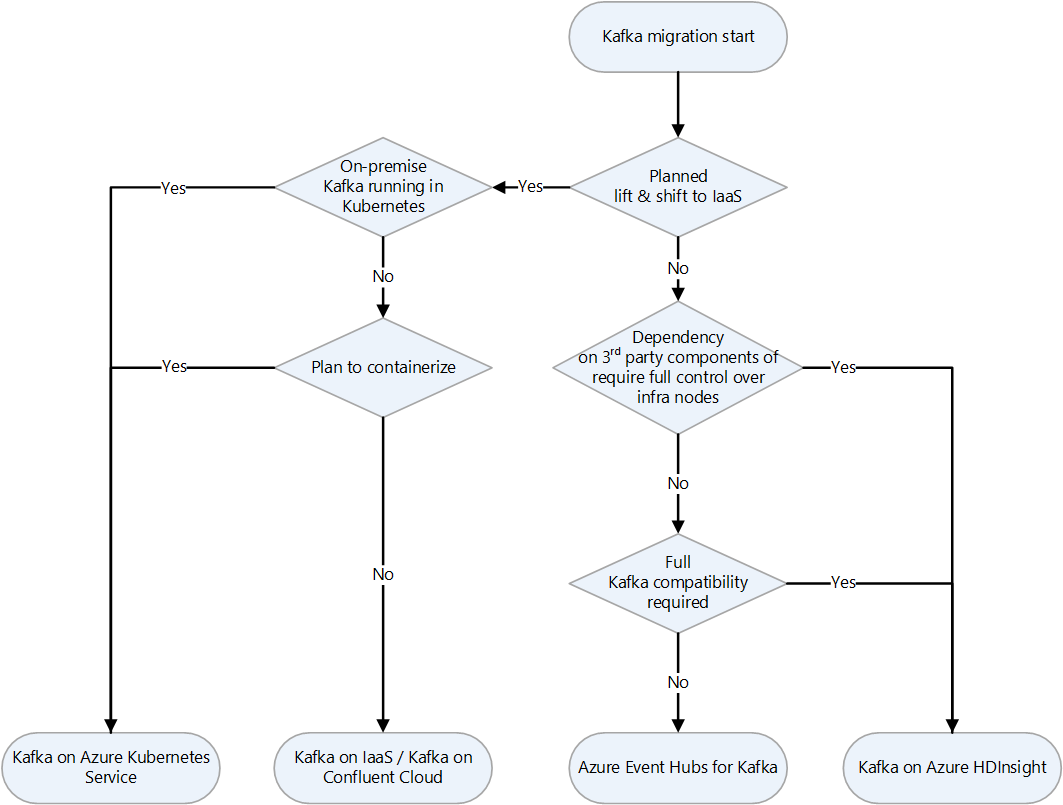
Migración de Kafka a IaaS de Azure
Para obtener una manera de migrar Kafka a IaaS de Azure, consulte Kafka en máquinas virtuales Ubuntu.
Migración de Kafka a Event Hubs para Kafka
Event Hubs proporciona un punto de conexión compatible con las API de consumidor y productor de Apache Kafka. La mayoría de las aplicaciones cliente de Apache Kafka pueden usar este punto de conexión, por lo que puede usarla como alternativa a ejecutar un clúster de Kafka en Azure. El punto de conexión admite clientes que usan las versiones de API 1.0 y versiones posteriores. Para más información sobre esta característica, consulte Introducción a Event Hubs para Apache Kafka.
Para obtener información sobre cómo migrar las aplicaciones de Apache Kafka para usar Event Hubs, consulte Migración a event Hubs para ecosistemas de Apache Kafka.
Características de Kafka y Event Hubs
| Similitudes entre Kafka y Event Hubs | Diferencias en Kafka y Event Hubs |
|---|---|
| Uso de particiones | Plataforma como servicio frente a software |
| Las particiones son independientes | Partición |
| Uso de un concepto de cursor del lado cliente | APIs (Interfaz de Programación de Aplicaciones) |
| Se puede escalar a cargas de trabajo muy altas. | Tiempo de ejecución |
| Conceptualmente casi idéntico | Protocolos |
| Tampoco usa el protocolo HTTP para recibir | Durabilidad |
| Seguridad | |
| Limitaciones |
Diferencias de creación de particiones
| Kafka | Event Hubs |
|---|---|
| El recuento de particiones administra la escala. | Las unidades de rendimiento administran la escala. |
| Debe equilibrar la carga de particiones entre máquinas. | El equilibrio de carga es automático. |
| Debe volver a particionar manualmente mediante división y combinación. | No es necesario volver a particionar. |
Diferencias de durabilidad
| Kafka | Event Hubs |
|---|---|
| Volátil de forma predeterminada | Siempre duradero |
| Replicado después de recibir una confirmación (ACK) | Replicado antes de enviar un ACK |
| Depende del disco y el cuórum | Proporcionado por el almacenamiento |
Diferencias de seguridad
| Kafka | Event Hubs |
|---|---|
| Capa de sockets seguros (SSL) y capa de autenticación y seguridad simple (SASL) | Firma de acceso compartido (SAS) y SASL o PLAIN RFC 4618 |
| Listas de control de acceso similares a archivos | Política |
| Cifrado de transporte opcional | Seguridad obligatoria de la capa de transporte (TLS) |
| Basado en el usuario | Basado en tokens (ilimitado) |
Otras diferencias
| Kafka | Event Hubs |
|---|---|
| No limita | Admite la limitación |
| Usa un protocolo propietario | Usa el protocolo AMQP 1.0 |
| No usa HTTP para enviar | Usa envío HTTP y envío por lotes |
Migración de Kafka en HDInsight
Puede migrar Kafka a Kafka en HDInsight. Para más información, consulte ¿Qué es Apache Kafka en HDInsight?.
Uso de AKS con Kafka en HDInsight
Para más información, consulte Uso de AKS con Apache Kafka en HDInsight.
Uso de Kafka en AKS con el operador Strimzi
Para más información, consulte Implementación de un clúster de Kafka en AKS mediante Strimzi.
Migración de datos de Kafka
Puede usar la herramienta MirrorMaker de Kafka para replicar temas de un clúster a otro. Esta técnica puede ayudarle a migrar datos después de aprovisionar un clúster de Kafka. Para más información, consulte Uso de MirrorMaker para replicar temas de Apache Kafka con Kafka en HDInsight.
El siguiente enfoque de migración usa la creación de reflejo:
Mueva primero a los productores. Al migrar los productores, se evita la producción de nuevos mensajes en el origen de Kafka.
Una vez que kafka de origen consume todos los mensajes restantes, puede migrar los consumidores.
La implementación incluye los pasos siguientes:
Cambie la dirección de conexión de Kafka del cliente productor para que apunte a la nueva instancia de Kafka.
Reinicie los servicios empresariales del productor y envíe nuevos mensajes a la nueva instancia de Kafka.
Espere a que se consuman los datos del origen de Kafka.
Cambie la dirección de conexión de Kafka del cliente de consumidor para que apunte a la nueva instancia de Kafka.
Reinicie los servicios empresariales de consumidor para consumir mensajes de la nueva instancia de Kafka.
Compruebe que los consumidores obtienen correctamente los datos de la nueva instancia de Kafka.
Supervisión del clúster de Kafka
Puede usar los registros de Azure Monitor para analizar los registros que genera Apache Kafka en HDInsight. Para más información, consulte Análisis de registros para Apache Kafka en HDInsight.
Apache Kafka Streams API
La API de flujos de Kafka permite procesar datos casi en tiempo real y combinar y agregar datos. Para obtener más información, vea Presentación de flujos de Kafka: Procesamiento de flujos hecho simple- Confluent.
La asociación de Microsoft y Confluent
Confluent proporciona un servicio nativo en la nube para Apache Kafka. Microsoft y Confluent tienen una alianza estratégica. Para obtener más información, consulte los siguientes recursos:
- Confluent y Microsoft anuncian una alianza estratégica
- Introducción a la integración sin problemas entre Microsoft Azure y Confluent Cloud
Colaboradores
Microsoft mantiene este artículo. Los colaboradores siguientes escribieron este artículo.
Autores principales:
- Namrata Maheshwary | Arquitecto sénior de soluciones en la nube
- Raja N | Director, Éxito del cliente
- Hideo Takagi | Arquitecto de soluciones en la nube
- Ram Yerrabotu | Arquitecto sénior de soluciones en la nube
Otros colaboradores:
- Ram Baskaran | Arquitecto sénior de soluciones en la nube
- Jason Bouska | Ingeniero sénior de software
- Eugene Chung | Arquitecto sénior de soluciones en la nube
- Pawan Hosatti | Arquitecto sénior de soluciones en la nube: ingeniería
- Daman Kaur | Arquitecto de soluciones en la nube
- Danny Liu | Arquitecto sénior de soluciones en la nube: ingeniería
- José Mendez Arquitecto sénior de soluciones en la nube
- Ben Sadeghi | Especialista sénior
- Sunil Sattiraju | Arquitecto sénior de soluciones en la nube
- Amanjeet Singh | Administrador de programas principal
- Nagaraj Seeplapudur Venkatesan | Arquitecto sénior de soluciones en la nube: ingeniería
Para ver los perfiles no públicos de LinkedIn, inicie sesión en LinkedIn.
Pasos siguientes
Introducción al producto de Azure
- Introducción a Azure Data Lake Storage
- ¿Qué es Apache Spark en HDInsight?
- ¿Qué es Apache Hadoop en HDInsight?
- ¿Qué es Apache HBase en HDInsight?
- ¿Qué es Apache Kafka en HDInsight?
- Introducción a la seguridad empresarial en HDInsight
Referencia de productos de Azure
- Documentación de Microsoft Entra
- Documentación de Azure Cosmos DB
- Documentación de Azure Data Factory
- Documentación de Azure Databricks
- Documentación de Event Hubs
- Documentación de Azure Functions
- Documentación de HDInsight
- Documentación de gobernanza de datos de Microsoft Purview
- Documentación de Azure Stream Analytics